
What Is an AI SRE? And Why Do They Need Live Runtime Evidence?
Apr 15, 2026


AI SREs are autonomous systems that handle incident triage, root cause analysis, and remediation by correlating logs, metrics, traces, and code signals. However, as they rely on pre-configured telemetry, the critical execution details of a specific failure, such as variable state and code paths, can often be missed. As a result, they either force users into manual redeploy loops or make inferences from partial data, diagnosing issues using probability rather than proof.
TL;DR
- Most AI SREs triage alerts and correlate existing telemetry and other data sources, but cannot generate new evidence from live running code at the moment of failure.
- When the exact runtime signal is missing, the AI does not stop; it infers. In the presence of non-deterministic failures, inference produces ranked guesses rather than proven root causes.
- The new bottleneck in software delivery is not writing code; it is verifying that code behaves correctly under real traffic, real data, and real dependencies.
- Runtime context is the missing layer: live visibility into execution paths, variable state, and conditions at the exact moment of failure on demand, without redeployment.
- Lightrun’s AI SRE generates missing evidence on demand, proving root causes through live execution rather than estimating from historical patterns.
A team deployed an AI SRE to reduce operational load and improve incident response. Alerts became more relevant, noise decreased, and on-call improved as the system automatically correlated signals across the observability stack.
When a critical incident occurred, the AI analyzed logs, traces, and recent deployments, returning a ranked set of hypotheses within seconds. One of them was correct, but it could not determine which. The team spent hours validating incorrect paths before reaching the root cause.
This was not a failure of reasoning, but of visibility. The AI could only operate on available telemetry, which lacked the execution-level signals needed to conclusively explain the failure. This gap between static telemetry and actual runtime behavior is the visibility problem in modern reliability systems.
In this blog, we examine how SRE (site reliability engineering) has become increasingly difficult to apply at scale in modern distributed systems and where AI SREs fit into this landscape. We explore how these AI tools operate across the incident lifecycle, why they often produce hypotheses rather than proven answers, and what changes when root cause analysis is grounded in live runtime evidence rather than inferred from incomplete data.
What Is Site Reliability Engineering (SRE)?
Site reliability engineering is the discipline of applying software engineering principles to operations. It originated in Google in 2003, and is credited to Ben Treynor Sloss, as part of Google’s effort to manage the growing complexity of large-scale distributed systems, where traditional approaches such as manual runbooks, siloed on-call rotations, and reactive firefighting no longer scaled effectively.
Instead of treating reliability as an operational concern, SRE reframes it as an engineering problem, applying the same rigor, automation, and measurement practices used in software development.
In practice, SRE spans a set of responsibilities that work together to maintain system reliability. These typically include:
- Capacity planning and resilience testing, ensuring systems can scale and behave predictably under stress
- SLO and SLA management, defining and measuring reliability expectations for services
- Incident response, where engineers triage alerts, investigate failures, and coordinate resolution
- MTTR reduction, focusing on minimizing the time required to restore system health
- Postmortems and toil reduction, learning from failures, and eliminating repetitive operational work
While these responsibilities describe what SRE teams do, they are guided by a set of core principles that define how they operate. In Google’s SRE model, reliability is treated as an engineering problem rather than an operational burden. This includes maintaining a strong focus on engineering work over manual operations, enforcing limits on operational toil, and designing systems that minimize the need for human intervention.
SRE teams are accountable for availability, latency, performance, efficiency, monitoring, incident response, and capacity planning, but they achieve this by building automation and improving system design rather than scaling manual effort. In practice, this means they are measured not by how well they respond to incidents, but by how effectively they eliminate the conditions that cause them.
Where SRE Breaks Down at Scale
Each of these responsibilities is manageable in isolation. The challenge emerges at scale when they all occur simultaneously and compete for attention.
