
5 Approaches to Deep Learning Clustering You Really Need to Know
Dec 12, 2022


Data has become the most valuable thing in the modern world. According to earthweb, more than 2.5 quintillion bytes of data will be created every day in 2022. These large quantities of data should be appropriately organized to identify meaningful patterns for decision-making.
Techniques like clustering are widely used to efficiently collect data into groups based on their similarities and differences and improve the observability of your data. Moreover, clustering based on deep learning helps you discover new depths in data by finding complex data patterns. This article will introduce you to clustering and five approaches for deep learning clustering in practice.
What is clustering or cluster analysis?
Clustering is an unsupervised learning technique used for data classification. It gathers data points into small clusters by analyzing their similarities and differences. Although this sounds simple, this approach can play a significant role in customer segmentation, search result analysis, social media analysis, image segmentation, anomaly detection, etc.
If we consider customer segmentation as an example, it helps the organization identify buying patterns, brand loyalty, and spending ranges of customers to restock their shops accordingly.
Likewise, clustering can have a significant impact on the decisions taken by an organization to improve its processes.
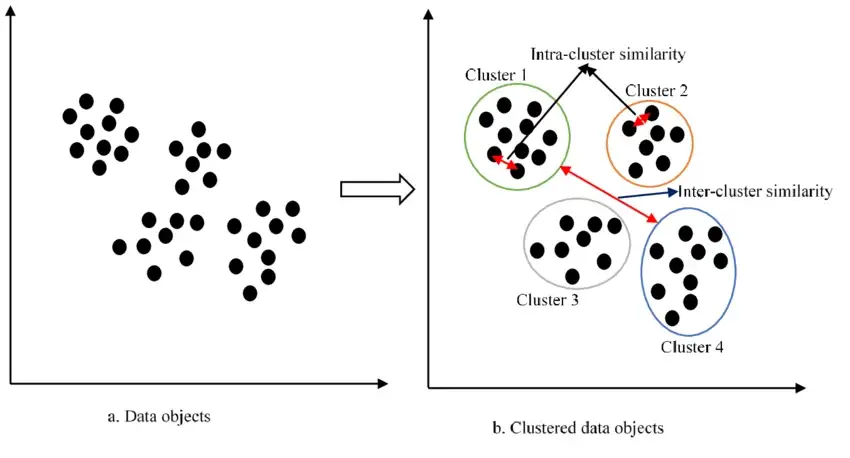
Deep learning clustering vs. traditional clustering
In traditional clustering methods like k-means, hierarchical or self-organizing maps are used to identify the data patterns. Most of the time, these approaches are suitable when in-depth data analysis is not required. However, traditional clustering techniques are unsuitable for large and high-dimensional datasets since they cannot identify complex patterns.
On the other hand, deep learning clustering uses deep clustering networks, deep adaptive clustering, and deep embedded clustering to perform in-depth analysis in large datasets. As a result, deep learning clustering can identify complex and hidden patterns in data more efficiently.
In addition, regression and classification can also be used for data organizing. Hence, people often get confused between these techniques with clustering. However, compared to clustering, regression and classification are supervised learning techniques. So, you need to label data to use regression and classification.
5 Approaches to deep learning clustering you really need to know
Since now you understand what clustering is and how deep learning clustering is different from traditional clustering, let’s discuss five deep learning clustering approaches every developer should know.
1. Deep Clustering Network (DCN)
In deep clustering networks, an autoencoder is used to learn the data representations manageable to the K-means algorithm. An autoencoder is another unsupervised learning technique that trains neural networks efficiently, ignoring the noise. Here, DCN pre-trains the autoencoder and uses it to optimize the reconstruction loss and K-means loss while changing the cluster assignments.
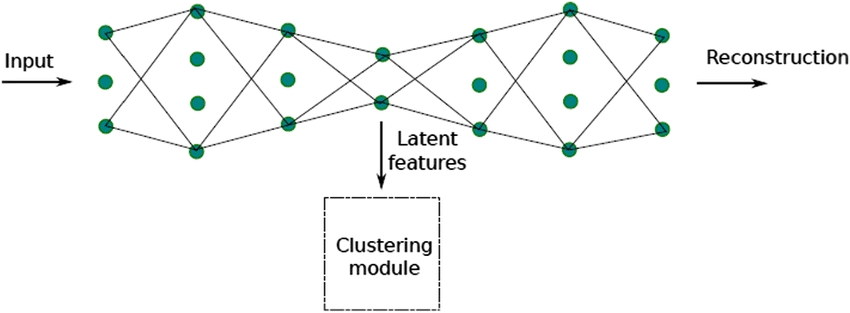
2. Deep Adaptive Clustering (DAC)
Deep adaptive clustering is another widely used deep learning clustering approach, which uses a pairwise binary classification framework to create clusters.
