
Mastering Complex Progressive Delivery Challenges with Lightrun
May 21, 2023


Introduction
Progressive delivery is a modification of continuous delivery that allows developers to release new features to users in a gradual, controlled fashion.
It does this in two ways.
Firstly, by using feature flags to turn specific features ‘on’ or ‘off’ in production, based on certain conditions, such as specific subsets of users. This lets developers deploy rapidly to production and perform testing there before turning a feature on.
Secondly, they roll out new features to users in a gradual way using canary releases, which involves making certain features available to only a small percentage of the user base for testing before releasing it to all users.
Practices like these allow developers to get incredibly granular with how they release new features to their userbase to minimize risk.
But there are downsides to progressive delivery: it can create very complex code that is challenging to troubleshoot.
Troubleshooting Complex Code
Code written for progressive delivery is highly conditional. It can contain many feature flag branches that respond differently to different subsets of users based on their data profile or specific configuration. You can easily end up with hard-to-follow code composed of complex flows with many conditional statements.
This means that your code becomes very unpredictable. It’s not always clear which code path will be invoked as this is highly dependent on which user is active and in what circumstances.
The difficulty comes when you discover an issue, vulnerability or bug that is related to one of these complex branches and only occurs under certain very specific conditions. It becomes very difficult to determine which code path contains the bug and what information you need to gather to fix it.
This becomes a major barrier to identifying any problems and resolving them effectively.
The Barriers To Resolving Issues In Progressive Delivery
When a problem arises in this complex progressive delivery context, your developers can spend a huge amount of time trying to discern the location and nature of the actual problem amidst all the complexity.
There are three main ways this barrier manifests:
-
Parsing conditional statements in the code path
Developers have to determine the actual code path that is being executed when the problem arises, a non-trivial issue when there are many different feature flags that are being conditionally triggered by different users in unpredictable ways.
Among all these different possibilities it is very hard to determine which conditional statements will run and therefore to statically analyze the code path that will be executed.
Developers have to add new logs to track the flow of code, forcing them to redeploy the application. Sometimes many rounds of logging/redeployment is required before they get the information they need, which is incredibly time-consuming.
-
Emulating the production environment locally
Secondly, once the right code path has been isolated, they have to replicate that complex, conditional code on their local machine to test potential fixes.
But if there are many feature flags and conditional statements, it is very hard to emulate that locally to reproduce and assess the problem given the complexity of the production environment.
A huge amount of time and energy is needed to do this, with no guarantee that you will be able to perfectly replicate the production environment.
-
Generating synthetic traffic that matches the user profiles
Thirdly, when the code path that is executed is highly dependent on specific data (e.g. user data) it is hard to simulate the workloads synthetically in order to properly test the solution in a way that accurately mirrors the production environment.
Yet more time and energy must be expended to trigger the issue in the test environment in a way that gives developers the information they need to properly resolve the issue.
Using Lightrun to Troubleshoot Progressive Delivery
Developer time is extremely valuable. They can waste a lot of time dealing with these niggling hurdles to remediation that could be spent creating valuable new features.
But there is a new approach that can overcome these barriers: dynamic observability.
Lightrun is a dynamic observability platform that enables developers to add logs, metrics and snapshots to live applications—without having to release a new version or even stop the running process.
In the context of progressive delivery, Lightrun enables you to use real-time dynamic instrumentation to:
- Identify the actual workflow affected by the issue
- Capture the relevant information from that workflow
This means that you can identify and understand your bug or vulnerability without having to redeploy the application or recreate the issue locally, regardless of the complexity of the code.
There are two features of Lightrun that are particularly potent in this regard: Lightrun dynamic logs and snapshots.
Dynamic Logs
You can deploy dynamic logs within each feature flag branch in real-time, providing full visibility into the progressive delivery process without having to redeploy the application.
Unlike regular logging statements which are printed for all requests served by the system. Dynamic logging can target specific users or user segments, using conditions, making them more precise and much less noisy
If there’s a new issue you want to track or a new feature flag branch you want to start logging, you can just add it on the fly. Then you can flow through the execution and watch your application’s state change with every flag flip using real user data, right from the IDE, without having to add endless ‘if/else’ statements in the process.
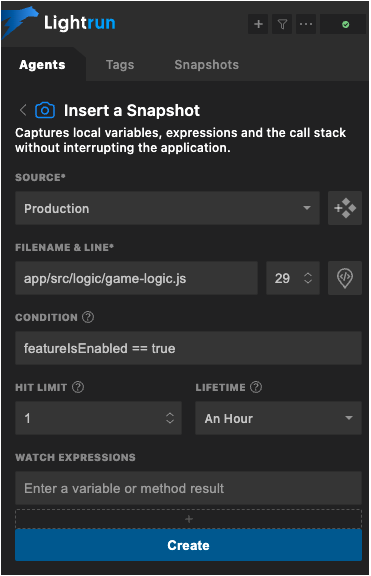
Granular Snapshots
Similarly, you can place Snapshots – essentially virtual breakpoints – inside any flag-created branch, giving you debugger-grade visibility into each rollout. This gives your developers on-demand access to whatever information they need about the code flows that are affected by your issue.
All the classic features you know from traditional debugging tools, plus many more, are available in every snapshot, which:
- Can be added to multiple instances, simultaneously
- Can be added conditionally, without writing new code
- Provides full-syntax expression evaluation
- Is safe, read-only and performant
- Can be placed, viewed and edited right from the IDE
By enabling your developers to track issues through complex code and gather intelligence on-demand – all without having to redeploy the app or even leave the IDE – makes troubleshooting progressive delivery codebases much easier.
Developer Benefits Of Using Lightrun
-
Determine which workflow is being executed during a given issue
Developers can identify exactly which workflow is relevant. This means they no longer have the hassle of troubleshooting sections of code that are not vulnerable because they are not being executed or redeploying the application to insert log messages to track the code flow.
-
No need to locally reproduce issues
By dynamically observing the application pathways at runtime, you avoid the need to invest significant time and energy into reproducing your production environment locally along with all the complexity of feature flags and config options.
-
No need to create highly-specific synthetic traffic
Similarly, there is no need to emulate customer workloads by creating highly conditional synthetic traffic to trigger the particular code path in question.
Overall, developers can save a huge amount of time and energy that was previously being sunk into investigating complexity in different ways.
Final Thoughts
Dynamic observability gives you much deeper and faster insights into what’s going on in your code.
With Lightrun’s revolutionary developer-first approach, we enable engineering teams to connect to their live applications and continuously identify critical issues without hotfixes, redeployments or restarts.
If you need a hand troubleshooting complex code flows or dealing with highly conditional progressive delivery scenarios, get in touch.


