
How to Reduce MTTR with AI-Powered Runtime Diagnosis
Mar 12, 2026 / Updated: May 11, 2026


Reducing Mean Time to Resolution (MTTR) in production systems requires understanding failure behavior in real time. While AI code agents significantly accelerated software development and deployment, incident resolution has remained constrained by incomplete pre-captured telemetry. AI SRE tools improve signal correlation, but MTTR reduction requires runtime-verified diagnosis that confirms execution behavior directly in production systems.
TL;DR
- AI accelerated code generation, but not incident resolution. Modern failures emerge under real traffic, not in staging environments.
- MTTR is now limited by runtime verification, not development speed. Faster deployment pipelines do not confirm root causes faster.
- Pre-collected telemetry is structurally incomplete. Logs, metrics, and traces are predefined. If the triggering runtime state was never captured, debugging or incident resolution becomes guess-driven.
- AI SRE improves correlation but cannot prove execution without runtime context. It narrows hypotheses but does not validate them.
- Significant MTTR reduction requires runtime-verified diagnosis. Generating execution-level evidence on demand eliminates redeploy loops and directly confirms root causes.
Production failures rarely appear where teams expect them. A deployment passes review, automated tests succeed, and staging environments appear stable. Under real traffic, latency spikes. Logs show no explicit error. Metrics are aggregated. Traces reveal only fragments of execution paths. Engineers add instrumentation, redeploy, and attempt reproduction, repeating the cycle until the root cause is confirmed.
AI has dramatically increased development velocity. Code generation, review, and deployment pipelines operate faster than ever. The bottleneck has shifted. Writing code is no longer the limiting factor; verifying how it behaves in live runtime conditions is.
AI SRE (AI site reliability engineering) is emerging to address this operational shift. AI systems can correlate signals across services, summarize incidents, and suggest likely remediation paths. Yet most AI SRE implementations remain constrained by pre-captured telemetry. If the critical runtime state was never recorded, AI can infer patterns but cannot verify what was actually executed. Sustainable MTTR reduction in modern systems requires moving beyond telemetry interpretation toward runtime-verified diagnosis.
What Actually Expands MTTR in Cloud-Native Systems?
In modern microservices architectures, MTTR rarely increases because engineers cannot write fixes. It increases because teams cannot quickly confirm what happened.
When a latency spike breaches an SLO, incident response begins immediately. Engineers pivot across dashboards, logs, traces, deployment history, and configuration changes to determine what shifted. In distributed systems, signals are fragmented. Logs are predefined. Metrics are aggregated. Traces show partial paths.
If the runtime condition that triggered the failure was never captured, teams must redeploy with additional instrumentation and attempt to reproduce the failure under live traffic. Each cycle adds delay. In practice, confirmation, not hypothesis generation, dominates MTTR.
How Does AI SRE Compress the Investigation Window?
AI SRE operates inside this investigative loop. Instead of engineers manually toggling between tools like Grafana, Datadog, Splunk, and distributed tracing systems, AI models analyze telemetry in parallel.
They correlate anomalies with recent deployments, configuration changes, and traffic spikes to rapidly narrow the likely fault domain.
AI SRE helps teams:
- Correlate alerts across distributed services
- Detect abnormal patterns in logs and metrics
- Map failures to recent releases
- Prioritize incidents by SLA/SLO impact
- Generate probable root cause hypotheses
- Recommend remediation actions
- Produce structured RCA summaries
This significantly reduces the time spent narrowing the search space. However, most AI SRE systems still rely on pre-captured telemetry. If the relevant runtime state was never logged, AI can suggest probable causes but cannot verify execution. Correlation accelerates triage, but confirmation may still require redeploy cycles.
To materially reduce MTTR, AI must move from correlation to runtime-aware diagnosis.
