
The Essential Guide to Kubernetes Service Discovery
A fundamental element of the Kubernetes microservices system is the services model, which gives teams greater understanding of how their applications are deployed. These objects running within pods and containers, by extension, are RESTful since they’re based on APIs. However, DevOps teams can’t hope to run a tight ship without managing their services. Communication and visibility are absolutely crucial in a Kubernetes system. Accordingly, service discovery describes the process of connecting to a given service within your ecosystem.
This is trickier, however, than it sounds. Because a containerized service runs using numerous instances (or virtual copies) of itself, that service now “lives” in several locations:
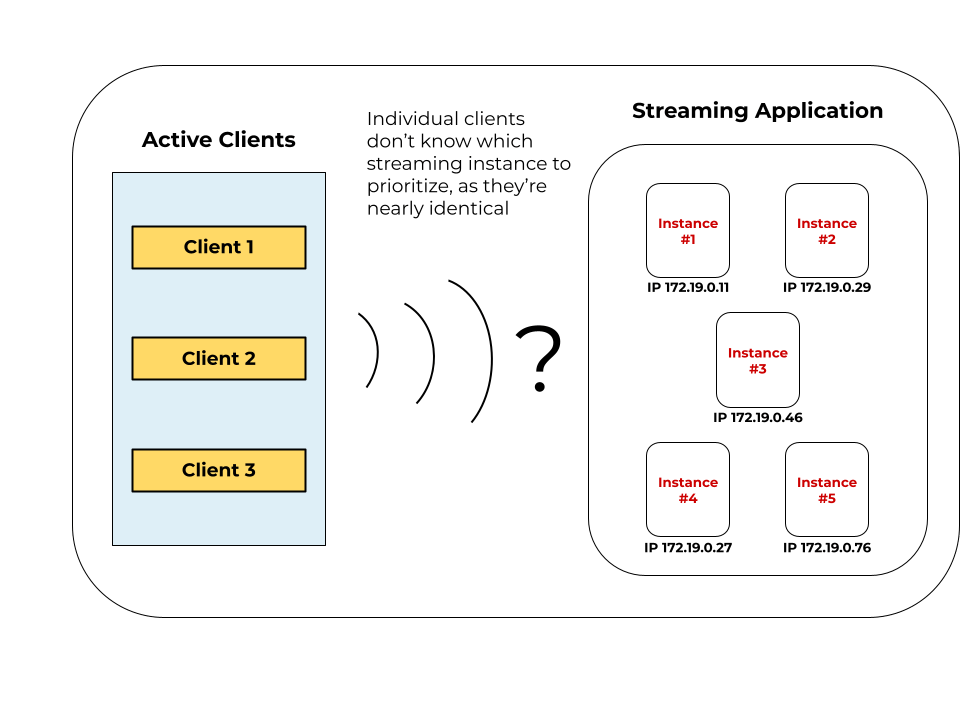
Each is essentially a network endpoint with its own port or IP address. Pointing to the correct location is therefore crucial while attempting to access that service. Familiarizing yourself with these mechanisms will make you a better Kubernetes administrator.
In this guide, we’ll explain the ins and outs of Kubernetes service discovery, and why it’s important to you.
What Is Service Discovery?
As we’ve touched on, service discovery is the process of locating a service, once it’s determined that said service is integral to completing tasks within an application. Users and admins alike make requests to containerized services on a regular basis. Furthermore, API-based microservices are known for their two-way communicability, where two or more services talk to each other during runtime. Devices do this service discovery work in the background once a request is made. What exactly is a service, then?
Technically speaking, a Kubernetes service defines a set of pods and outlines methods for accessing them during runtime. These pods are the smallest deployable objects available in the Kubernetes system and carry out core processes that make your applications function. Additionally, containers housing application-specific software packages reside within those pods. Pods thus play critical roles in giving your infrastructure purpose.
The pod lifecycle complicates service discovery a bit when it comes to deployments. Pods are scalable backends by nature. Accordingly, Kubernetes will terminate or create new pods to ensure a service remains in working order as user activity and resource consumption fluctuate. Groups of these pods are markers for your services. Each pod has both its own IP address and selector associated with it. Unfortunately, discovery requests made to pod IPs can falter since these pods might disappear at any moment. Pod IP addresses may also change unexpectedly. What happens then?
This is where the service concept comes in handy. By grouping multiple pods and instances under one collective service, Kubernetes can locate that service even if one or more pods fail. There are a few ways this can happen. First, keep in mind that Kubernetes clusters themselves have IP addresses. Additionally, service registries acting as databases exist within the system, and these catalogue instance availability on a continual basis. If one instance crashes, that event is automatically logged within the registry via the network.
How are services defined? Like many other things in Kubernetes, a YAML configuration file allows you to dictate how a service interacts with other objects on the network. Metadata and value pairs play a powerful role here.
