
Runtime Aware PR Review: Validate Changes in Live Production
Jun 26, 2026 / Updated: Jun 26, 2026


Runtime PR review means validating a code change against live variable state, real execution paths, and downstream service behavior before the merge decision. Not after a checkout regression exposes what the diff missed. As AI coding agents ship PRs faster than any reviewer can mentally simulate execution, static analysis and CI leave a structural gap that only runtime evidence can close. This article explains what that gap looks like, why it recurs, and how to close it with runtime context code review.
Key Takeaways
- The Google Cloud DORA 2025 report documents an almost 10% increase in delivery instability associated with AI adoption.
- According to the State of AI-Powered Engineering 2026 Report by Lightrun, 43% of AI-generated code requires manual debugging in production even after passing QA and staging tests.
- The same report found that 88% of organizations need 2–3 manual redeploy cycles just to confirm that a single AI-generated fix works, consuming on average 38% of developer time per week.
- Runtime-aware PR review closes the reliability gap by simulating execution behavior against live production state before the merge, rather than approximating conditions in staging.
- The Lightrun Runtime-Aware PR Verifier uses the Runtime Sensor to connect AI coding agents to live production state, surfacing variable values, branch decisions, and downstream service behavior at the exact line the PR modifies.
Why Static PR Review Fails AI-Generated Code
Nobody on your team is reviewing carelessly. The problem is simpler and harder to fix: reviewers are approving code without the evidence they need to catch what actually breaks in production.
AI tools have pushed PR volume past the point where any reviewer can mentally simulate execution for every diff. You end up with a confirmation gap between what the code looks like and what it does when it runs.
More PRs, same visibility
The Google Cloud DORA 2025 report puts a number on it: AI adoption coincides with a nearly 10% increase in delivery instability. Reviewers are signing off on code a model generated, validated against tests a model wrote, for a production environment the model has never seen.
According to Lightrun’s State of AI-Powered Engineering 2026 Report, 60% of SRE and DevOps leaders say the lack of runtime visibility is the primary bottleneck when those incidents land.
PR #4281 is a representative example of what this looks like in practice. Four checks pass, two reviewers are assigned, and the diff reads exactly as intended.
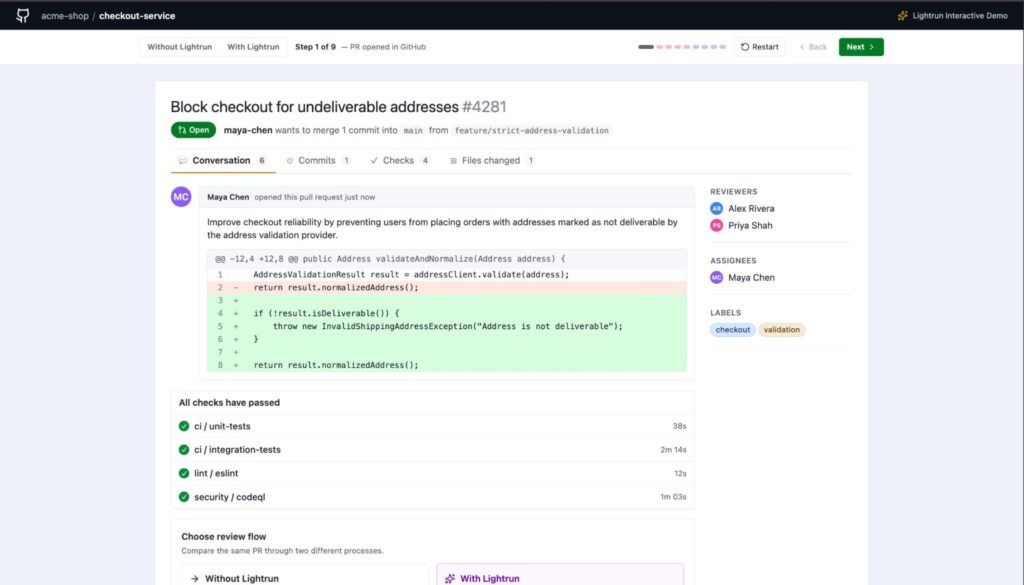
As you can see in the screenshot above:
- All four checks are green and both reviewers are assigned. From a process standpoint, this PR has everything it needs to merge safely.