AI SRE vs Traditional SRE: Impact on MTTR Reduction
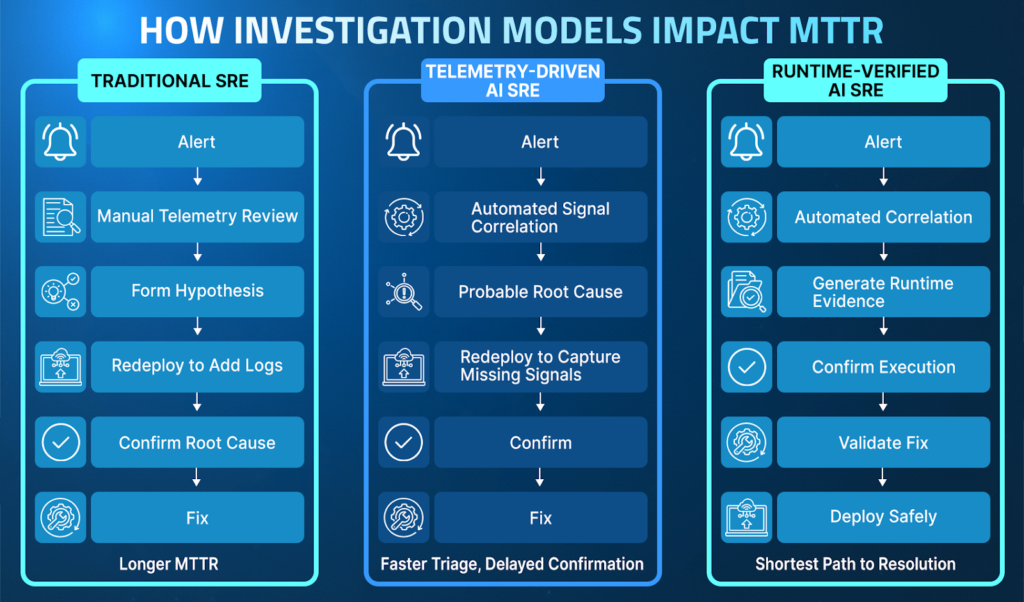
Traditional SRE focuses on detection and human-led investigation. When an alert fires, engineers manually check dashboards, logs, traces, and deployment history to determine what changed. They compare error spikes in Grafana, scan logs in Splunk or Datadog, inspect distributed traces, review recent commits, and check configuration updates.
If the runtime condition that caused the failure was never captured, engineers must add new instrumentation, redeploy the service, and attempt to reproduce the issue under similar traffic conditions. Each iteration increases the team’s MTTR.
AI SRE accelerates this workflow by automating cross-telemetry correlation. Instead of sequential analysis, these AI systems scan logs, metrics, traces, deployment history, and configuration changes in parallel. They identify anomalous patterns, map impacted services, and generate probable fault domains within seconds, significantly reducing time spent narrowing the search space.
The material shift occurs when AI moves from correlation to verification. Telemetry-driven AI narrows possibilities. Runtime-aware AI confirms execution. That distinction determines how quickly an investigation concludes and how effectively MTTR reduction can be achieved.
Approach
Diagnosis Model
Limitation
Impact on MTTR
Traditional SRE
Manual telemetry analysis
It depends on high volumes of developer and SRE, as well as pre-captured telemetry, to identify the root cause of an incident.
Longer resolution cycles
Telemetry-Driven AI SRE
Automated correlation and hypothesis generation
Requires redeployment to collect missing instrumentation and produces probable root cause analysis rather than definitive conclusions. Proposed fixes require validation.
Triage is accelerated, but requires additional work to produce a confirmation.
Runtime-Aware AI SRE
On-demand execution validation
Requires access to secure sandboxed runtime environments to ensure data is collected safely without altering code or impacting users. Proposed fixes are validated against live system behavior.
Eliminates redeploy loops, shortening the path to confirmed RCA and incident resolution.
The contrast between correlation and verification becomes clearer in a real production incident.
Correlation vs Execution Proof in a Real Production Incident
Consider a payment service experiencing a sudden spike in latency after a deployment.
A telemetry-driven AI SRE system correlates the spike with updated retry logic and flags a potential regression. The hypothesis is statistically strong, but it remains inferential. Engineers still need to redeploy with additional logging to confirm whether the retry branch actually executed under real traffic.
A runtime aware AI SRE system generates execution-level evidence immediately. It inspects the live conditional branch, confirms that the retry loop triggered under specific inputs, and validates the remediation before broad rollout. No speculative redeploy is required.
The operational difference is clear:
- Correlation narrows possibilities.
- Verification confirms reality.
- Confirmed root causes eliminate the need for repeated investigation loops.
Eliminating redeploy cycles directly reduces MTTR and increases confidence in remediation decisions.