An incident demands immediate response while capacity planning is still in progress. Operational toil accumulates faster than it can be reduced. SLOs begin to degrade while teams are still resolving previous failures. What were once discrete responsibilities start to overlap, creating constant contention for time, context, and focus.
As systems grow, so does the volume of alerts, the diversity of failure modes, and the number of dependencies between components. The result is not just more data, but more fragmentation, making it increasingly difficult to build a complete and reliable picture of what is happening during a failure.
Engineers are pulled into continuous context switching between systems, tools, and teams, balancing operational work with product development. Over time, this erodes efficiency and slows down decision-making.
At this point, reliability doesn’t break because teams lack expertise; it breaks because no human can hold the full system in their head.
This is the environment in which AI SREs emerged, designed to absorb this growing complexity. However, as we’ll see, not all of them address the underlying problem in the same way.
What Is an AI SRE?
An AI SRE is an autonomous system that manages the full site reliability engineering lifecycle, including monitoring, triage, root cause analysis, fix proposal, and postmortem generation, without requiring constant human direction.
Its defining characteristic is autonomy. Unlike a copilot that surfaces information and depends on human action, an AI SRE makes decisions, takes actions, and drives incidents toward resolution based on its own reasoning.
Unlike static automation, which follows predefined workflows and breaks when systems change, an AI SRE can adapt to new conditions and reason through failures it has not encountered before.
In practice, an AI SRE integrates with the existing engineering stack rather than replacing it. It connects to monitoring systems such as Datadog, Grafana, Prometheus, and New Relic; alerting platforms like PagerDuty and OpsGenie; and logs, traces, code repositories, and ticketing systems.
By operating across all of these simultaneously, it processes large volumes of signals, maintains context across the incident timeline, and correlates changes and anomalies that would otherwise require significant manual effort to uncover.
At a high level, an AI SRE is responsible for:
- Signal correlation, combining logs, metrics, traces, and deployment data into a unified view
- Incident investigation, identifying affected services, and narrowing down potential causes
- Root cause analysis, reasoning across system behavior to explain failures
- Remediation support, proposing and validating fixes before they impact users
- Postmortem generation, capturing timelines, causes, and preventive actions
The effectiveness of any AI SRE is fundamentally bounded by the completeness of the data it can access. It cannot generate insights from signals that it does not have access to.
When the runtime evidence required to identify a root cause is missing, the system does not pause; it infers from available telemetry. While this can be sufficient for predictable failures, it breaks down in the complex, non-deterministic scenarios that typically drive high-severity incidents.
The gap between what an AI SRE can infer and what it can prove comes down to one thing: whether it can see what is actually happening inside the running system at the moment of failure. For a closer look at how runtime-aware AI SRE agents are built to close that gap, see how runtime-aware AI SRE agents operate in practice.
How an AI SRE Works: The Incident Lifecycle
