
How a Runtime Aware AI SRE Agent Transforms System Reliability
Mar 24, 2026 / Updated: May 14, 2026


A runtime aware AI SRE extends existing AI SRE approaches by moving beyond telemetry correlation into runtime-validated reliability. While the majority of AI SRE tools accelerate incident triage using logs, metrics, and traces, they cannot confirm execution behavior if critical runtime signals were never captured. By generating on-demand evidence inside running services, AI SRES can eliminate slow redeploy cycles, ensuring your distributed systems remain resilient under real-world traffic conditions.
TL;DR
- AI SRE tools accelerate incident triage by correlating logs, metrics, traces, and deployment changes, but remain constrained by pre-captured telemetry.
- Correlation alone cannot confirm which execution path, variable state, or dependency interaction actually caused a failure under real traffic conditions.
- As AI accelerated software delivery in 2025–2026, the reliability bottleneck shifted from detection to runtime validation, driving the emergence of AI SRE Agents.
- A runtime aware AI SRE extends reliability workflows by generating precise evidence on demand inside running services, enabling execution-level validation without redeployments.
- When runtime validation operates under read-only enforcement, auditability, and enterprise governance, AI can participate safely across both incident response and development workflows.
Modern reliability is no longer limited by detection speed, but by validation certainty. As AI becomes embedded in engineering workflows, the critical question has shifted from whether AI can assist investigations to whether it can participate safely in runtime reliability decisions.
This article examines what distinguishes an AI SRE from a runtime aware AI SRE Agent, why runtime context is the foundation of trustworthy AI, and how Lightrun operationalizes this model across both development and live production environments.
How AI Agents Are Changing Reliability Engineering
Software development has entered an AI-native era. Code generation is faster, review cycles are shorter, and deployment velocity continues to increase across distributed systems.
Many failures emerge under real traffic, real data, and complex dependency interactions that staging environments cannot fully reproduce. Reliability is increasingly constrained by confirmation certainty rather than detection speed. The bottleneck has shifted from writing software to validating its behavior in production.
This challenge is widely recognized in modern Site Reliability Engineering practices. The Google Site Reliability Engineering framework highlights how diagnosing incidents in distributed systems requires understanding real system behavior across services, dependencies, and runtime conditions.
To solve this challenge, a raft of AI SRE (site reliability engineering) tools have been developed. They speed incident triage, assist in root cause analysis, and propose potential remediation at scale, but they can only offer advisory support.
What is A Runtime Aware AI SRE and How is it Different?
AI SRE systems emerged to accelerate reliability workflows by mapping and reasoning over telemetry, signals from infrastructure, codebase, and knowledge bases across distributed services. They ingest logs, metrics, traces, deployment history, and configuration changes to identify probable fault domains.
These AI tools significantly reduce triage time but remain bounded by the limits of pre-captured signals. When diagnostic data was not captured, they require human engineers to manually add new telemetry and deploy new changes to capture diagnostic signals. This can lead teams using these new AI SREs to get caught in the same rollback-redeploy cycles that human engineers faced prior to AI integration.
Take this example.
A team needs to understand why system latency has increased after a configuration update. Using an AI SRE, they can correlate the anomaly to a recent release and narrow the likely fault domain.
However, they cannot confirm whether a specific execution branch was triggered or whether a downstream dependency responded differently under live traffic. For this, they must still roll back the change, add additional telemetry, and then redeploy.
A runtime aware AI SRE Agent is an architectural evolution. Rather than operating over static, pre-captured telemetry, it connects AI reasoning directly to the live runtime context.
It does not stop at providing likely hypotheses; it generates missing execution evidence on demand to validate behavior within running services and operates within governed production boundaries.
Injecting instrumentation at the failure site, it can prove the hypothesis, allowing the team to move on to remediation.
This shift requires more than smarter analysis. It requires an architecture that safely connects AI reasoning, runtime instrumentation, governance, and SDLC workflows into a unified reliability model.
In Lightrun, this model is enabled through the Lightrun Sandbox, where engineers and AI systems can observe live production behavior without modifying code or redeploying services. Within this read-only environment, dynamic telemetry such as logs, snapshots, and runtime metrics can be generated on demand, revealing variable values, execution paths, and branch conditions under real traffic. This allows teams to investigate incidents and validate fixes directly against live runtime behavior without impacting users.
