
Top 6 AI SRE Tools and Why Runtime-Grounded Reliability Is the New Standard
Apr 13, 2026


AI SRE tools accelerate incident detection, root cause analysis, and remediation across distributed production systems. They ingest telemetry signals, including logs, metrics, traces, alerts, and deployment history, to correlate anomalies, narrow fault domains, and reduce manual triage. This guide breaks down the top AI SRE tools in 2026 and helps you choose the right one based on your team’s biggest bottleneck, whether that is faster triage, deeper root cause analysis, or runtime-level validation. For organizations operating in complex, high-velocity environments, these tools mark a shift from reactive firefighting to AI-assisted reliability engineering.
TL;DR
- AI SRE tools accelerate incident triage by correlating logs, metrics, traces, and deployment changes across distributed systems.
- Most AI SRE tools are bound by pre-captured telemetry, meaning if the right signal was never collected, the AI cannot confirm what actually happened.
- The gap between correlation and confirmation is where most incident resolution time is lost.
- Runtime-grounded AI SRE goes further by generating missing execution evidence on demand, directly inside running services, without redeployments.
- Lightrun is the only AI SRE platform built on live runtime context, giving engineering teams execution-level validation rather than inference-based hypothesis generation.
Quick Pick: Which AI SRE Tool Is Right for You?
Not every team has the same bottleneck. Here is a fast decision guide before diving into the full breakdown.
| If your main need is… | Best pick |
| Ability to provide evidence of traces of variables at the point of failure | Lightrun |
| Structured incident coordination and runbook automation | Rootly |
| Full-stack anomaly correlation at enterprise scale | Dynatrace Davis AI |
| Autonomous AI investigation inside your existing Datadog stack | Datadog Bits AI SRE |
| Parallel hypothesis testing with automated code fix generation | Resolve AI |
| Self-learning investigation that improves with every incident | Cleric |
| Ability to verify the AI-suggested fix before deployment | Lightrun |

AI SRE tools have fundamentally changed how engineering teams respond to production incidents, but most of them hit a ceiling. They can narrow the probable cause using pre-captured telemetry, but they cannot confirm what actually executed inside a running service.
This gap is not theoretical, and according to Lightrun’s State of AI-Powered Engineering 2026 report, 44% of AI SRE and APM failures in production incidents are caused by missing execution-level data that was never collected.
That gap between correlation and confirmed root cause is where incident resolution time is still being lost, and it is the problem this post addresses directly.
This blog covers the top six AI SRE tools engineering teams are using in 2026, what each does well, and where each falls short. It identifies why runtime-grounded reliability is becoming the next standard for engineering teams operating at scale.
What to Look for in AI Site Reliability Engineering Tools
Not every AI SRE tool is built for the same problem. Some are optimized for reducing alert noise. Others focus on hypothesis generation, autonomous remediation, or the capture of institutional knowledge. Before evaluating options, engineering teams need clarity on where their biggest reliability bottleneck actually sits.
When evaluating AI site reliability engineering tools, the key criteria to consider are:
- Investigation depth: Does it correlate signals or validate execution behavior?
- Evidence generation: Can it generate missing telemetry on demand, or is it bounded by pre-captured signals?
- Integration breadth: Does it work with your existing observability stack without requiring a rip-and-replace?
- Governance and auditability: Are all AI actions inspectable, auditable, and reversible for regulated environments?
- Human control: Does the AI assist and accelerate, or does it operate autonomously without engineer oversight?
How We Evaluated These Tools
We evaluated each tool the way a skeptical SRE would, by stress-testing vendor claims against real production scenarios rather than relying on marketing pages or feature checklists.
- Investigation depth: We looked at whether each tool could explain why something broke, not just flag that it did. Tools that surface symptoms without tracing to a confirmed root cause scored lower regardless of how polished the interface appeared.
- Evidence generation: Can the tool produce missing signals on demand, or is it permanently bound by what was captured before the incident fired?
- Autonomy honesty: Several tools in this space market autonomous remediation but require significant manual setup before delivering on that promise. We noted this gap where we found it.
- Integration realism: A tool that requires months of instrumentation before delivering value has a real cost that does not show up in the product demo. We asked what Day 1 actually looks like for each platform.