- The diff shows a straightforward guard against undeliverable addresses. The logic reads correctly because it is correct for every condition the test environment can reach.
A diff shows structure, not behavior
When you review a PR, you see the logic as written, the tests that pass against it, and the style conventions it follows or breaks.
You cannot see which branches actually fire under real traffic, what values live variables hold at the decision point, or how downstream services respond when the change runs.
That information only exists in a running system, and no static tool can reach it.

Why AI-Generated Code Passes Review and Breaks Production
The diff looks clean, the tests pass, and the pipeline is green. Then production exposes what none of those checks could see.
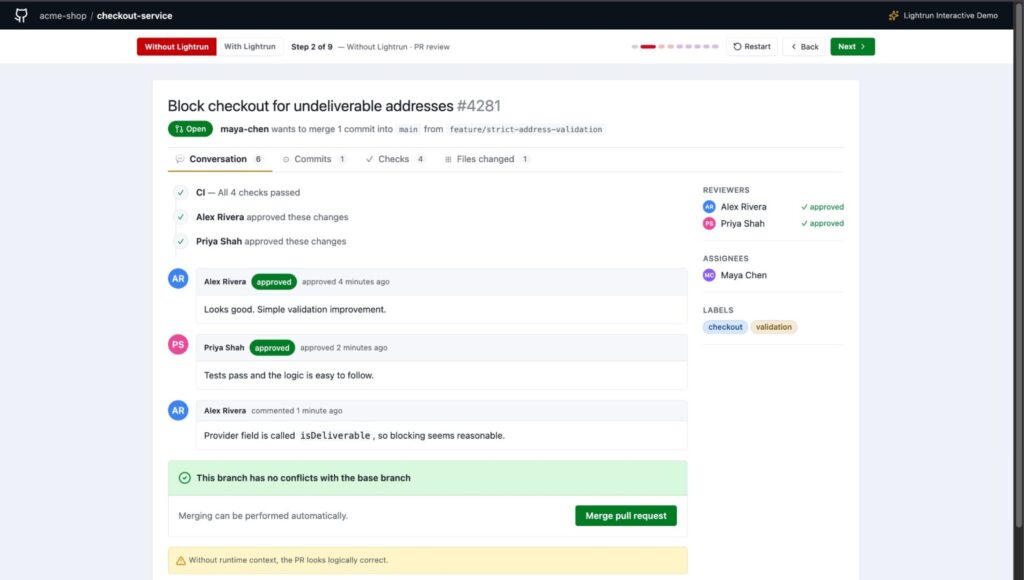
As you can see in the screenshot above:
- Both reviewers approved with substantive comments, not rubber-stamp approvals. The logic genuinely looks correct from the diff.
- The only indication that something is missing appears in the warning banner at the bottom: the review was complete, but it was reviewing structure, not behavior.
Here is what the diff could not show. The PR adds a single guard in CheckoutAddressService.java: if the address validation provider returns isDeliverable=false, throw an InvalidShippingAddressException and block checkout.
In every test environment, the validation provider returns isDeliverable=false only for genuinely undeliverable addresses. That assumption is baked into the test suite.
In production, isDeliverable=false carries several distinct reasons. INVALID_POSTAL_CODE and MISSING_REQUIRED_FIELD are hard failures, meaning the address cannot receive a shipment.
CARRIER_DATA_UNAVAILABLE, ADDRESS_NOT_IN_DELIVERY_DATABASE, and NEW_DEVELOPMENT_AREA are soft signals where delivery is uncertain, but many of those addresses ship successfully and have done so for years. The PR treats both categories identically. The tests never saw the distinction because staging data only included hard failures.