Why is “Runtime Truth” the New Standard for Trustworthy AI?
Runtime truth does not imply full memory dumps, deterministic replay, or exhaustive state capture. It refers to targeted, execution-time inspection of live services under real traffic conditions.
Instead of sampling telemetry or inferring behavior from aggregated metrics, runtime truth enables selective capture of variable state, conditional branches, and dependency responses at the exact point of execution. Instrumentation is applied dynamically and scoped precisely, avoiding changes to control flow or mutation of application state.
This model prioritizes fidelity over volume. It captures the specific runtime context required to validate a hypothesis, rather than attempting to record the entire system state.
What Makes a Runtime Aware AI SRE Uniquely Production-Ready?
If AI SREs are to move from assistance to operational participation, they must operate under a new standard.
Consider a distributed checkout system where intermittent failures occur only during peak traffic. A telemetry-driven system may correlate the spike with a recent deployment and suggest a likely regression.
A production-grade AI SRE Agent must go beyond analyzing existing data. It should be able to verify whether the suspected execution path actually triggered under real traffic, inspect the variable state in real time, and confirm whether downstream dependencies behaved as expected. The difference is not faster correlation, but the ability to provide confirmation.
To operate safely in production environments, a trustworthy AI SRE Agent must:
- Validate conclusions against live execution paths and runtime state
- Generate missing evidence on demand without redeployments
- Eliminate redeploy-driven validation cycles
- Operate under read-only enforcement and auditability
- Preserve human authority over remediation decisions
These requirements define the architectural foundation of a production-grade AI SRE Agent, one built on runtime truth rather than probabilistic inference.
The Architecture Behind a Runtime Aware AI SRE
A runtime aware AI SRE is defined by architectural extension.
In large-scale distributed environments such as financial trading platforms, multi-region SaaS applications, or regulated payment systems, AI-powered incident workflows need to extend beyond detection.
Teams must confirm which execution branch triggered under live traffic, validate dependency behavior across services, route alerts to the correct ownership group, and produce auditable root cause documentation. While correlation narrows the possibilities for root cause, only execution-level confirmation will accelerate resolution.
To support these enterprise demands, an AI SRE Agent architecture must enable:
- Runtime-verified root cause confirmation across distributed services
- Intelligent alert triage in multi-service and multi-team environments
- Dynamic instrumentation for unknown or previously uncaptured runtime conditions
- Safe remediation validation under governance and audit controls
- Continuous feedback of runtime insights into development workflows
The architecture below illustrates how a runtime aware AI SRE operationalizes these requirements end-to-end.
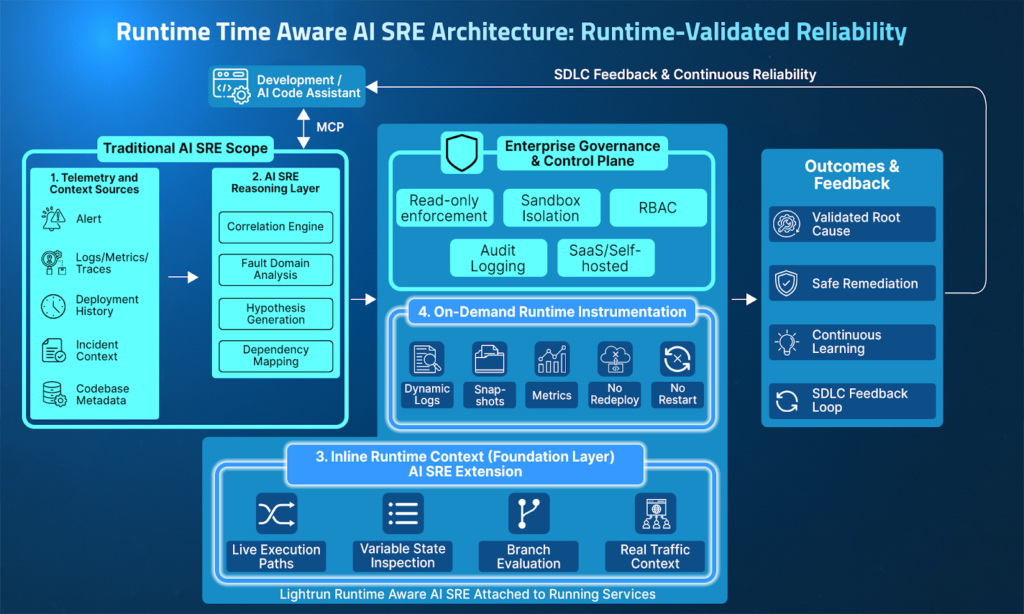
A runtime aware AI SRE integrates several coordinated layers that connect telemetry, AI reasoning, and runtime observability into a unified reliability workflow.