In complex distributed architectures, investigation time is dominated by validation rather than hypothesis generation. Telemetry-driven AI accelerates pattern recognition, but runtime-aware AI SRE shortens the path to confirmed resolution. By generating missing execution evidence on demand and validating fixes before impact, AI SRE eliminates redeploy loops and reduces MTTR through execution-level certainty rather than probabilistic inference.
The Runtime Context Gap: Why Telemetry-Driven AI SRE Falls Short
Telemetry-driven AI SRE inherits the limitations of modern observability systems. Logs, metrics, and traces are designed to capture predefined signals, not every possible runtime condition. Logs reflect what engineers anticipated might matter. Metrics summarize behavior at an aggregate level. Traces follow selected execution paths. None of these guarantees that the exact signal required to explain a specific failure is available when an incident occurs.
When critical runtime information is missing, investigation slows down. Teams typically redeploy to add new logging, wait for CI/CD pipelines to complete, attempt to reproduce the issue locally, or infer behavior from incomplete data. Each iteration increases Mean Time To Resolution (MTTR) and introduces uncertainty.
AI models trained solely on telemetry can identify patterns, but they cannot verify what actually happened during execution. This gap defines the structural limitation of telemetry-driven AI SRE.
Without direct visibility into execution paths, variable state, conditional logic, dependency behavior, and traffic-specific inputs, AI remains correlation-based rather than verification-based. To move beyond inference, AI SRE requires access to live runtime context.
This runtime context gap is not an implementation flaw; it is an architectural boundary. As long as AI operates only on predefined telemetry, MTTR reduction will plateau at the speed of correlation. Sustainable MTTR reduction requires grounding AI systems in live execution behavior.
Why Runtime Context Is the Foundation of Sustainable MTTR Reduction
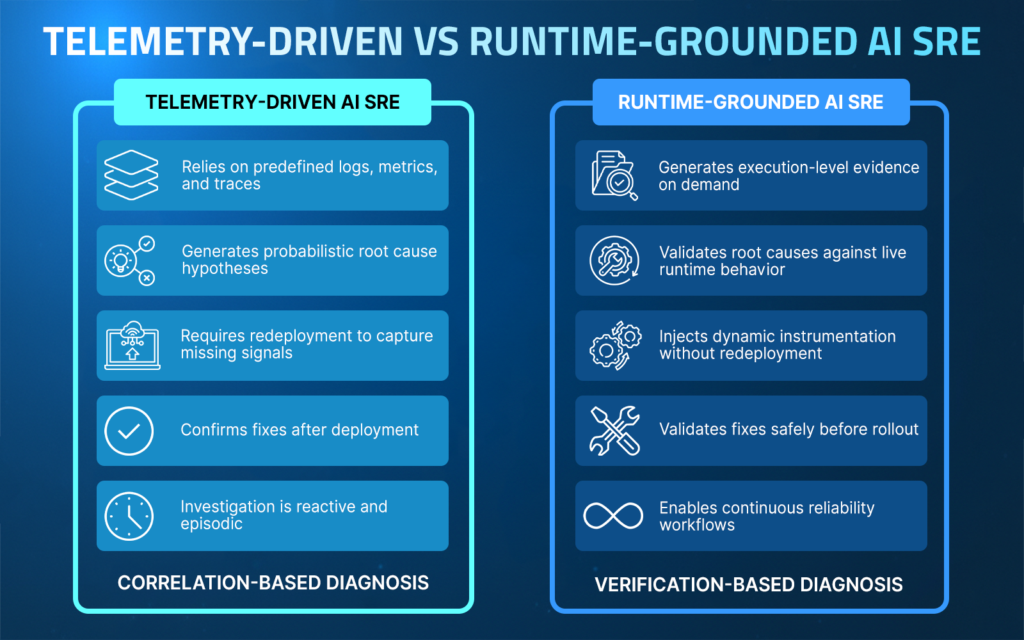
AI SRE becomes reliable only when intelligence is grounded in live execution behavior. Systems that rely solely on predefined logs and metrics can identify patterns and generate hypotheses, but they cannot confirm what actually occurred during runtime. Verification requires direct access to execution paths, variable state, and conditional logic under real traffic conditions.
Lightrun enables this shift by allowing teams and AI agents to generate execution-level evidence inside running services without redeployment. Dynamic logs, snapshots, and metrics can be injected safely, providing immediate visibility into live behavior. Instead of waiting for additional telemetry or repeating investigation cycles, teams validate root causes directly against the runtime.