- Governance fit: For enterprises operating under PCI-DSS, SOC 2, or HIPAA, auditability is a hard requirement, not an optional feature. We assessed each tool’s compliance posture accordingly
With those criteria as the filter, here are the six tools that stood out in 2026, what each does well, where each falls short, and which teams each is actually built for.
The Top 6 AI SRE Tools in 2026
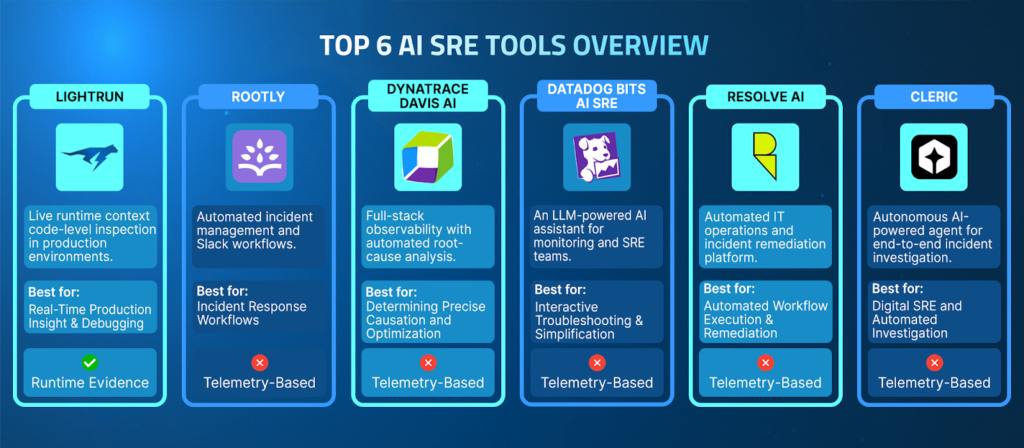
1. Lightrun
Lightrun is the only AI SRE platform that connects AI reasoning directly to live runtime context. Rather than operating over pre-captured telemetry, Lightrun generates the exact execution evidence needed to confirm root causes directly inside running services, under real traffic conditions, without redeployments. Every other tool in this list narrows the search space. Lightrun confirms the answer. It is used by enterprise engineering teams at companies such as AT&T, Citi, and Salesforce.
Key Features
- On-demand runtime evidence generation inside running services
- AI-driven root cause analysis grounded in live execution behavior
- Conversational AI SRE for code investigation and architecture improvement
- Deep Code Research for proactive live system review before incidents escalate
- MCP interface for build-time runtime context in AI coding assistants
- Lightrun Sandbox for safe fix validation before changes impact users
- Deep integrations with PagerDuty, Datadog, GitHub, Jira, and more than 100 additional tools
- Real-time Slack and Teams-native incident workflows
- Full auditability for PCI-DSS, SOC 2, and other compliance frameworks
What the Lightrun AI SRE Does During an Investigation
The Lightrun AI SRE is an incident investigation assistant built to help engineering teams triage, explain, and correlate production issues faster. During an active investigation, it:
- Triages the failure: explains what is failing, characterizes the error mode, and separates symptoms from probable causes
- Correlates changes: maps incident onset against recent deployments, config changes, and feature-flag activity
- Assesses blast radius: maps affected services, endpoints, and downstream impact so incident commanders understand urgency immediately
- Reconstructs the timeline: assembles a clear picture from alerts, logs, metrics, and change events to create shared situational awareness fast
- Ranks hypotheses: surfaces the most plausible causes first, so teams stop exploring low-signal paths
- Proposes next steps: suggests targeted diagnostic checks that confirm or rule out each hypothesis
- Analyzes logs and metrics: identifies recurring errors, failure patterns, and affected components at scope
- Investigates code: engineers can query the AI SRE conversationally to understand how specific code paths behave under live execution and use those insights to improve architecture proactively
Hands On: From Alert to Confirmed Root Cause in Minutes
An on-call SRE at a financial trading platform notices a spike in failed high-value trade validations after a new deployment. The engineer opens the Lightrun AI SRE web interface, tags the agent in Slack or Microsoft Teams, or uses the IDE integration and asks one question: Why are high-value trade validations failing after the latest deployment?
Lightrun AI SRE investigates autonomously, checking commits, inspecting code, and pulling logs, and surfaces the exact root cause at the code level in minutes with no redeployment and no guesswork.