- Telemetry & Context Ingestion: Aggregates alerts, logs, metrics, traces, deployment history, and incident metadata to establish investigative context across distributed services.
- AI SRE Reasoning Layer: Correlates cross-service signals, analyzes change impact and dependencies, narrows fault domains, and generates structured hypotheses for investigation.
- Inline Runtime Context: Provides live visibility into execution paths, variable state, conditional logic, and dependency behavior inside running services under real traffic.
- On-Demand Runtime Instrumentation: Generates missing execution evidence through dynamic logs, conditional snapshots, and runtime metrics without redeployments or service restarts.
- Governance & Enterprise Control Plane: Enforces read-only interaction, sandbox isolation, role-based access control, auditability, and deployment flexibility across SaaS or self-hosted environments.
- Outcomes & Continuous Feedback: Produces validated root causes, enables safer remediation decisions, reduces redeploy cycles, and feeds runtime insights back into development workflows via MCP.
Traditional AI SRE systems accelerate correlation across existing telemetry sources to generate plausible hypotheses. However, without runtime context, these conclusions remain inference-based.
A runtime-aware AI SRE agent extends this model by grounding investigation in the runtime context. After narrowing the suspected fault domain, it generates missing execution evidence directly inside the running service, allowing engineers to inspect variable state, conditional logic, and dependency behavior under real traffic without restarting the system.
In practice, the distinction is straightforward:
- AI SRE narrows the search space using existing telemetry.
- Runtime-aware AI SRE verifies execution using live runtime evidence.
The difference becomes clearer when viewed across operational dimensions.
| Dimension | AI SRE | Runtime-aware AI SRE |
| Investigation Scope | Works on existing telemetry | Generates new runtime evidence |
| Fault Isolation | Identifies likely faulty service or deployment | Confirms the exact execution path and state |
| Evidence Source | Pre-captured logs, metrics, traces, codebase, and infrastructure context | On-demand dynamic logs, snapshots, runtime metrics, plus codebase and infrastructure context |
| Validation Method | Requires redeployment if the signal is missing | Validates inside a sandboxed running service without a restart |
| Dependency Visibility | Indirect via traces | Direct inspection under real traffic |
| RCA Output | Inferred root cause summary | Execution-backed, auditable confirmation |
Investigating Production Incidents with Runtime-Grounded AI
The concept of runtime-grounded AI becomes much clearer when examined through a real production investigation.
Lightrun’s AI SRE introduces a fundamentally different model. Rather than depending solely on historical telemetry, the platform combines AI-assisted investigation with live runtime context, enabling engineers to generate the exact execution signals required to validate a hypothesis.
Engineers interact with the system through a conversational interface while the platform continuously correlates signals across logs, deployments, observability data, and the application’s source code.
This allows investigations to move beyond guesswork and instead rely on verifiable runtime evidence.
Example Scenario: Investigating Failed Trade Validation
Consider a trading platform that processes thousands of buy and sell orders every second. During a period of peak activity, monitoring systems begin reporting a sudden spike in fraud validation failures for high-value trades. Although alerts clearly indicate that the issue started shortly after a recent deployment, the available observability signals do not reveal the underlying cause.
System dashboards show that validation failures have increased significantly, and logs confirm that requests are reaching the validation service. However, the application does not produce exceptions or error messages that would explain the behavior. Distributed traces show the request flow completes successfully, suggesting the system is operating normally from a technical standpoint.
Despite the growing number of failed validations, the available telemetry provides no direct explanation of what is actually happening inside the validation logic.