This transition moves reliability engineering from correlation-based analysis to verification-based diagnosis. Correlation accelerates investigation. Runtime context concludes it. In complex distributed systems, a confirmed execution state materially reduces MTTR.
AI SRE in Practice: Core Use Cases
AI SRE delivers measurable value by improving how teams diagnose, resolve, and prevent production failures. When grounded in live execution behavior, these workflows drive meaningful reductions in MTTR across distributed systems. The following workflows illustrate how runtime-aware AI SRE reduces MTTR across enterprise systems.
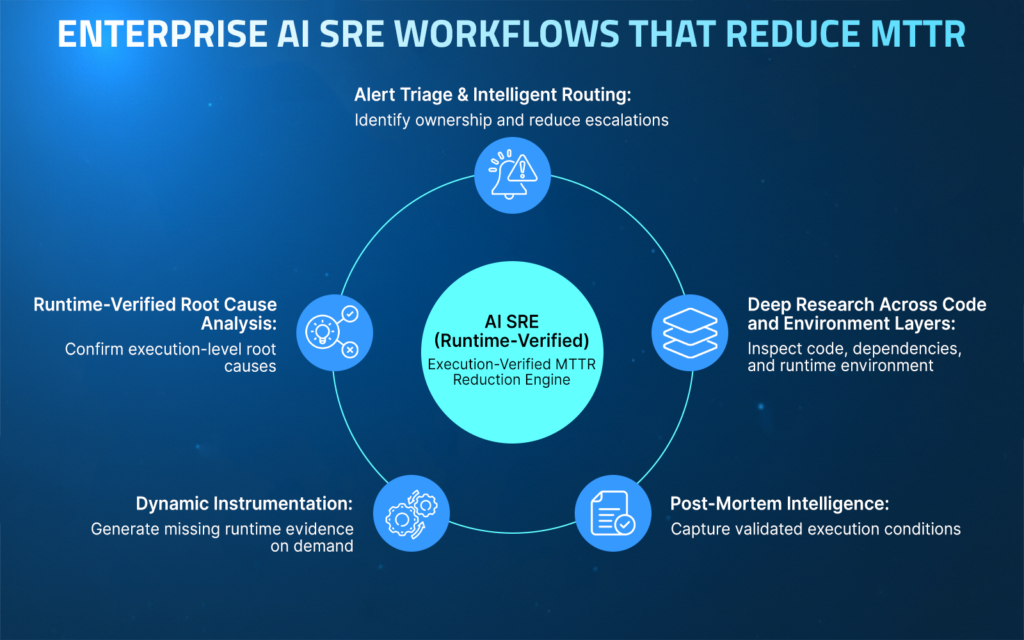
1. Runtime-Aware Root Cause Analysis and Fix Recommendations
Root cause analysis in distributed systems often involves multiple services and recent deployments. Consider a payment processing system where checkout latency increases only for a subset of customers.
Telemetry shows increased response times, but no obvious error logs. AI SRE correlates the latency spike with a recent retry-logic deployment and identifies a potential loop under specific input conditions.
When the runtime context is available, AI SRE can inspect the exact execution path and variable state that triggered the retry loop. Instead of suggesting a probable fix, the system validates the condition under real traffic and confirms the remediation before full rollout. This reduces regression risk, shortens MTTR, and increases confidence in the fix.
2. Alert Triage and Routing Across Teams and Services
Large organizations operate dozens or hundreds of microservices owned by different teams. When an authentication service degrades, alerts may cascade across API gateways, billing services, and user-facing applications. Traditional routing rules often lead to multiple teams investigating the same issue.
AI SRE correlates alerts across services, identifies the originating component, and automatically maps ownership. With runtime evidence attached, the system can show that failed token validation requests originate from a misconfigured identity provider rather than downstream services. Accurate routing reduces escalation chains and allows the responsible team to act immediately.
3. Deep Research Across Code and Environment Layers
Enterprise outages frequently span application logic, infrastructure conditions, and third-party dependencies. Consider a SaaS platform experiencing intermittent data inconsistencies across multiple regions. Logs indicate successful writes, but users report stale reads.
AI SRE, supported by runtime context, can analyze execution flows across write services, caching layers, and replication pipelines. By inspecting variable state and dependency behavior under live traffic, the system identifies a cache-invalidation timing issue specific to a single region. This cross-layer visibility enables resolution without relying solely on telemetry summaries.