When an incident occurs, an effective AI SRE follows a structured sequence from the first signal to the postmortem. Each stage serves a distinct purpose, and together they define how incidents are received, understood, and resolved. This progression also highlights where AI delivers the most value and where data completeness determines whether the outcome is a hypothesis or a proven root cause
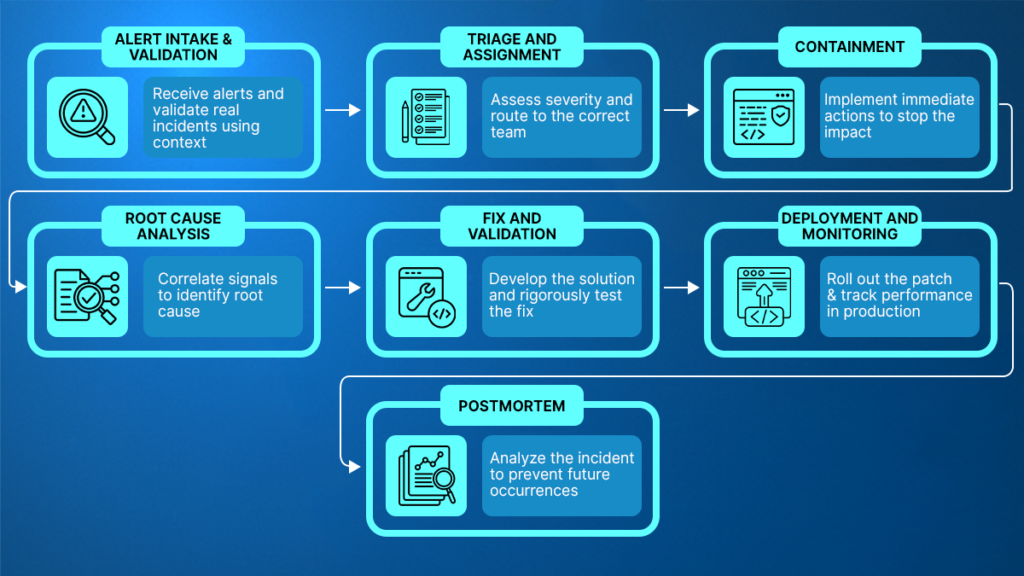
Stage 1: Detection and Intake
The AI SRE begins with an incoming alert from monitoring or alerting systems. It validates that the alert represents a real issue rather than noise, and classifies its severity based on service impact and user-facing effects.
It then enriches the incident with relevant production context logs, metrics, traces, and recent changes before a human engages, removing the manual triage step that typically delays initial response.
Stage 2: Triage and Assignment
With context already established, the AI SRE identifies the affected services, correlates known patterns and prior incidents, and determines whether the issue originates from infrastructure or application behavior. The incident is then routed with sufficient context, allowing engineers to begin with clarity rather than investigate from scratch.
Stage 3: Containment
Before confirming the root cause, the AI SRE prioritizes stabilizing the system. It identifies the fastest reversible mitigation, such as a rollback, feature flag adjustment, or configuration change, and validates its impact using live telemetry, ensuring the system is contained while the investigation continues.
Stage 4: Root Cause Investigation
This is the most critical stage, where data completeness directly affects the outcome. The AI SRE correlates logs, metrics, traces, and deployment history to narrow down the root cause of the failure. Systems limited to pre-configured telemetry converge on hypotheses, while systems with runtime evidence can converge on a verified root cause. The difference between these approaches is reflected in the time required to resolve the incident.
Stage 5: Fix and Validation
Once the root cause is identified, the AI SRE proposes a fix based on its analysis of system behavior, code changes, and historical patterns.
In most AI SRE systems, validation is performed using available telemetry, test environments, or inferred outcomes, ensuring the proposed fix is directionally correct before deployment.
More advanced systems, with access to live execution behavior, can validate the fix against real runtime conditions in a controlled environment. This allows them to confirm that the change resolves the issue under actual production scenarios before it is applied, improving both accuracy and safety.
Stage 6: Deployment and Monitoring
After deployment, the AI SRE introduces temporary instrumentation to verify that the failure condition has been fully resolved, not just that surface-level metrics have improved. Once stability is confirmed, this instrumentation is removed to maintain system efficiency.
Stage 7: Postmortem
Finally, the AI SRE generates a complete incident record, including timeline, confirmed root cause, supporting evidence, and recommended follow-up actions. Each incident becomes a source of learning, feeding into improved reliability over time.
Why Most AI SREs Infer Rather Than Prove
When an AI SRE returns multiple plausible root causes instead of a single definitive answer, the limitation is not intelligence, but data completeness. When the required runtime evidence is missing, even the most advanced systems cannot produce a definitive answer and instead generate the most likely explanation based on available signals.
Understanding why this happens and why it becomes critical in certain classes of failures is key to evaluating any AI SRE platform.