It takes two data points as inputs and decides whether they belong to the same cluster or not. Underneath is a neural network with softmax activation, which takes the data points and produces the probabilities of an input belonging to a given cluster. If the dot product of the two outputs from the data pair is 0, they belong to the same cluster. If the dot product is 1, the pair of data points belong to different clusters.
3. Deep Embedded Clustering (DEC)
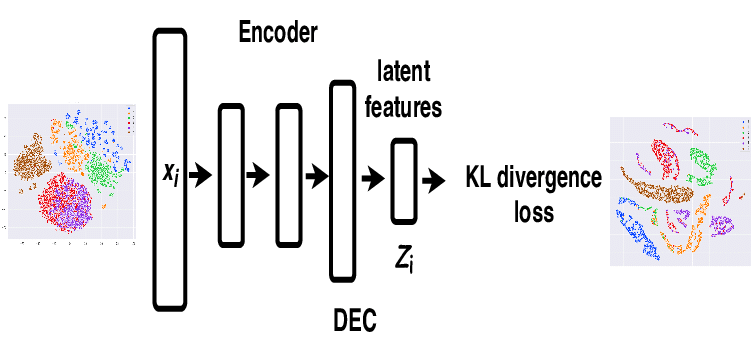
Deep-embedded clustering is considered the benchmark for comparing the performance of the deep learning clustering approaches. It uses deep neural networks to learn feature representations and cluster assignments continuously. In addition, it optimizes the clustering objectives by mapping the data space to a lower-dimensional feature space.
In DEC pre-training, encoder and decoder parameters are initialized for a few epochs with reconstruction loss. After that, the encoder network is removed, and the decoder network is fine-tuned by optimizing KL divergence between soft cluster assignment and auxiliary distribution. Overall, DEC is a self-training clustering process that continuously refines the data representations while performing cluster assignments.
4. Information Maximizing Self-Augmented Training (IMSAT)
In information maximization, clusters are created by balancing the number of data points in the clusters. It only considers the regularization penalty on the model parameters to ensure the cluster assignment.
Information maximizing self-augmented training, or IMSAT, modifies information maximization by combining it with self-augmentation training techniques that penalize the data representation differences between the original and augmented data points.
In IMSAT, you can follow random perturbation or virtual adversarial to expand the data. If you choose random perturbation training, a random deviation will be added to the input from a predefined noise distribution. On the other hand, when selecting virtual adversarial training, the deviation will be assigned so that the model cannot assign it from the same cluster.
In addition to clustering, this approach is also used in hash learning.
5. Variational Deep Embedding (VaDE)
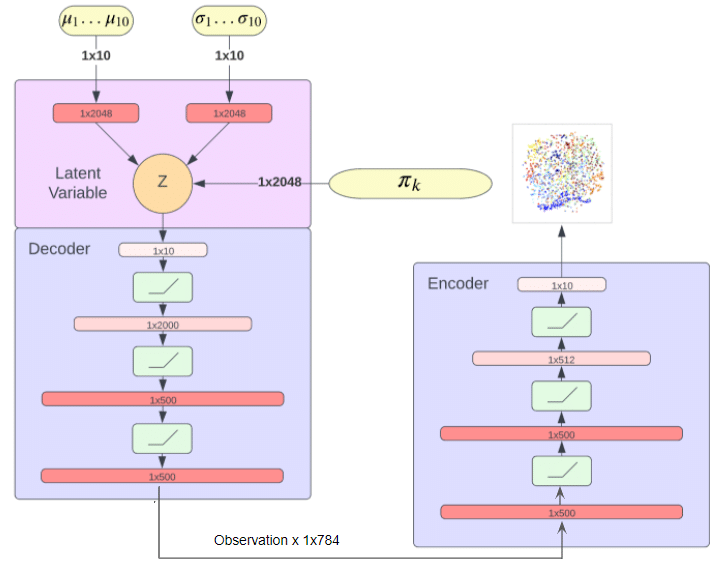
Variational Deep Embedding (VaDE) is a 4-step data generation process that uses deep neural networks and a Gaussian Mixture Model. It generalizes the Variational autoencoder (VAE) model by replacing its single gaussian with a Gaussian Mixture Model. Ultimately, it makes the VaDE more suitable for clustering than VAE by minimizing the reconstruction loss.
First, it allows the Gaussian Mixture Model to pick a cluster for the data point. Then a latent embedding is generated based on the picked cluster. After that, the deep neural network will decode the latent embedding into an observation. Finally, the evidence lower bound of the VaDE is maximized using an encoder network.
Next steps
The five approaches discussed in this article should help you to perform deep learning-based clustering to find the hidden pattern in your datasets more efficiently. However, handling and debugging large datasets while clustering is a challenging task. It is always more beneficial to use a tool like Lightrun to automate some of your work. Lightrun enables you to add logs, metrics, and traces to your Big Data workers and monitor these in real time while your app runs. You can find more details on how Lightrun works by requesting a demo.