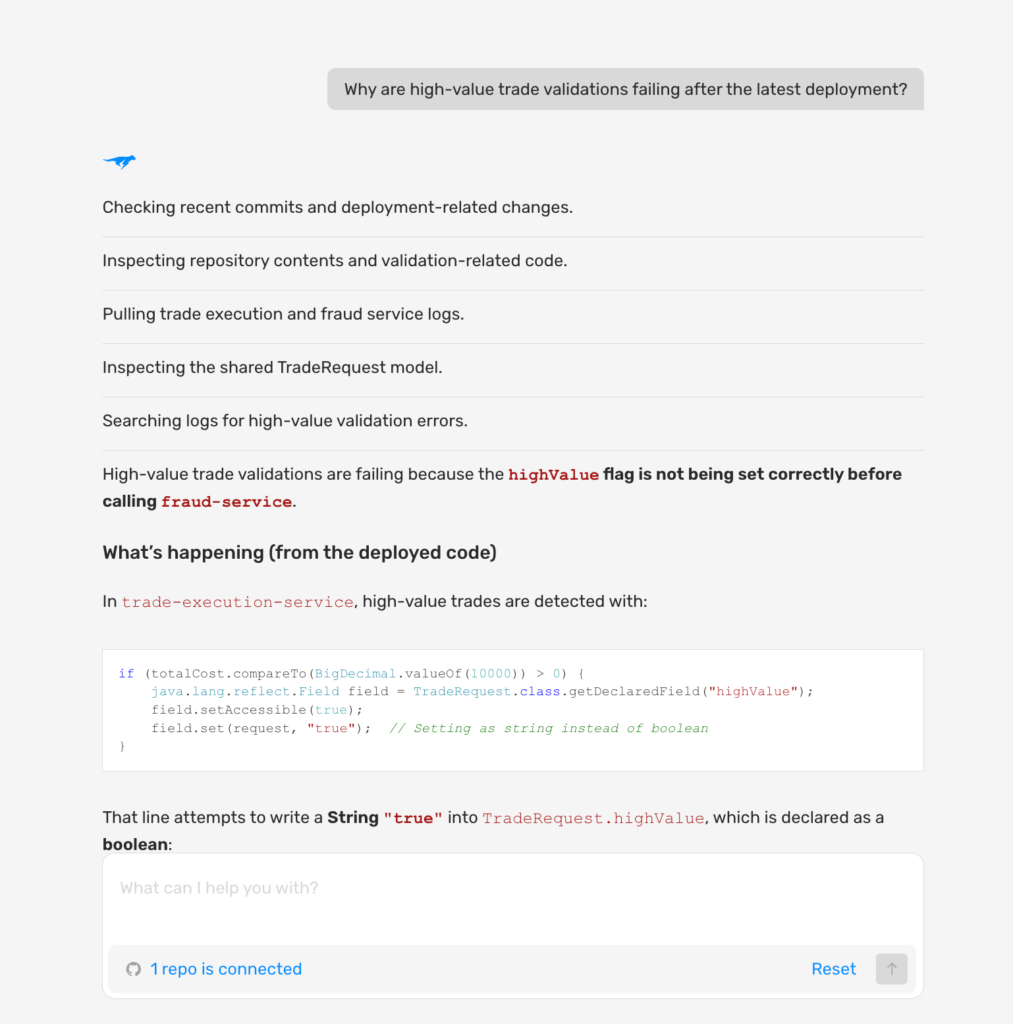
With the root cause suspected, Lightrun captures a live runtime snapshot directly inside the running service under real production traffic. The snapshot confirms the finding: totalCost = 2070.4 and highValue = false, a legitimate high-value trade that was never flagged correctly. Every variable value, execution path, and stack frame is visible under real traffic, without a single redeployment.