The Limitations of Static Telemetry
All monitoring systems rely on telemetry that is configured when code is deployed. Dashboards are defined in advance, log levels are set at deployment, and sampling strategies are tuned for normal operating conditions. This data is valuable for detecting anomalies and narrowing down areas of investigation, but it is limited to what engineers anticipated.
What static telemetry cannot provide is execution-level visibility at the moment of failure. It does not capture which variable held an invalid value, which code path was executed, or how a dependency behaved under exact runtime conditions.
When this information is missing, teams are forced into a familiar redeploy loop:
- Identify the failure and recognize missing signals
- Add instrumentation to the codebase
- Redeploy through change management
- Wait for the issue to reproduce
- Evaluate whether the new data is sufficient
- Repeat if necessary
In regulated environments, where every deployment requires approval and auditability, each iteration is not just a delay, but an expensive organizational risk.
The Problem of Non-Deterministic Failures
Non-deterministic failures are often referred to as “Heisenbugs” issues where the same set of inputs does not consistently produce the same output. Unlike deterministic bugs, which follow predictable patterns (for example, a null pointer that fails every time a function is called), these failures are triggered by transient runtime conditions such as thread interleaving, network jitter, or race conditions.
Because these conditions are short-lived and environment-specific, the failure may disappear the moment you try to observe or reproduce it. This makes them inherently difficult to capture with pre-configured telemetry.
Production failures are often influenced by combinations of timing, resource constraints, and service interactions that cannot be fully reproduced in controlled environments. A race condition may exist only under specific concurrency patterns, a memory issue may surface only when load crosses a threshold influenced by upstream systems, and a dependency failure may occur only under a rare combination of latency and traffic conditions.
The critical issue is not just complexity, but observability. The conditions that trigger these failures often exist only briefly and may not be captured at all.
The difference between deterministic and non-deterministic failures is not just behavior, but observability.
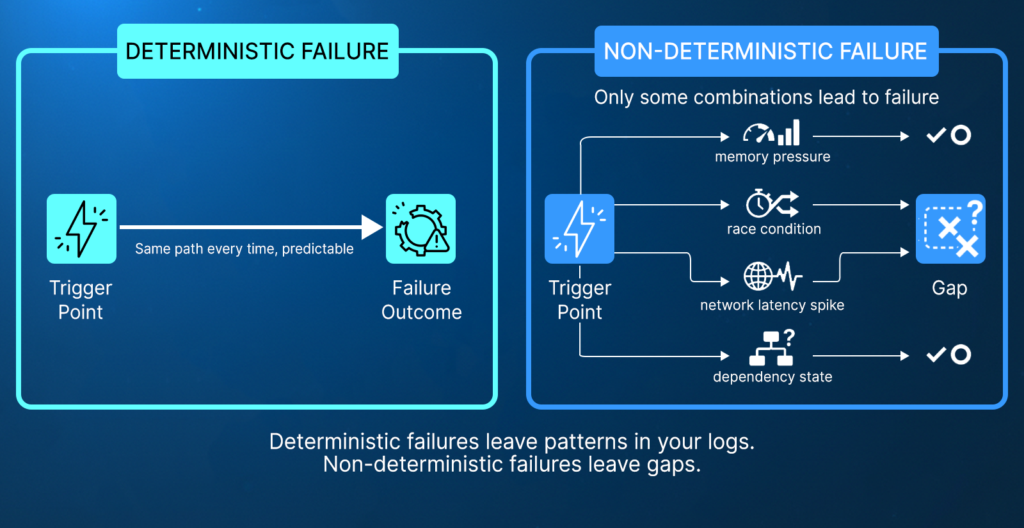
- Deterministic failures tend to leave consistent patterns in logs, metrics, and alerts, making them easier to diagnose.
- Non-deterministic failures, by contrast, often leave gaps. The signal is incomplete, fragmented, or entirely absent at the point where it matters most.