4. Dynamic Instrumentation for Unknown Unknowns
Unknown unknowns extend the incident duration because the required signal was never anticipated. On a high-frequency trading platform, an intermittent pricing discrepancy can occur under specific market conditions. Existing telemetry does not capture the intermediate calculation state that produced the error.
AI SRE enables dynamic instrumentation within the running service to capture the state of missing variables without redeploying the application. By gathering targeted runtime evidence, the system isolates a rounding condition triggered by rare input combinations. Eliminating redeploy cycles reduces investigation time in latency-sensitive environments.
5. Post-Mortems and Knowledge Capture
Enterprise systems must learn from incidents to prevent recurrence. On a healthcare platform handling regulated data, a configuration change causes intermittent authorization failures. The incident is resolved, but without validated runtime evidence, post-mortems risk documenting inferred causes.
AI SRE, grounded in runtime context, captures the exact execution conditions that produced the failure, including configuration state and request attributes. This verified evidence strengthens compliance documentation and prevents similar regressions in future releases. Reliability evolves from reactive response to structured learning.
Lightrun Hands-On: Detecting a Logic Bug Without Redeploy
To illustrate how runtime context changes debugging workflows, consider a real scenario involving a Java Spring Boot trading application. The system processes buy and sell orders and runs two environments simultaneously: a production instance on port 8130 and a pre-production instance on port 8135. Both environments start with the Lightrun agent attached at JVM startup, allowing engineers and AI assistants to inspect runtime behavior without modifying or redeploying the service.
The trading workflow is implemented in the TradeExecutionService.executeTrade() method, which processes every incoming trade request. This method retrieves the current market price for a symbol, calculates the trade’s total cost, determines whether the trade qualifies as a high-value transaction, and then forwards the request to the fraud validation service.
The Subtle Bug in Trade Validation
The system attempts to flag trades above $10,000 so the fraud validation service can apply stricter checks.
// Calculate total cost
BigDecimal totalCost = currentPrice.multiply(BigDecimal.valueOf(request.getQuantity()));
if (totalCost.compareTo(BigDecimal.valueOf(10000)) > 0) {
try {
java.lang.reflect.Field field = TradeRequest.class.getDeclaredField("highValue");
field.setAccessible(true);
field.set(request, "true"); // incorrect type
} catch (Exception e) {
log.error("Error setting high value flag: {}", e.getMessage());
}
}At first glance, the logic appears correct, but the bug lies in a small type mismatch. The TradeRequest.highValue field is declared as a boolean, yet the reflection code attempts to set the value “true” as a String.
This mismatch throws an IllegalArgumentException. Because the exception is caught and logged, the error never propagates, and the high-value flag is never set. As a result, trades above $10,000 pass through fraud validation without triggering stricter rules.
The Traditional Debugging Loop
Without runtime inspection, diagnosing this issue would require a full redeploy cycle:
- Add temporary debug logs inside the high-value logic
- Rebuild the application JAR
- Redeploy the service
- Reproduce a trade above $10,000
- Inspect logs and iterate again if needed
In distributed systems with multiple environments, each redeployment interrupts the running system and increases investigation time.
Investigating the Issue Using Cursor + Lightrun MCP
Instead of modifying the source code, the investigation can be performed safely directly in the IDE using the Cursor with Lightrun MCP. MCP provides the AI assistant with access to runtime context, allowing it to dynamically request telemetry from a sandboxed, read-only running service.
The engineer asks the assistant to inspect runtime behavior for trades exceeding $10,000 in the executeTrade() method.
Step 1: Inspect the Method in Cursor
The engineer opens the TradeExecutionService file in Cursor and asks the assistant to observe the runtime behavior of the executeTrade() method.
The MCP integration allows the assistant to insert runtime instrumentation without modifying the codebase or restarting the service.