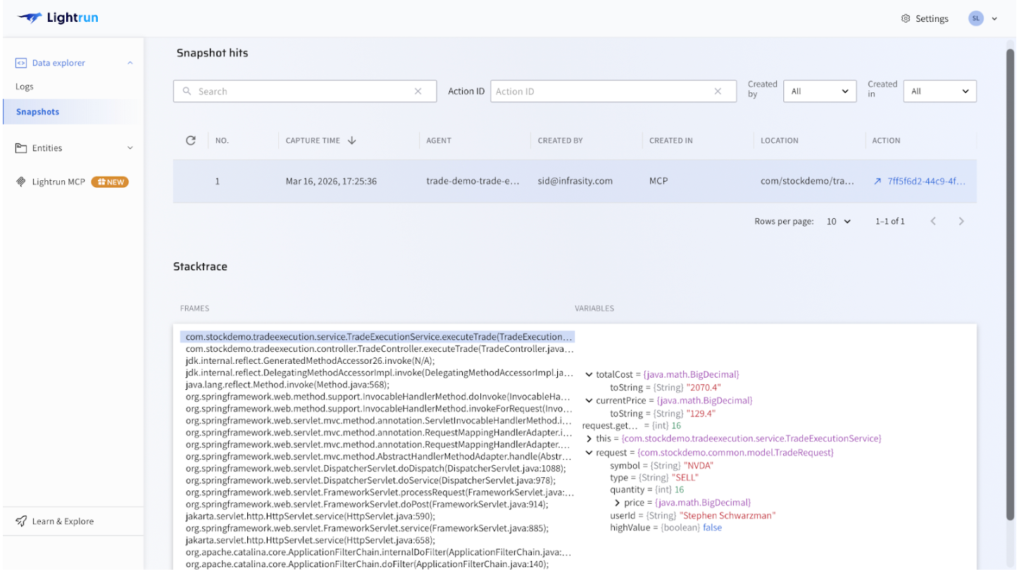
What Lightrun Does Well
Lightrun closes the gap between hypothesis and confirmed root cause. The AI SRE investigates autonomously while runtime snapshots validate findings against live execution, together eliminating the redeploy loop entirely and moving engineers from alert to confirmed resolution in minutes, with every action fully auditable for compliance review.
Consideration
Lightrun does not replicate alert routing or incident coordination. For enterprises that need both layers, Lightrun complements rather than replaces existing incident management tooling.
Best For:
Enterprise SRE teams, platform teams, and on-call engineers who need runtime-grounded root cause confirmation, proactive system monitoring, code-level investigation, and full auditability across regulated environments, including financial services, healthcare, and government infrastructure.
2. Rootly
Rootly is an AI-native incident management platform designed to help teams detect, coordinate, resolve, and learn from incidents across the entire lifecycle.
Its Slack-native interface means engineers manage incidents where they already work, with automated status updates, stakeholder communication, and runbook execution, reducing manual overhead during active incidents. Its MCP server integration also lets engineers acknowledge, investigate, and resolve incidents directly from their IDE without switching context.
Key Features
- AI-powered incident management with automated runbook execution
- Real-time Slack and Teams-native incident workflows
- Postmortem automation with retrospective analytics
- On-call scheduling and escalation management
- MCP server integration that allows engineers to resolve incidents without leaving their code environment
- Deep integrations with PagerDuty, Datadog, GitHub, Jira, and more than 100 additional tools
What Rootly Does Well
Rootly covers the full incident lifecycle from detection through coordination to retrospective analytics, all in one platform with no stitching required. For teams whose primary bottleneck is incident coordination overhead rather than investigation depth, Rootly’s automated workflows, stakeholder communication, and postmortem generation significantly reduce the manual burden during and after incidents.
Limitation
Rootly is built for incident coordination and workflow automation, not deep root cause investigation. It manages the process around a production incident exceptionally well, but does not generate or validate execution-level evidence about why the failure occurred. Teams whose primary bottleneck is finding the root cause will need an additional investigative layer beyond Rootly.
Best For
Engineering and on-call teams that need structured, automated incident coordination, postmortem generation, and runbook execution tightly integrated into existing communication and development workflows.
3. Dynatrace Davis AI
Dynatrace is an AI-powered observability platform built for enterprise-scale distributed systems. Its core AI engine, Davis, automatically discovers service dependencies, correlates anomalies across the full stack, and surfaces structured root cause explanations without requiring any manual signal correlation from the SRE team.
Davis AI has been in production since 2017 and has evolved into a hypermodal system that combines predictive AI, causal AI, and generative AI on a single unified platform, making it the default choice for many large enterprise engineering organizations.
