The only AI SRE that
creates runtime evidence
Lightrun AI SRE delivers faster, more accurate triage, root-cause analysis, fix suggestion,
and change validation, all without a single redeployment.
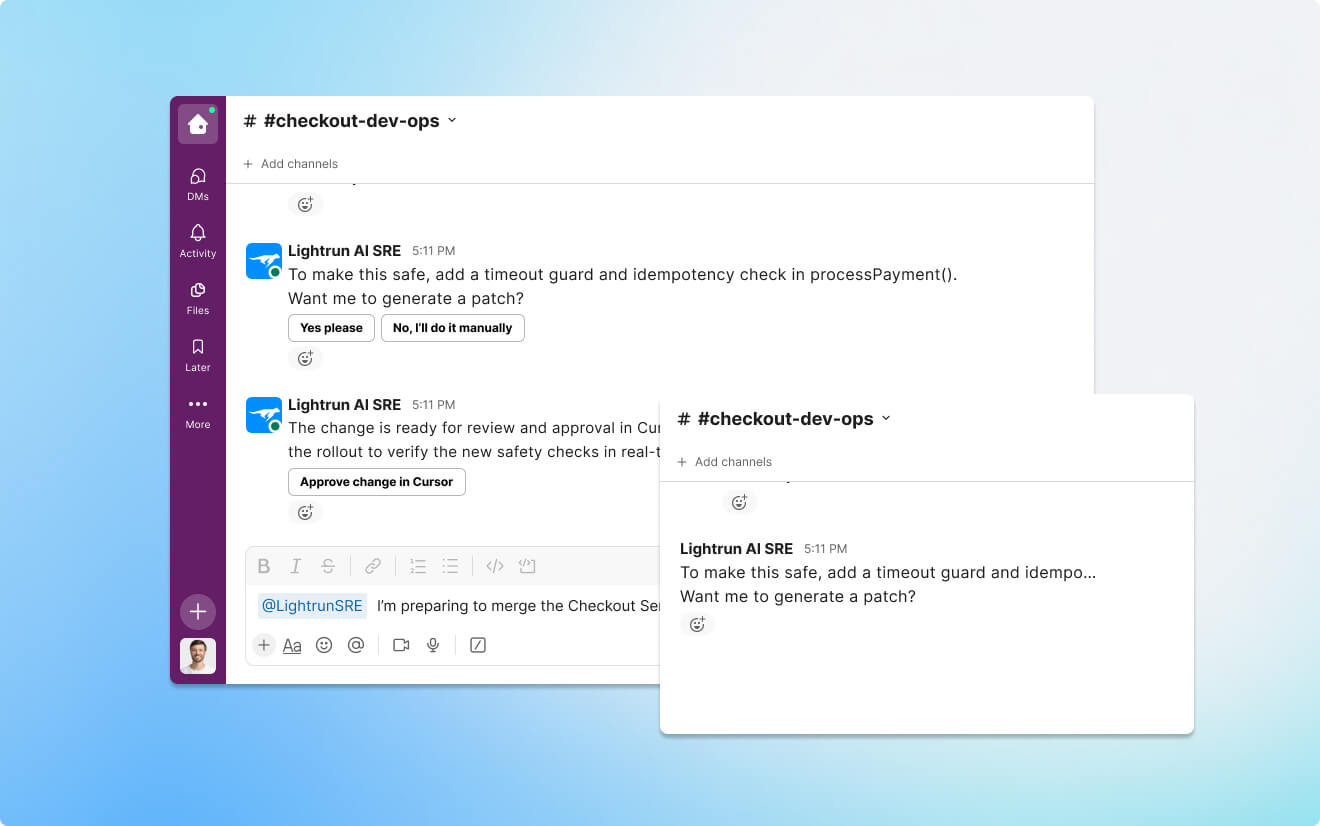
Trust your AI SRE assistant
Every decision is
based on evidence
Each diagnosis and fix suggestion is validated with runtime proof, rather than probability-based inferences.
Issues are resolved
fast and accurately
Cut MTTR without risking blast radius increase by getting clear explanations of behavior, and what remediation is safe.
Engineers stay focused
on high-impact work
Reduce engineer toil and reproductions with real-time AI-led investigations, all without removing human control.