Why AI SREs Produce Hypotheses Instead of Proof
AI SRE systems are highly effective at correlating existing telemetry and identifying patterns across large volumes of data. For predictable failures, this capability is often sufficient to quickly reach a correct diagnosis.
However, the failures that consume the most engineering time, race conditions, memory issues under specific traffic patterns, and edge cases driven by real production behavior are precisely the ones where telemetry is incomplete.
This isn’t only theoretical; the lack of visibility into live production behavior consistently emerges as the primary bottleneck in incident resolution, with 60% of enterprise engineering leaders citing it as their main issue, according to Lightrun’s State of AI-Powered Engineering 2026 Report.

When that visibility is missing, investigations don’t just slow down; they fail, the same survey of Directors and VPs overseeing engineering organizations found that 44% of AI SRE and APM investigations failures were due to missing execution-level data.
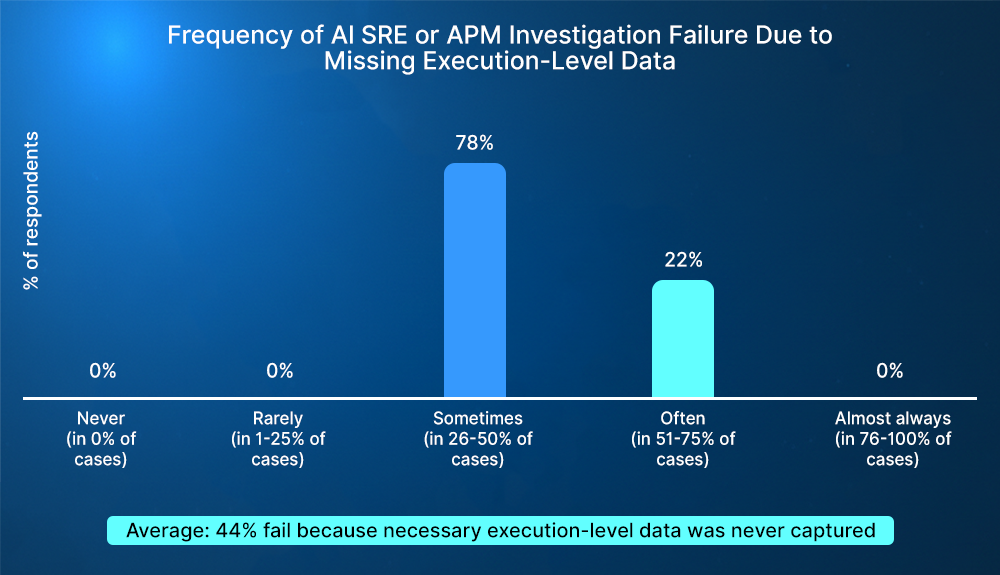
In these scenarios, the AI is not failing. It is operating within the limits of its data. When key runtime signals are missing, multiple explanations remain plausible, and no single hypothesis can be conclusively validated.
Investigations fail not because the signals are noisy, but because the required execution-level data was never captured in the first place.
As a result, the system infers. It produces ranked hypotheses based on probability because it cannot directly observe what happened inside the running system at the moment of failure.
The Solution: Sandboxed Runtime Instrumentation
Instead of relying on the “Static Telemetry Ceiling,” a runtime-aware AI SRE (like Lightrun AI SRE) generates missing evidence on demand. Instead of relying on pre-existing telemetry, it injects snapshots, metrics, and traces into live systems at the moment of failure, without redeployment, in secure, read-only sandboxed environments.