Key Features
- Automated root cause analysis with the Davis AI engine
- Automatic dependency mapping and real-time topology discovery
- Full-stack anomaly detection across applications, infrastructure, and cloud environments
- AI-driven problem correlation with causal chain analysis
- Agentic AI for autonomous remediation workflows
- Support for hybrid and multi-cloud enterprise environments
What Dynatrace Does Well
Davis AI excels at automated intelligence at scale. For enterprises managing complex, multi-cloud distributed systems, the ability to automatically discover dependencies, correlate anomalies across the full stack, and generate structured root cause explanations significantly reduces the manual triage burden on on-call SRE teams.
The Problems dashboard gives teams a consolidated, prioritized view of everything happening across their environment in real time.
Limitation
Davis AI is bounded by pre-captured telemetry. When the signal confirming the root cause is never collected, Davis AI generates plausible explanations but cannot validate what was actually executed within the running service. Teams still hit the redeploy loop when the critical execution-level signal is missing, which is precisely the gap that platforms like Lightrun are built to close.
Best For
Large enterprise SRE teams managing complex, multi-cloud distributed systems that need automated anomaly correlation, dependency mapping, and AI-generated root cause explanations at scale.
4. Datadog Bits AI SRE
Datadog Bits AI SRE is Datadog’s dedicated AI SRE product, launched in late 2025. It adds a fully autonomous investigation layer on top of the Datadog platform, automatically investigating alerts the moment they fire and producing structured, audit-ready root cause analyses without additional tooling or context switching.
For teams already fully invested in the Datadog ecosystem, it removes the need to leave the platform during an investigation.
Key Features
- Autonomous 24/7 alert investigation across logs, metrics, traces, deployments, and source code
- Multi-step root cause analysis with hypothesis validation and invalidation tracking
- Automated remediation via Action Catalog, including script execution and runbook automation
- HIPAA-compliant with role-based access control
- Integrations with GitHub, ServiceNow, Grafana, Splunk, and Dynatrace
What Datadog Does Well
For teams already running Datadog, Bits AI SRE adds a genuinely autonomous investigation layer without requiring additional tooling. The hypothesis tree maps validated and invalidated theories in real time, giving engineers a structured view of what the AI has confirmed versus what still needs investigation, all inside the same platform as their metrics, logs, and traces.
Limitation
Bits AI SRE is bound by telemetry already inside Datadog. When the exact execution-level signal was never captured, it cannot validate what was actually executed without additional instrumentation and redeployment. Partial Datadog stacks get partial AI coverage, and teams on Grafana, New Relic, or mixed observability stacks get significantly less value from this tool.
Best For
SRE and engineering teams have already invested in Datadog and need an always-on, autonomous AI agent to investigate alerts and provide audit-ready root-cause analysis within their existing incident response workflow.
5. Resolve AI
Resolve AI is one of the most autonomous AI SRE platforms available today. It deploys a multi-agent architecture that simultaneously pursues multiple hypotheses, validates each against available evidence, and generates concrete remediation outputs, including pull requests and code fixes.
Key Features
- Multi-agent architecture pursuing parallel hypotheses simultaneously
- Autonomous incident investigation across code, infrastructure, and telemetry
- Automated remediation, including code fix generation and runbook execution
- Continuous learning from past incidents and team knowledge
- Vendor-neutral integration across observability sources
What Resolve AI Does Well
Resolve AI’s parallel hypothesis testing and automated code fix generation set it apart from most AI SRE tools. It evaluates multiple possible causes simultaneously and ranks them based on available evidence, helping engineers converge on the most likely root cause faster. In many cases, it can also generate a ready-to-implement fix within minutes, with human approval required before any automated action is executed in production.
Limitation
Output quality is directly tied to telemetry coverage and the completeness of integration. When execution-level signals are missing, Resolve AI narrows possibilities but cannot confirm what was actually executed inside the running service. Setup time can also be significant for complex environments with many observability sources.
Best For
Engineering teams that need highly autonomous AI incident investigation with parallel hypothesis testing and automated code fix generation across complex multi-tool production environments.
6. Cleric
Cleric is an AI SRE teammate that investigates incidents using reasoning rather than rigid rules. It forms hypotheses, tests them like a seasoned engineer, and delivers diagnoses directly in Slack in minutes. For engineering teams facing institutional knowledge loss as they scale or change personnel, Cleric continuously learns from every incident it processes, becoming more accurate over time.