Surgical, real-time site reliability engineering
Every diagnosis and fix proposal is evidence-based and verified against live runtime behavior.
Understand complex system architecture
Lightrun maps shifting microservices, complex dependencies and runtime behaviors that are not captured in docs or static diagrams with dynamic telemetry injected into running code.
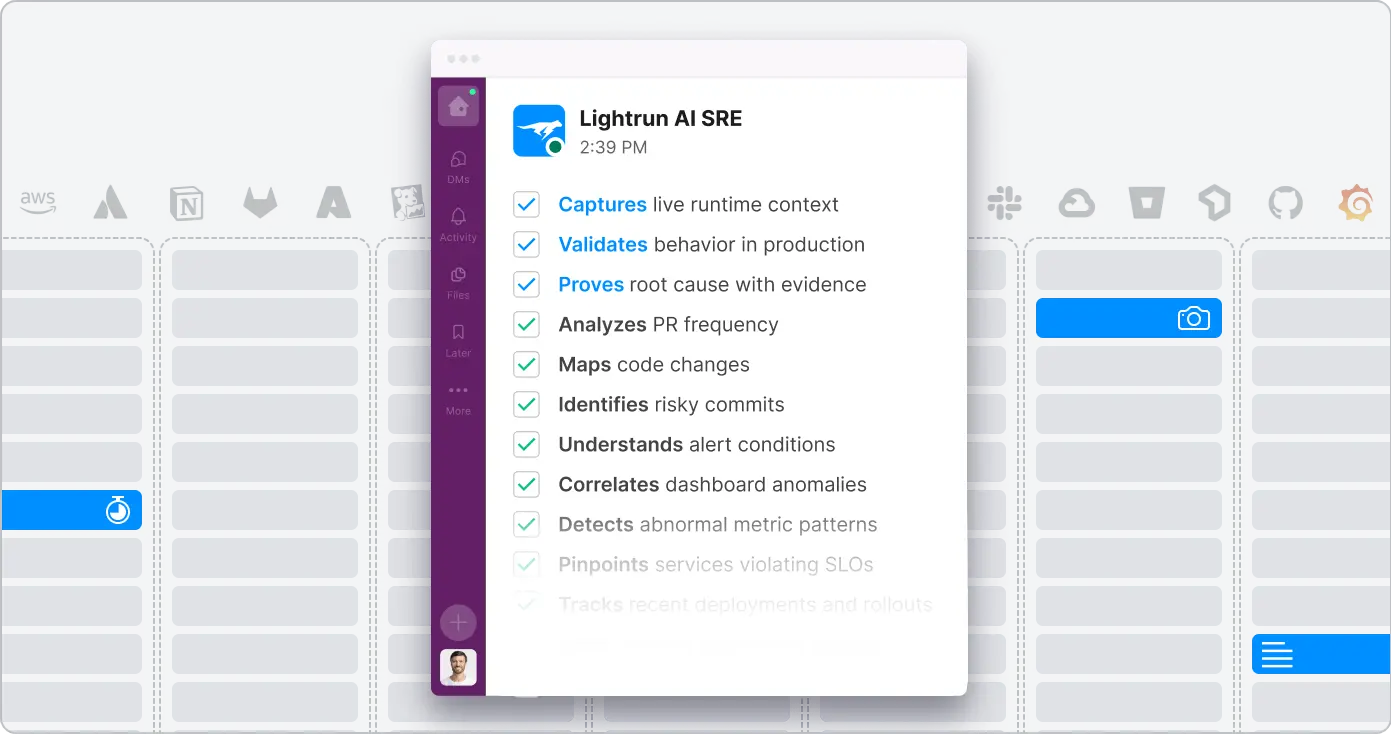
Triage emerging issues before they cause incidents
Lightrun detects production errors and performance degradations and correlates these service-level issues with proven root causes to propose resolutions.