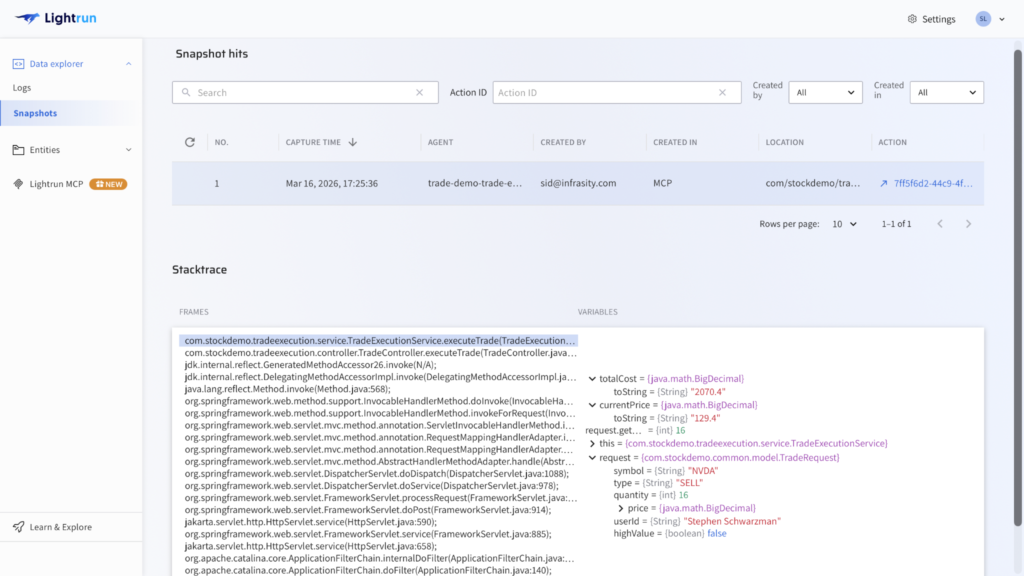
This approach captures the ground truth of the failure. The exact variable states, execution paths, and real-time dependency behaviors. By operating directly within the running service, it fills the gaps left by pre-configured telemetry and enables root-cause analysis grounded in observed execution rather than probabilistic inference.
In practice, this includes:
- Capturing snapshots with full variable state and execution context
- Generating metrics and traces on demand for specific code paths
- Ensuring all instrumentation is sandboxed, read-only, and fully reversible
For non-deterministic failures, this is not an incremental improvement; it is a fundamental shift in debugging work. The problem moves from selecting the most likely hypothesis to identifying a single, evidence-backed root cause.
For a deeper explanation of runtime context and its role in modern systems, see: What is Runtime Context? A Practical Definition for the AI Era
AI SRE in Peace Time: Reliability Before Incidents
Most AI SRE systems are designed as wartime tools: they activate when an alert fires and disengage once the incident is resolved. This treats reliability as a reactive firefighting exercise. Lightrun takes a different approach by extending reliability into earlier stages of the software lifecycle.
In peacetime, Lightrun’s MCP interface with AI coding agents provides live runtime context across design, development, code review, and pre-production validation. This allows teams to validate assumptions against actual execution behavior before issues occur, rather than relying solely on static analysis or inferred signals. In practice, this means AI assistants can reason about real system behavior directly in IDEs, improving both code quality and engineer confidence before deployment.
This proactive shift enables teams to:
- Validate execution: See how the code behaves under real-world conditions before deployment.
- Ground AI-generated code: Ensure logic is based on runtime behavior instead of AI assumptions or outdated documentation.
- Identify edge cases early: race conditions and unexpected dependency interactions before they translate into costly production incidents.
This is especially important for failures that only emerge under real traffic and system conditions, many of which cannot be reproduced in staging environments and are discovered only once users encounter them. As development velocity increases with AI-generated code, the constraint in software delivery has shifted from writing code to verifying that it behaves correctly under real conditions.
The impact of this gap is already visible in production systems, where teams spend hours diagnosing issues that could have been validated earlier. Approaches that bring runtime evidence into both development and incident workflows have shown how teams can reduce MTTR with AI-powered runtime diagnosis.
Reliability, therefore, cannot remain a reactive discipline applied only during incidents. It must become continuous, integrated into every stage of the SDLC from initial design through production. To explore this approach further, see how runtime context is integrated directly into development workflows.