Key Features
- Reasoning-based investigation rather than rule-based alert matching
- Parallel hypothesis testing with confidence scoring and tracking
- Self-learning from past incidents and institutional knowledge
- Diagnoses delivered directly in Slack without context switching
- Integration with more than 10 observability and incident management tools
What Cleric Does Well
Cleric’s reasoning-based approach and continuous learning model address one of the most persistent reliability challenges: institutional knowledge loss. Every incident Cleric investigates compounds into a growing knowledge base, making future investigations faster and more accurate without any manual documentation effort from the team.
Limitation
Cleric does not generate automated code fixes or pull requests; it provides only findings and recommendations. Like every other tool in this list, its output quality is bound by the telemetry it can access, and when critical execution-level signals are missing, Cleric narrows the search space but cannot confirm what is actually executed inside the running service.
Best For
Engineering teams that want a self-learning AI SRE that improves with every incident, delivers diagnoses directly in Slack, and captures institutional knowledge that would otherwise be lost between team members.
How These Tools Compare
Every team’s reliability stack reflects different priorities. Some need autonomous remediation. Others need alert noise reduction. Some require the deepest possible root cause investigation. The table below maps all six tools across the criteria that matter most.
| Capability | Lightrun | Rootly | Dynatrace Davis AI | Datadog Bits AI SRE | Resolve AI | Cleric |
| Investigation Approach | AI-driven incident triage, correlation, and runtime evidence generation | Incident coordination and automation | Automated anomaly correlation | Autonomous telemetry investigation | Parallel hypothesis testing | Self-learning investigation |
| Novel Evidence Generation | Generates new evidence safely and on demand, inside a running service | Is unable to generate new evidence, using pre-captured signals only | Predictive (synthetic) evidence based on telemetry forecasts, not actual execution data | Pre-captured signals only | Pre-captured signals only | Pre-captured signals only |
| Runtime Context | Native, execution-level | None | None | None | None | None |
| Proactive Monitoring | Yes, Deep Code Research | No | Partial | Partial | No | No |
| Automated Fix Validation | Yes, Lightrun Sandbox | Via runbook automation | No | Via Action Catalog | Via PR and code fix | No |
| Governance and Auditability | Full, compliance-grade | Partial | Partial | HIPAA, RBAC | Partial | Partial |
| Code Investigation | Yes, conversational AI SRE | No | No | No | No | No |
| Multi-vendor Integration | Vendor-neutral, integrates across observability and dev toolchains | Broad integrations across incident and DevOps tools | Strong enterprise integrations, Dynatrace-centric | Primarily, the Datadog ecosystem is limited to outside coverage | Vendor-neutral across observability sources | Integrates across multiple observability tools |
| Best For | Runtime-grounded RCA | Incident coordination | Enterprise anomaly correlation | Datadog-native teams | Autonomous remediation | Self-learning investigation |
Each tool in this list does its job well within the boundaries for which it was designed. The critical distinction is in evidence generation. Every tool except Lightrun operates exclusively on pre-captured telemetry, and that distinction matters more than any other capability in the table.
The bottleneck in modern incident resolution has shifted from detection speed to confirmation certainty. Correlation narrows the search space, but only execution-level evidence confirms the answer.
To go deeper, read What is Runtime Context? A Practical Definition for the AI Era and How a Runtime-Aware AI SRE Agent Transforms System Reliability.
What Makes Runtime-Aware AI SRE the Standard?
Lightrun addresses the confirmation gap directly by connecting AI reasoning to live runtime context. Rather than analyzing what telemetry already exists, Lightrun generates the missing execution evidence on demand, directly inside the running service, under the exact traffic conditions that produced the failure.
AI SRE: From Hypothesis to Evidence-Based Determination
When an incident fires, Lightrun AI SRE does not start with what telemetry already exists. It starts by identifying the evidence needed to confirm the root cause. It then generates this evidence directly inside the running service using a secure read-only sandboxed environment
- Generates missing runtime evidence on demand inside running services
- AI-driven root cause analysis correlated across services, deployments, and dependencies
- Every finding is grounded in real execution behavior, not inferred from incomplete signals
- Every fix is validated in the Lightrun Sandbox before touching users
- Every action is fully auditable for PCI-DSS, SOC 2, and other compliance frameworks
For an on-call SRE at an enterprise managing a live payment processing failure, this means moving from alert to confirmed root cause in minutes rather than hours, with full auditability across every investigative action for compliance review.