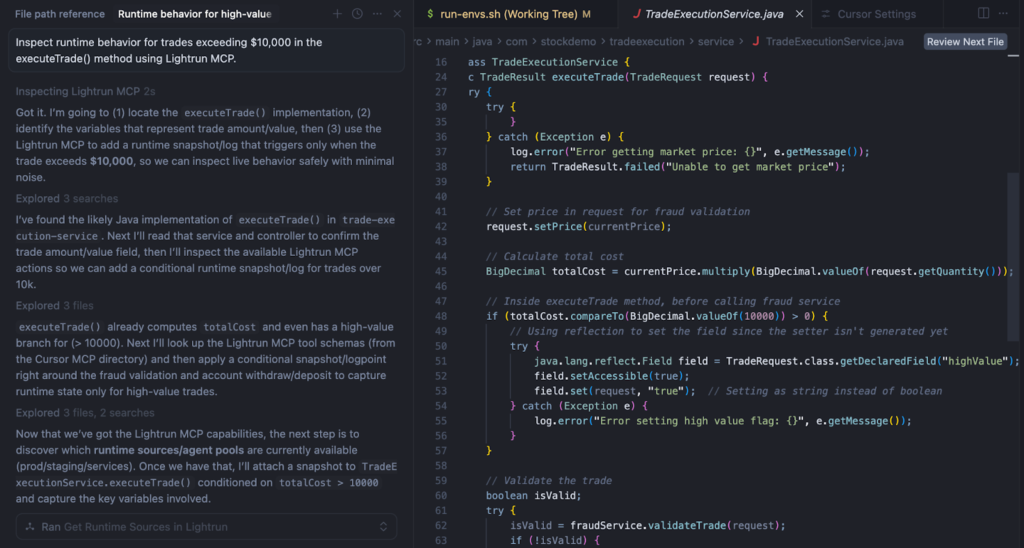
Step 2: Insert a Runtime Log for Trade Execution
To understand what data flows through the method, Lightrun MCP inserts a runtime log at the entry point of executeTrade().
The log captures key values from the trade request and the calculated trade cost.
[TRADE] user={request.userId}
symbol={request.symbol}
qty={request.quantity}
price={currentPrice}
total={totalCost}
highValue={request.highValue}
This log immediately reveals how the trade is being processed under real production traffic.
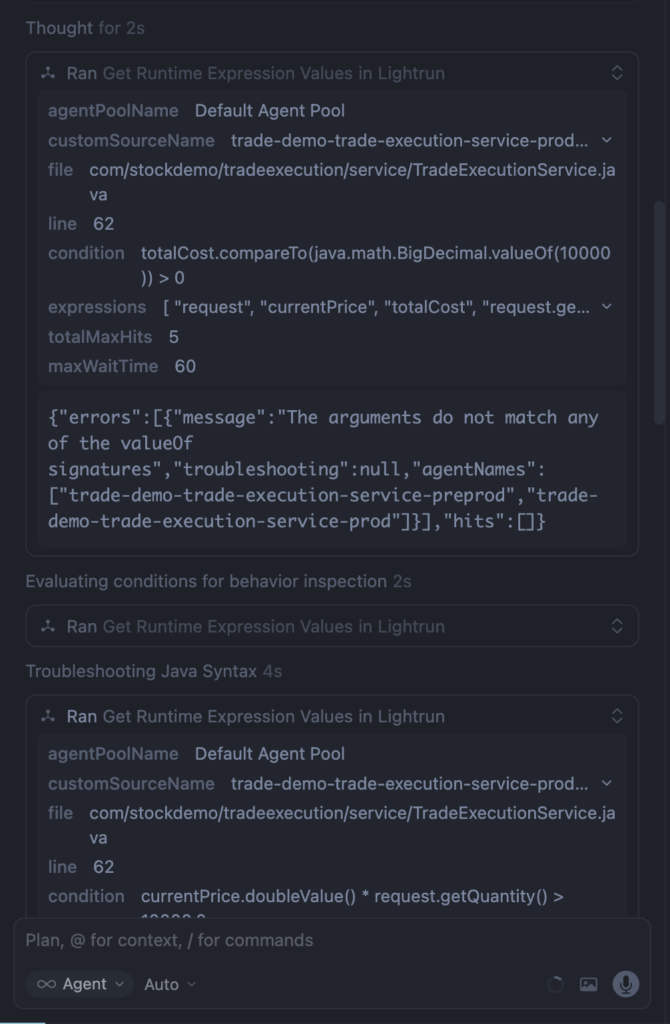
Step 3: Add a Conditional Snapshot for High-Value Trades
Next, Lightrun MCP inserts a conditional snapshot at the point where the high-value logic executes.
The snapshot triggers only when the trade value exceeds $10,000.