Proof, Not Guesswork: Real Outcomes
When you move from inference to runtime proof, the metrics follow. Here is how that looks in practice:

From Hours to Minutes
A global telecommunications enterprise was handling P1 incidents through large war rooms, with engineers spread across dashboards, logs, and traces. The process relied on selecting and validating hypotheses one at a time, which made resolution slow and unpredictable.
The limitation was not expertise, but evidence. Without execution-level visibility, teams were forced to rely on correlation instead of proof.
With Lightrun’s AI SRE, this changed fundamentally. Runtime instrumentation was applied directly at the failure point, allowing engineers to see exactly what failed, where it failed, and why, without iterating through multiple hypotheses.
Result:
- 90% reduction in MTTR
- From 5 hours → 30 minutes
- War rooms were effectively eliminated
As shown, teams can reduce MTTR with AI-powered runtime diagnosis; grounding analysis in runtime evidence removes the need for iterative debugging.
Engineering Time Reclaimed
A large-scale content platform running thousands of services was constrained by the redeploy loop. Debugging required adding instrumentation, redeploying, waiting for failures to reproduce, and repeating the process until sufficient data was captured.
At scale, this made investigations slow and resource-intensive, often taking days or weeks while engineering time was diverted away from building.
With runtime instrumentation applied directly in production, this loop was eliminated. Engineers could capture logs, snapshots, and traces instantly at the point of failure, without modifying code or waiting for recurrence.
Result:
- Investigations reduced from 2 weeks → 2 hours
- 260+ engineering hours reclaimed per month
Speed Without Sacrificing Compliance
For a compliance-driven SaaS platform, debugging in production required every action to be logged, reversible, and auditable. Traditional approaches, such as redeployment or ad hoc instrumentation, introduced delays due to approval and change management processes.
Lightrun’s sandboxed runtime instrumentation enabled real-time investigation while meeting strict compliance requirements. All actions are read-only, fully auditable, and reversible, with no storage of source code or model training on customer data.
Result:
- 30% faster incident response
- Full compliance and auditability maintained
What to Look For in an AI SRE Platform
Not every AI SRE platform is built the same, and the differences that matter most are often not visible in a demo. Evaluating these systems requires looking beyond surface-level capabilities and focusing on how they generate and validate root cause insights.
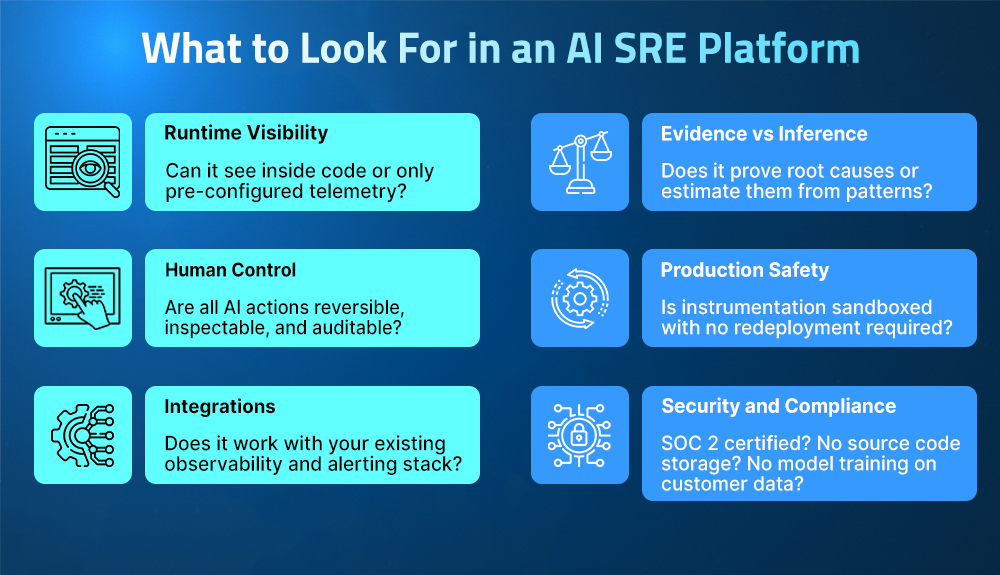
- The first question is whether this AI SRE has runtime visibility.