At this point, the on-call team opens the incident investigation in Lightrun AI SRE.
Step 1: Starting the Investigation with the AI Assistant
Instead of manually searching across multiple observability tools, engineers begin by asking Lightrun AI SRE a simple question within the investigation interface:
“Why are high-value trade validations failing after the latest deployment?”
The AI assistant immediately begins correlating available signals across the system. This includes application logs, recent deployments, operational alerts, service dependencies, and relevant portions of the application’s source code retrieved from the connected GitHub repository.
By analyzing these signals together, Lightrun AI SRE identifies the services and workflows most likely involved in the validation failure and presents a structured view of the incident investigation.
This process significantly reduces the scope of the problem space. Instead of manually examining multiple services and dashboards, engineers can immediately focus on the specific service responsible for transaction validation.

Step 2: Correlating Code, Deployments, and Operational Signals
Once the investigation is underway, Lightrun AI SRE analyzes the validation service in the context of recent deployments and historical behavior. By examining code changes and operational signals together, the system identifies a potential fault domain inside the logic responsible for classifying transactions as high-value.
At the same time, the AI correlates this suspected code path with operational signals observed during the incident window. Traffic patterns indicate that the spike in validation failures coincides with increased transaction volume, and request traces confirm that the validation workflow is consistently executing during these failed transactions.
Although the system continues to process requests successfully, the correlation analysis strongly suggests that the issue originates from a specific validation branch within the transaction processing logic.

Step 3: Generating Missing Runtime Evidence
Even after correlating logs, traces, and deployment changes, a critical question remains unanswered: which values are actually evaluated by the validation logic at runtime?
Traditional observability platforms cannot answer this question because the required telemetry was never captured. In a conventional workflow, engineers would typically add new logging statements, redeploy the service, and wait for the issue to occur again.
Instead, Lightrun AI SRE recommends generating the missing runtime signals directly inside the running service. The system proposes capturing variable values and execution conditions within the validation method, so engineers can observe the system’s exact state as it processes real transactions.
For example, the investigation may capture the transaction amount being evaluated, the condition used to determine whether the trade exceeds the high-value threshold, and the exact branch of the validation logic that executes during each request.
Because this instrumentation is applied dynamically, it does not require modifications to the source code or a service restart.
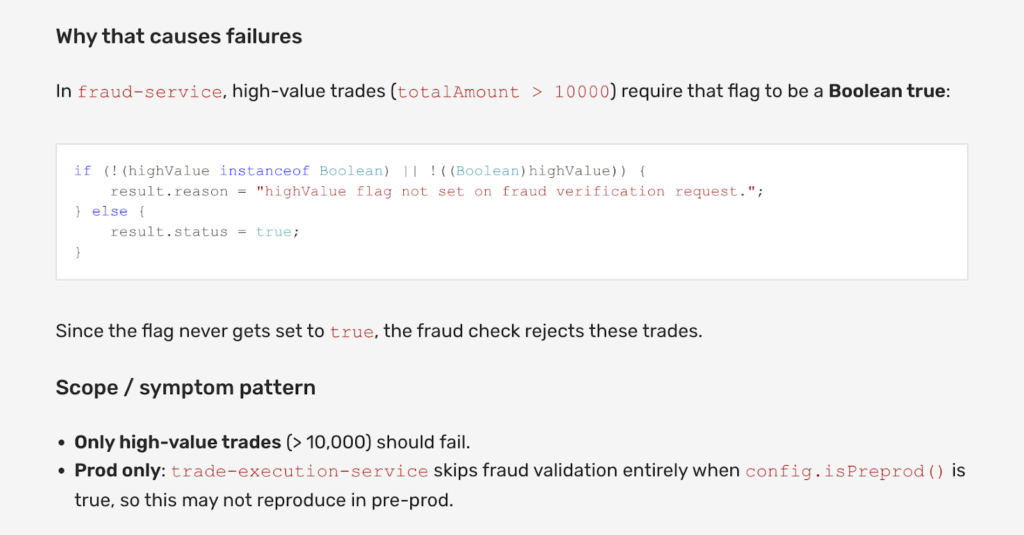
Lightrun AI SRE’s recommendation for capturing runtime context in the validation workflow.