Configuration:
- Condition : totalCost.compareTo(java.math.BigDecimal.valueOf(10000)) > 0
- Max hits: 3
- Target: trade-execution-service-prod
Snapshots capture the complete runtime state, including stack frames and local variables.
Step 4: Observe the Runtime State
When the next high-value trade occurs, the snapshot captures the request object’s runtime state.
request = TradeRequest
symbol = "AAPL"
quantity = 65
price = 425.81
userId = "Philip Jefferson"
highValue = false
Even though the trade value clearly exceeds the threshold, the highValue field remains false. This immediately confirms that the flag assignment failed earlier in the execution path.
Applying the Fix
Once the issue is identified, the fix is straightforward. Instead of relying on reflection, the code should use the setter generated by Lombok.
if (totalCost.compareTo(BigDecimal.valueOf(10000)) > 0) {
request.setHighValue(true);
}
‘This ensures the correct boolean value is assigned and avoids the fragile reflection-based approach.
Validating the Fix with Runtime Logs
After deploying the fix, Lightrun MCP inserts one additional runtime log before fraud validation.
[FRAUD CHECK] highValue={request.highValue} validating trade for user={request.userId}
The next trade execution confirms that the highValue flag is now correctly propagated to the fraud validation service.
Why Runtime Context Matters
Bugs like this are difficult to detect using traditional observability tools. Metrics and traces can show that requests are processed successfully, but they rarely reveal whether critical flags or internal state values were set correctly during execution.
Runtime context provides a deeper layer of visibility by allowing engineers and AI assistants to inspect the actual behavior of running code. Instead of redeploying services to add instrumentation, teams can dynamically capture the exact data needed to diagnose the issue and verify the fix directly in production.
AI SRE Across the SDLC: MTTR Reduction from Shift-Left to Live Incidents
Sustainable MTTR reduction does not happen only during incidents. It requires reliability practices that span development, deployment, production, and post-incident learning. AI SRE extends beyond reactive response by embedding runtime-verified validation across the entire lifecycle.
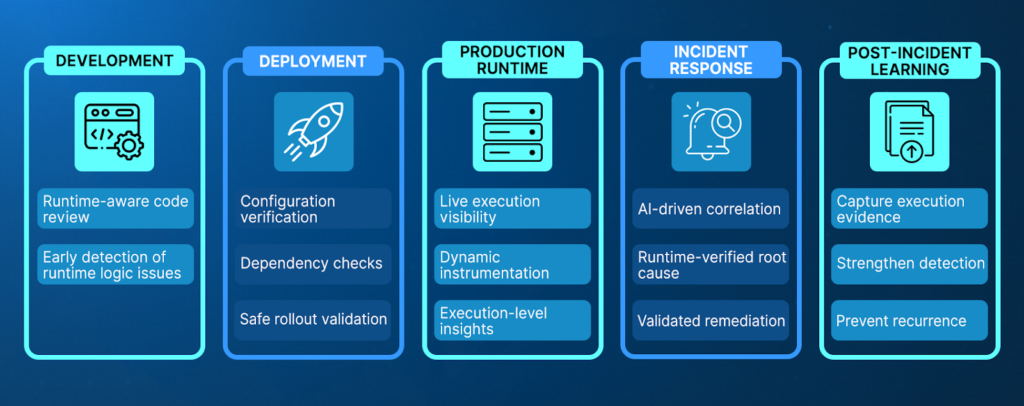
1. Shift-Left: Validating Risk Before Deployment
During development, AI SRE systems analyze code changes, deployment patterns, and historical incident data to identify high-risk modifications. When supported by runtime-aware capabilities, AI can validate assumptions against real execution behavior rather than relying solely on static analysis.
Shift-left AI SRE enables teams to:
- Identify risky logic paths before deployment
- Validate conditional branches under realistic inputs
- Detect configuration inconsistencies early
- Reduce production-only edge cases
- Improve release confidence
Reliability becomes embedded in the engineering workflow rather than triggered by a production alert.
2. Live Incidents: Verification Under Real Traffic
During production incidents, AI SRE accelerates triage and reduces manual investigation. When grounded in runtime execution visibility, AI systems can move beyond correlation and directly validate root causes.
Runtime-aware incident workflows enable teams to:
- Correlate alerts across distributed services
- Generate missing runtime evidence on demand
- Inspect execution paths and variable state live
- Validate remediation safely before full rollout
- Shorten MTTR in complex architectures
Instead of relying solely on pattern similarity, teams confirm the exact condition that caused the failure.