Deep Code Research: Getting Ahead of Incidents Before They Happen
Most AI SRE tools are reactive by design; they activate when something breaks, investigate what broke, and go quiet again. The most expensive production failures, however, are rarely sudden crashes. They are slow, unusual patterns that build up in live systems and go unnoticed until it is too late.
Lightrun’s Deep Code Research changes this; instead of waiting for an incident to fire, it lets engineering teams actively query live system behavior and surface unusual patterns before they escalate. The shift is from reactive firefighting to proactive reliability.
In practice, this means teams can:
- Query how a specific workflow is behaving across thousands of live requests in real time
- Spot edge cases that are silently producing incorrect results before any customer is impacted
- Catch slow-building anomalies that traditional monitoring never flags because no threshold was ever breached
- Address issues during normal working hours rather than at 2 AM when they finally blow up
For an SRE team at a payments enterprise, this means being able to check how a transaction validation workflow is performing under real traffic right now, not after the next incident report. Deep Code Research sits between peacetime development and wartime incident response, the proactive layer that most reliability stacks are missing entirely.
Runtime Context MCP: Runtime Context at Build Time
Reliability processes should not begin when an incident hits. It needs to begin the moment engineers write the code that will eventually run in production. Lightrun’s Runtime Context MCP feeds live execution context directly into AI coding assistants and development workflows, allowing engineers to validate assumptions against real execution behavior before a single line of code ships to production.
In practice, this enables teams to:
- Access live execution insights directly within AI coding assistants and development workflows
- Validate assumptions against real system behavior before code is deployed
- Catch incorrect assumptions at build time instead of during production incidents
- Investigate code paths using real execution data to inform architectural decisions
This shifts reliability earlier in the development lifecycle, turning it into a design-time concern rather than a post-incident activity.
Conclusion
Rootly, Dynatrace, Datadog, Resolve AI, and Cleric all address real reliability pain points across detection, correlation, autonomous investigation, and incident coordination. Each tool has a legitimate place in the modern reliability stack depending on your team size, observability maturity, and where your biggest bottleneck sits.
But regardless of which AI SRE tool you choose, the confirmation gap remains unless runtime context is included. Most of the tools in this list will tell you that something is wrong. They will correlate signals, generate hypotheses, and narrow the fault domain. What they cannot do is confirm what was actually executed inside the running service at the moment of failure. Lightrun closes this gap by generating execution-level evidence on demand, allowing teams to validate root causes directly in live systems without redeployment.
AI that correlates signals accelerates triage. AI that validates execution confirms runtime truth. For engineering teams serious about moving from probable cause to confirmed resolution, runtime context is no longer optional. Lightrun is the only platform that closes that gap with live, runtime-grounded reliability from code to production.
FAQ
AI SRE tools use artificial intelligence to accelerate incident detection, root cause analysis, and remediation across distributed production systems. They ingest telemetry signals, including logs, metrics, traces, and deployment history, to correlate anomalies and reduce the manual triage burden on engineering teams.
Traditional monitoring tools detect and alert. AI SRE tools investigate correlations across sources, generate hypotheses about root causes, and, in some cases, autonomously propose remediation. Where a traditional tool tells you latency is high, an AI SRE tool explains why and what to do about it.
AIOps focuses broadly on IT operations event correlation, alert-noise reduction, and infrastructure remediation. AI SRE is specifically focused on the reliability engineering workflow: incident investigation, root cause analysis, and fix validation across distributed software systems.
Most AI SRE tools are bound by pre-captured telemetry. When the signal needed to confirm a root cause was never collected before the incident, the AI can narrow down possibilities, but cannot validate what actually occurred. Teams are still forced to add instrumentation, redeploy, and wait for the confirmation gap to be solved.
Lightrun is the only AI SRE platform built on live runtime context. Rather than analyzing pre-captured telemetry, it generates missing execution evidence on demand, directly inside running services, without redeployments. Every other tool in this list narrows the search space. Lightrun confirms the answer.