Every capability an AI SRE offers triage, correlation, and remediation is ultimately constrained by what it can observe. Platforms that rely only on pre-configured telemetry are limited by the gaps in that data. Platforms that can generate runtime evidence on demand remove this constraint entirely.
- The second is whether the model is evidence-based and inference-based.
Many systems can correlate signals and produce likely explanations, but only those with access to live execution context can prove root causes rather than estimate them. This difference becomes critical in complex, non-deterministic failures.
- The third is the degree to which AI actions are secure and controllable.
Teams need to ensure that all AI-driven actions are reversible, inspectable, and auditable, and that instrumentation can be applied without redeployment or risk to production systems.
- Finally, confirm whether the AI SRE meets your data safety and compliance requirements.
Platforms that require source code storage, train on production data, or cannot meet strict data residency constraints are not viable in regulated environments such as financial services, healthcare, and enterprise SaaS.
Lightrun is designed with these constraints in mind. It operates without storing source code or training on customer data, provides full tenant isolation, and ensures all actions are read-only, auditable, and reversible. With certifications such as ISO 27001 and SOC 2 Type II, as well as alignment with GDPR and HIPAA, it meets the requirements of enterprise-scale production environments.
Conclusion
The three-hypothesis problem is not solved by a more capable model. A smarter AI working from incomplete telemetry will only produce a more refined set of guesses. The constraint is not intelligence; it is evidence. When an AI SRE has access to runtime proof, the ambiguity disappears, and root cause analysis shifts from probability to certainty.
This is what separates effective AI SRE systems from those that simply manage alerts. Reliability cannot remain a reactive discipline triggered only during incidents. It must be continuous, starting from development and extending through production. By bringing runtime context into both build-time and runtime workflows, teams can validate behavior earlier, reduce uncertainty during incidents, and avoid the class of failures that are traditionally difficult to reproduce. For a deeper look at how these systems operate in practice, see how runtime-aware AI SRE agents work and how teams can solve issues that cannot be reproduced.
The result is a shift from reactive debugging to continuous reliability. Teams that adopt this approach can runtime-grounded diagnosis, validate fixes before they impact users, and operate with confidence even in complex, non-deterministic systems. To explore how this works in practice, see how Lightrun’s AI SRE and runtime context bring runtime truth into every stage of the software lifecycle.
FAQ
An AI SRE is an autonomous system that manages the full reliability lifecycle, detection, triage, root cause analysis, fix validation, and postmortems, without constant human input. Unlike copilots or static automation, it can act independently, learn, and adapt to new failure scenarios.
Monitoring tools observe systems through logs, metrics, and traces, showing what is wrong. An AI SRE goes further by investigating issues, identifying root causes, and driving resolution. Lightrun’s AI SRE extends this by generating missing runtime evidence on demand rather than just analyzing existing telemetry.
Runtime context is live visibility into how code behaves during execution, including variable state, execution paths, and dependency interactions. It is captured on demand, without redeployment, and provides the evidence needed to diagnose complex, non-deterministic failures.
No. AI SRE is designed to augment human engineers by automating the repetitive, “toil” heavy parts of investigation and triage. This allows teams to focus on high-level architecture and strategic reliability. All AI-driven actions remain inspectable, reversible, and under human control.
Lightrun AI SRE is the first AI SRE built on live runtime context. It generates missing telemetry on demand to prove root causes in real time. It integrates into the full SDLC to validate changes and troubleshoot. It operates with full auditability and offers enterprise-grade security and compliance.