Step 4: Observing Runtime Behavior Under Real Traffic
As the system continues processing transactions, the newly generated runtime signals begin capturing execution data from the validation workflow. This runtime context quickly reveals the underlying problem.
A recent deployment introduced a subtle type mismatch in the transaction value field. The validation logic expects a numeric value to compare against the high-value threshold, but the upstream service now passes the value as a string. Because of this mismatch, the threshold comparison silently fails, preventing the high-value validation flag from being triggered.
Since this condition does not produce an exception or runtime error, the system continues processing requests normally. However, the fraud validation logic behaves incorrectly, which explains the sudden spike in failed validations observed by the monitoring system.
Without access to runtime variable values and execution paths, the issue would remain invisible to traditional logs and metrics.

Step 5: Fixing and Validating the Issue
Once the root cause is confirmed, engineers update the validation logic to ensure that the transaction value is properly converted before the threshold comparison occurs. The team then continues observing runtime signals to confirm that the validation workflow behaves correctly under live traffic.
Throughout the investigation, all instrumentation remains read-only and does not alter application behavior. The system never mutates application state or changes control flow, and every investigative action remains fully auditable.
This allows teams to confirm fixes under real production conditions while maintaining strict operational safety.
Why Are Runtime-Aware AI SREs So Important?
Traditional observability systems rely entirely on telemetry configured before an incident occurs. When the signal needed to explain a failure is missing, engineers must redeploy code or wait for another failure to capture it.
Runtime-aware AI changes this model by enabling teams to generate the exact execution signals required to answer a question, directly inside running systems. Instead of relying on incomplete historical telemetry, investigations can be grounded in real execution behavior.
This shift transforms AI from a tool that merely suggests potential causes into one that can validate root causes using live runtime evidence.
How an AI SRE Agent Operates Across the SDLC
The trading walkthrough illustrates how a runtime aware AI SRE operates during live incident workflows. However, runtime-grounded reliability should not begin only when something fails. The same execution-level visibility that enables validation during incidents can also inform engineering decisions before code reaches production.