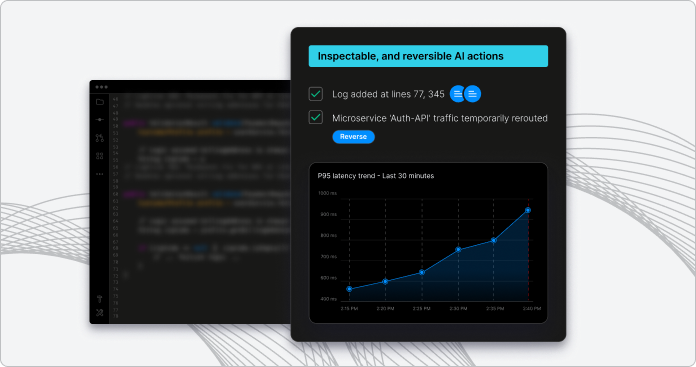
Prove root causes with live runtime evidence
When an incident fires, Lightrun AI SRE injects dynamic logs and snapshots to fill gaps in static telemetry, replacing AI guesswork with runtime proof.
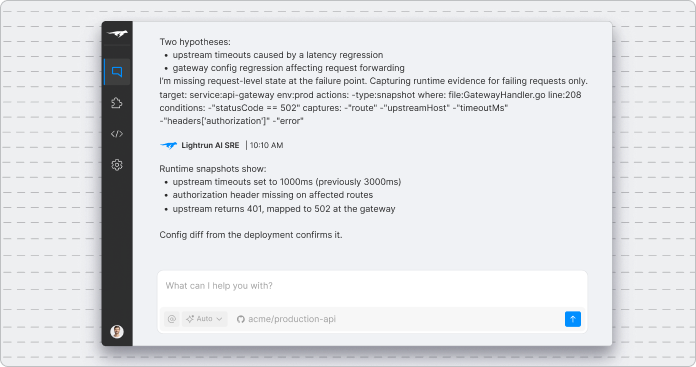
Validate fix proposals against remote environments
Lightrun uses the defined root causes to offer verified fixes that consider full system architecture. Every proposal is shared with a verifiable chain of thought to ensure trust.
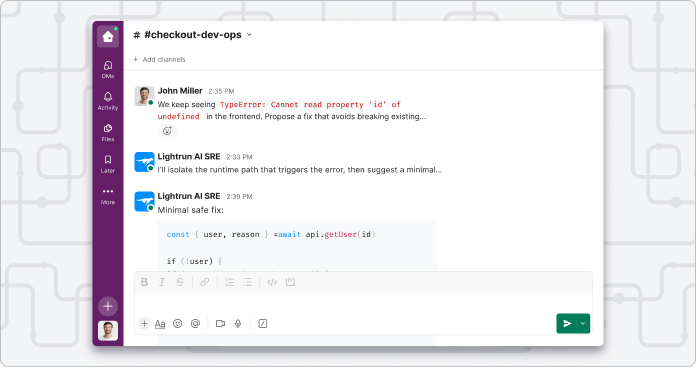
Generate postmortems to improve future incident resolution
Lightrun shares a postmortem for each event. It details the timeline, root cause, and follow-ups and the successful resolution strategy to learn and improve.
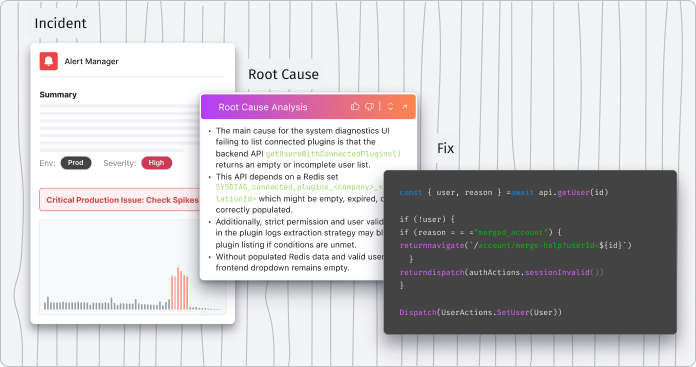
How Lightrun accelerates incident resolution across the entire lifecycle
From detection to post-mortem, Lightrun gives every team real-time production insight at every stage of incident resolution.
Detection & Intake
Support Tier 1, Monitoring Systems, Customer Success Validate the problem and classify impact
- What is the customer experiencing?
- Is this reproducible?
- What is the impact — users, region, tenant?
- When did the issue start?
- Is this a known issue?
- Does this affect SLAs or strategic accounts?
- Did error rate or latency exceed SLO thresholds?
- Capture additional telemetry on demand
- Enrich incident context with live production data
- Reduce time to actionable signal before escalation
Triage & Assignment
Support Tier 2, SRE On call, Incident Manager Confirm severity and route to correct team
- Which subsystem is failing?