3. Continuous Feedback and Reliability Learning
AI SRE also strengthens post-incident workflows by feeding verified runtime evidence back into development and operations. Validated root causes refine detection models, improve alert accuracy, and inform safer architectural decisions. Over time, reliability shifts from reactive firefighting to a continuous, feedback-driven engineering discipline supported by both AI and runtime verification.
Governing AI SRE: Control, Compliance, and Runtime Safety
AI SRE introduces automation into reliability workflows, which makes governance and operational safety essential. In regulated environments such as finance, healthcare, telecommunications, and public sector systems, investigation tooling must operate without altering application state or introducing additional risk. AI-driven reliability must be designed to assist engineers while preserving strict control over production systems.
Enterprise-ready AI SRE platforms must operate under clearly defined safeguards. These safeguards typically include:
- Read-only instrumentation that does not mutate application state
- Strict role-based access controls and approval workflows
- Full audit trails of injected actions and AI-driven recommendations
- Compatibility with on-prem and private cloud deployments
- Minimal performance overhead during runtime inspection
These controls ensure that runtime investigation does not introduce instability or compliance exposure.
Equally important is human oversight. AI SRE should accelerate diagnosis and suggest remediation, but engineers must retain authority over execution. Every action taken by the system should be inspectable, verifiable, and reversible.
In high-compliance environments, reliability tooling must enhance operational intelligence without compromising governance boundaries. Effective AI SRE balances automation with accountability, enabling faster resolution while preserving enterprise-grade control.
Conclusion
AI has fundamentally changed how software is built. Development velocity has increased, systems have grown more distributed, and failure modes have become more runtime-dependent. As complexity expands, reliability engineering must evolve accordingly.
Traditional SRE practices rely heavily on predefined telemetry and reactive workflows. Telemetry-driven AI SRE improves signal correlation and automation, but it remains constrained by the limits of what was captured in advance.
Reliable AI SRE requires direct access to runtime execution behavior. Durable MTTR reduction depends on shortening the path from alert to verified execution state. When AI systems can generate missing evidence on demand and validate hypotheses in real time, diagnosis shifts from inference to verification.
This reduces redeploy loops, shortens MTTR, and increases confidence in remediation decisions. Runtime-aware AI SRE transforms reliability from episodic incident response into a continuous engineering discipline that spans development and production.
The next generation of AI SRE platforms will not rely solely on analyzing telemetry. They will combine intelligent automation with on-demand runtime visibility, enabling teams to investigate safely, validate fixes before impact, and continuously strengthen system resilience. As enterprises adopt AI-driven reliability practices, grounding automation in executional truth will determine which platforms deliver measurable operational improvements.
FAQs about reducing MTTR with AI SREs
AI SREs reduce MTTR (Mean Time To Resolution) by automating alert correlation, identifying probable fault domains, and accelerating root cause analysis. Instead of manually analyzing logs across multiple services, AI models quickly surface patterns and relationships. When combined with runtime-aware capabilities, AI SRE can directly validate root causes, eliminating redeploy loops and shortening investigation cycles.
Lightrun enables AI SRE to generate missing runtime evidence on demand by gathering snapshots, and metrics into running services. These actions operate in a read-only Sandboxed environment and do not require code changes or service restarts. This allows AI-driven workflows to validate hypotheses against live execution behavior without disrupting production systems.
Most AI SRE tools analyze pre-existing logs, metrics, and traces. Their effectiveness depends on the signals configured before the incident occurred. Lightrun extends AI SRE by enabling direct inspection of runtime behavior, allowing teams to capture missing execution data when needed. This shifts the diagnosis from correlation-based inference to evidence-based verification.
In distributed systems, failures often depend on specific runtime conditions, state transitions, or cross-service interactions. Telemetry-driven AI SRE can only analyze data that has already been collected. If the relevant signal was never captured, the AI cannot directly validate the cause. This limitation often leads to redeployment loops, delayed investigations, and increased operational risk.
Runtime context provides visibility into execution paths, variable state, conditional branches, and dependency behavior under live traffic. When AI-driven root cause analysis is grounded in this data, recommendations can be validated directly against real system behavior. This improves remediation accuracy, reduces regressions, and strengthens overall system reliability