Modern development workflows increasingly rely on AI code assistants to generate, refactor, and optimize logic. Without runtime awareness, these assistants reason only over static code and inferred telemetry.
Through Lightrun MCP, runtime context becomes available during build-time workflows, allowing AI-generated changes to be evaluated against real execution patterns observed in running services.
For example, when updating trade validation logic, an AI assistant may suggest modifying how thresholds are handled or how flags are propagated. With runtime context available through MCP, engineers can verify how similar execution branches behave under real traffic conditions before merging changes. This shifts validation earlier in the lifecycle and reduces the likelihood of production-only regressions.
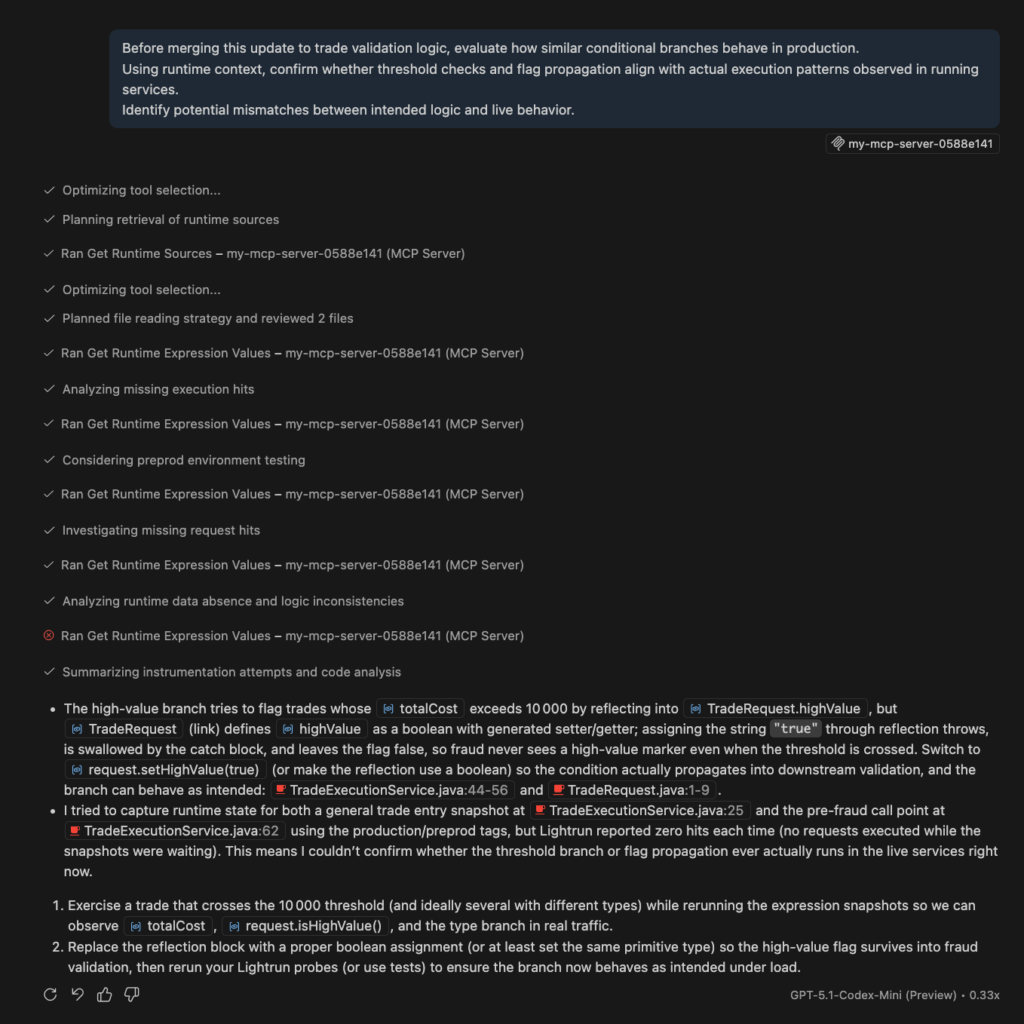
Runtime context, therefore, becomes a shared foundation across environments:
- During development, MCP informs AI-assisted code generation with execution-aware reasoning.
- During runtime, AI SRE workflows generate and validate live evidence to confirm root causes.
- Across both phases, governance and read-only enforcement preserve operational safety.
This continuity transforms reliability from reactive troubleshooting into a continuous engineering discipline grounded in execution truth.
Why Governance Defines the Future of AI SRE Agents
As AI systems begin participating in reliability workflows, governance becomes the defining boundary between acceleration and risk. Production environments handle financial transactions, regulated data, and mission-critical workloads. In these contexts, automation without control is not innovation; it is liability.
An AI SRE must operate within explicit safeguards. Runtime inspection must remain read-only. Instrumentation must not mutate application state or alter control flow. Every action, whether suggested by AI or approved by an engineer, must be inspectable and auditable.
Participation in production reliability workflows requires architectural enforcement, not policy alone. Platforms such as Lightrun enforce these safeguards through sandboxed runtime instrumentation and structured access controls.
This is where governance separates AI assistance from AI participation. An assistant may suggest probable causes, but a runtime-aware AI SRE interacts with live systems.
That interaction must be bounded by sandbox enforcement, role-based access control, and full auditability. Engineers retain authority over remediation decisions, while AI accelerates reasoning and validation. When runtime truth is combined with enterprise safeguards, AI becomes a governed operational participant rather than an uncontrolled automation layer.
AI SRE vs Runtime Aware AI SRE Agent: What’s the Difference?