- Can logs give a quick clue?
- Is this similar to previous incidents?
- Which services are involved?
- Is production healthy overall?
- Is rollback needed immediately?
- Infrastructure or application issue?
- Is severity correct?
- Which team should own this?
- Do we need a bridge call?
- Inspect live services without redeploying
- Identify failing services and code paths immediately
- Support rollback planning with real time runtime insight
Containment & Immediate Mitigation
SRE, Dev On call, Incident Commander Stop customer impact quickly
- Should we fail over or scale?
- Is config change safe?
- Disable faulty feature flag?
- Which code paths are involved?
- Caused by recent deployment?
- Can we hotfix or revert safely?
- Fastest reversible action?
- ETA for mitigation?
- Inspect live code paths safely
- Validate deployment regressions
- Verify mitigation effectiveness immediately
Root Cause Investigation
Dev Team, SRE, QA, Incident Manager Identify precise fault
- Which commit introduced regression?
- Logs trace to specific module?
- Can we replicate in staging?
- Correlated with infrastructure instability?
- Config drift or resource constraints?
- Why did tests not catch this?
- Can we confirm root cause?
- Identify exact code pathways
- Narrow root cause to line level
- Capture dynamic logs without redeploy
Permanent Fix & Validation
Dev Team, QA, Release Engineering Deliver long term fix
- Minimal safe change?
- Need refactoring or guardrails?
- Any regressions?
- Need new tests?
- Safe to deploy now?
- Validate fix in real runtime scenarios
- Confirm assumptions before rollout
- Reduce guesswork in refactoring
Deployment & Monitoring
SRE, Dev, Release Engineering Release fix and ensure stability
- Is error rate decreasing?
- Any abnormal metrics?
- Functionality behaving normally?
- Can we close incident?
- Inject temporary telemetry to validate stability
- Confirm fix success dynamically
- Remove instrumentation once stable
Post Incident Review
Dev Lead, SRE Lead, Product Manager, Incident Manager Prevent recurrence
- Why was bug introduced?
- Process gaps?
- Were alerts sufficient?
- Missing requirements or feature risks?
- What action items?
- Who owns each task?
- Provide runtime evidence for post mortem
- Identify telemetry gaps
- Convert insights into preventive guardrails
AI SRE that sees everything
Powered by Lightrun’s Inline Runtime Context engine, instrumenting what AI cannot see

Security And Privacy
Securely supporting the largest companies in the world across regulated industries
ISO 27001 and SOC 2 Type II certified with GDPR and HIPAA alignment. Full RBAC, SSO, and audit logging.
Read-only execution with instrumentation isolation, without impact on production.
TLS 1.3 in transit and AES-256 encryption at rest, backed by AWS KMS with annual key rotation.


Read-only integrations with least-privilege access. Customer data is never modified.

Configurable retention, PII redaction, prompt sanitization, and zero data retention with AI providers.
No source code storage, no model training on customer data, and strict execution guardrails.
Logical tenant separation, dedicated secret storage & fully isolated AI sandboxes.
“The unique solutions that Lightrun is developing dramatically impact how developers operate.”
Siris Singh, Global Head of Markets Strategic Investments
AT&T reduced Time to Resolve incidents from
5 hours to 30 minutes avoiding costly war rooms
“When it comes to priority-one tickets, customers can’t wait days for a fix. Lightrun helps us reduce that to hours, that’s a huge win for us and for our customers.”
Hood Munaim SVP, Head of Product Engineering
Priceline increased developer productivity
by 30% across workflows over 2000+ services
“Lightrun not only saved us days, if not weeks, of painstaking debugging but provided an efficient approach to tackling complex issues in production.” Tomer Glicksman, SalesForce
Taboola reclaimed 260+ hours of monthly engineering
capacity by eliminating manual reproduction
Inditex engineers used Lightrun’s live, dynamic logs and snapshots directly from their IDE to dig into a critical production issue and uncover a rounding bug quickly.
Drata accelerated incident response velocity by 30% while maintaining strict compliance standards.
Works with your tool stack
100+ integrations, and native agents for JVM, Node.js, Python, and Go connect directly to your IDEs, pipelines, and cloud environments.