For example, services can target specific network ports or apps with certain labels. Service proxies may use the generated IP address to communicate with it later on. These service IP addresses never change. Similarly, DNS endpoints paired with a given service will also remain the same. Services are inherently communicable and not walled off. How exactly can you discover them within Kubernetes?
How Does Service Discovery Work in Kubernetes?
Before breaking down specific processes, it’s important to understand the mechanisms that expose services to the system. There are three principal pieces that make this possible:
- ClusterIP – or the virtual IP address that represents a clustered service. This provides other objects with a means of communication throughout the service’s existence. ClusterIP services can expose their pods to the network
- NodePort – or a port used to expose services on the same port on all cluster nodes at once. Requests made via NodePort are automatically directed to predetermined destination pods
- LoadBalancer – or the component that adds Layer 4 and Layer 7 load balancers to a service, routing requests to the instances that can best handle them. Load balancers ensure that containers aren’t overwhelmed with activity while others sit idle
HTTP and SSL connections allow external entities to access these services. Additionally, multiple services often share load balancers AND endpoints. This may sound complicated, but an ingress controller allows multiple microservices to leverage the same endpoint. A load balancer will expose this network endpoint to other links in the Kubernetes chain. Likewise, both API gateways and Application Delivery Controllers (ADCs) can expose this endpoint. The API gateway itself is central to enabling user functions in an application. It facilitates access to APIs, microservices, and backends, acting as a singular entry point into the system. Meanwhile, ADCs are network devices that emulate load balancers and execute core tasks related to service availability.
There are three main service discovery methods within Kubernetes. Let’s jump into those now:
3 Kubernetes service discovery methods
1. Server-side Discovery
We know that instance IPs can change at the drop of a hat, making direct communication with services somewhat unpredictable. Conversely, it’s often more reliable to use some sort of intermediary to promote better service discovery. The load balancer fills this role perfectly.
Server-side service discovery starts with the client, which makes an initial network request. This isn’t novel in itself. However, Kubernetes will route that request to a load balancer that determines which instance is best equipped to handle it before forming a bridge. The load balancer is also a worthy target for this service request, since its IP address can remain static, or at least shuffle less often by comparison.
However, this is where the aforementioned service registry makes an appearance. A load balancer can also route requests to “bad” destinations like crashed instances without proper status updates. The registry will keep track of instance status (active, crashed, newly created) by communicating with each service instance. Next, the service registry will feed that information to the load balancer, which helps logically with its decision making. The client ultimately discovers their respective service via this background monitoring and intelligent routing.
No system is perfect, however. Load balancers are integral, and thus their failure constitutes a breakage in the discovery chain. Admins must package redundancy into these server-side processes to counteract any issues. Additionally, routing a bunch of requests through one “gateway” can create a performance bottleneck. Finally, load balancers create an extra network hurdle, since their requests are filtered according to specified communication protocols (between client and service).
2. Client-side Discovery
What if you removed the load balancer conundrum from the equation? Would service discovery improve? It’s believed that client-side discovery methods alleviate the issues present with server-side chains. There’s one less component to deal with. That means one less failure point and fewer occasions for bottlenecking. The service registry remains as a lookup database for the client, which directly polls the registry for instance status with each request. The client does much of the work by:
– grabbing a list of available instance IP addresses;
– determining which instances are viable, and choosing a best option;
– sending a request to the preferred instance and awaiting a response.
There’s added complexity here in some key ways, however. The client must be able to decode an instance’s availability. That means more integrated coding and more heavy lifting on the client side—whether that be a device or another service. Offloading that logical coding to a proxy has been discussed, but seems a dubious prospect at best.
3. DNS Discovery
Finally, the idea of DNS service discovery has actually existed for some time. It’s a unique process in which the client uncovers a list of instances via DNS PTR record, reviews a series of names in a <Service>.<Domain> format, and resolves to the domain name tied with a working instance. Additional queries can point domain names to their respective IP addresses.
However, some question whether this is complete service discovery. DNS instead resembles the service registry, and promotes the creation of either client-side or server-side solutions. Round-robin DNS may alternatively alleviate some issues through better replica abstraction. DNS discovery on the whole falters in some key ways. DNS records update very slowly. Cache layers and libraries can delay the updating process, meaning clients will be waiting on instance statuses even longer.
Service Discovery is a Specialized Process
Overall, there are many ways that you can tackle Kubernetes service discovery depending on your service’s traffic volume, your comfort level with various K8s components, and your deployment texture. These factors may determine which discovery method stands out above the rest.
The hierarchical cluster > node > pod > container structure of Kubernetes can muddy the waters when attempting to discover services. Thankfully, leveraging each component’s unique address and a little ingenuity helps immensely when exposing services to clients.



It’s Really not that Complicated.
You can actually understand what’s going on inside your live applications.