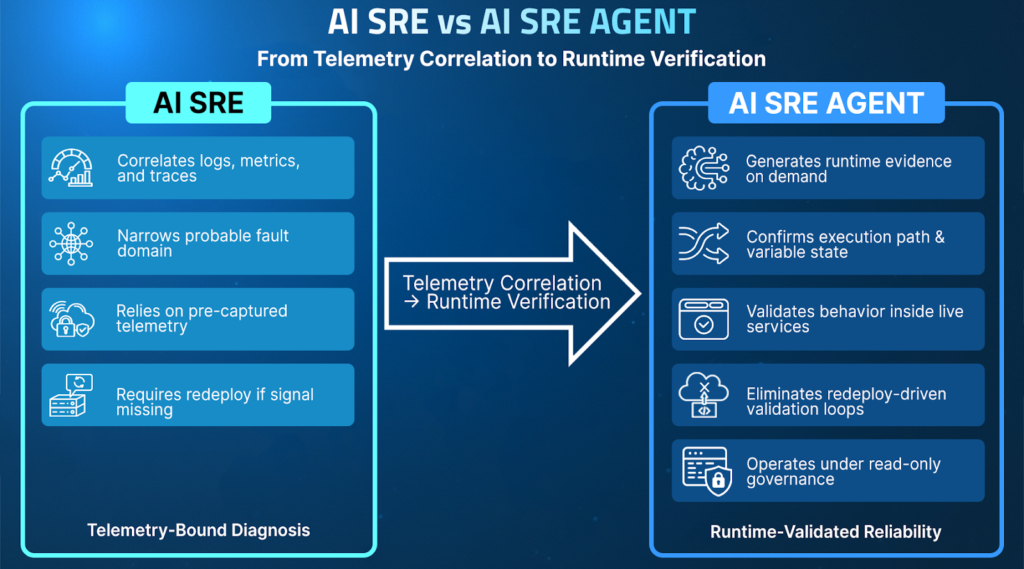
The architecture above shows how runtime context extends traditional AI SRE capabilities. The difference becomes clear during an active incident.
AI SRE systems operate at the telemetry layer. They analyze logs, metrics, traces, alerts, and deployment metadata to accelerate triage. When an SLO breach occurs, they correlate anomalies with recent releases or configuration changes to determine where to begin the investigation. But if the execution path or variable state that caused the issue was never captured, AI SRE cannot confirm what was actually executed. Engineers must add instrumentation and redeploy to validate the hypothesis.
The shift to a runtime aware AI SREs is operational rather than semantic. While most AI SREs accelerate hypothesis formation by working within the boundaries of preexisting evidence. A runtime aware AI SRE agent reduces time to confirmed resolution by grounding those hypotheses in execution-level evidence. The difference lies in where and how validation is performed.
Conclusion
Modern reliability is no longer constrained by the speed at which incidents are detected. It is constrained by how confidently teams can confirm what actually happened.
A runtime AI SRE agent is the solution. By generating missing runtime evidence within running services and validating execution paths under real traffic, it confirms behavior observed in the runtime itself. The architectural model, runtime walkthrough, and SDLC integration explored here all point to the same shift: reliability improves when validation no longer depends on redeploy cycles.
The distinction, ultimately, is practical. AI SRE accelerates team hypothesis formation. A runtime aware AI SRE Agent improves how quickly they confirm them. When AI reasoning is grounded in live execution behavior and enforced through governed, read-only controls, reliability becomes measurable, defensible, and continuous. That is the operational foundation of AI-native engineering reliability.
FAQs about Runtime Aware AI SREs
An AI SRE Agent is a runtime-aware reliability system that extends traditional AI SRE by generating execution-level evidence inside running services. Unlike telemetry-driven AI tools that rely solely on pre-captured logs and metrics, an AI SRE Agent validates root causes against live execution behavior and operates within governed production safeguards.
AI SRE primarily accelerates alert correlation and hypothesis generation using existing telemetry. An AI SRE Agent goes further by participating in validation workflows, generating missing runtime evidence on demand, inspecting execution paths, and confirming causality before remediation decisions are made. The difference is between correlation-based participation and runtime-validated participation.
Most production failures depend on specific execution paths, variable state, or dependency behavior that may not be captured in predefined logs or traces. Runtime context provides direct visibility into how code behaves under real traffic conditions, allowing AI systems to confirm what actually executed rather than inferring from incomplete signals.
MCP enables AI code assistants to reason about the behavior of live execution during build-time workflows. By supplying runtime context to development tools, engineers can validate conditional logic and state propagation before merging changes, reducing production-only regressions and shifting reliability earlier in the lifecycle.
Lightrun enforces read-only runtime instrumentation through sandboxed controls, preventing mutation of application state or changes to control flow. All actions are auditable and governed through structured access controls, ensuring that AI participates in reliability workflows without introducing operational risk.