The review was not a failure. The evidence it ran on was too thin for the production reality it was entering.
What Is Runtime-Aware PR Review?
Runtime-aware PR review means validating a code change against live variable state, real execution paths, and downstream service behavior before the merge decision is made.
Static review answers: does this code look correct? Runtime review answers: will this code behave correctly when real production traffic hits it? The checkout incident above demonstrates exactly the gap between those two questions.
The Lightrun Runtime-Aware PR Verifier closes that gap by simulating live production behavior for every code path the PR touches before the merge. Not an approximation in staging, but simulation against the actual execution state from the running production service.
| Review approach | What it can observe | What it cannot observe |
| Static review | Syntax, logic as written, test results, linting violations, known vulnerability patterns | Live variable values, branch decisions under real traffic, downstream service responses, environment-specific state |
| Runtime review | Everything above, plus live execution state at the exact code path the PR modifies, and spec compliance against the original ticket | — |
Those blind spots are not fixable with better static tooling. They are a hard boundary of reviewing code that has never run in the environment it will face.
Four Failure Modes That Always Pass Static Review
These are not rare edge cases. They are categories of failure that appear regularly in production incident reports, and in each case a reviewer approved code with no way to see what would happen at runtime.
1. Code paths that only break under production conditions
Unit tests cover the paths the developer thought to test. They miss the paths that only fire when a carrier database lookup times out, when a feature flag is on for a specific region, or when an address sits in a coverage gap that no test dataset has ever included. The code looks correct from the diff because it is correct for the conditions the tests simulate.
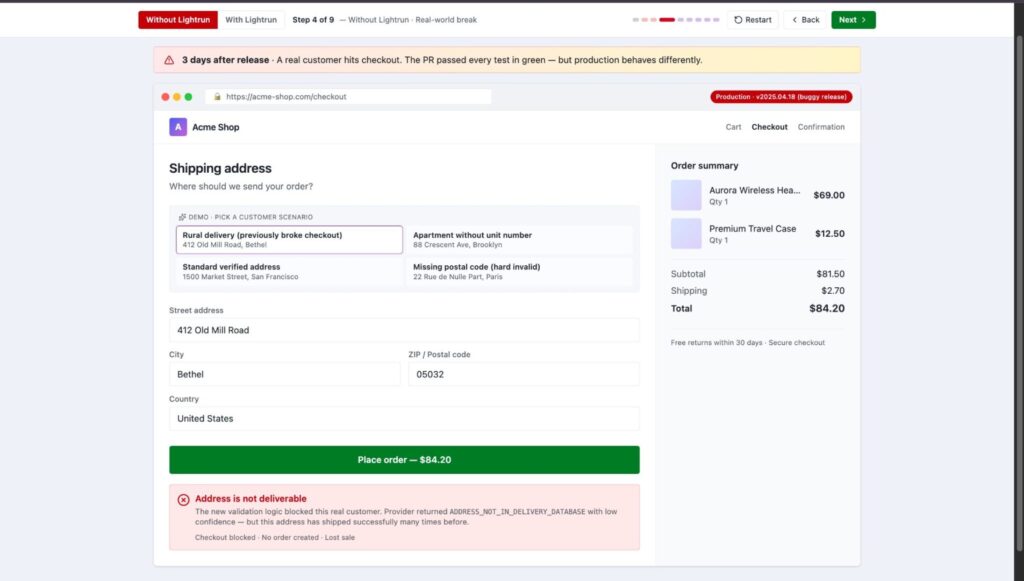
As you can see in the screenshot above:
- The rural delivery address at 412 Old Mill Road, Bethel is a legitimate address with a history of successful deliveries. Nothing in the diff predicted it would break.
- The production label marks the exact buggy release, giving the team a commit to investigate, but the failure is already live and affecting real customers.
2. Type mismatches that cross service boundaries
The reviewer sees a variable used in the changed file. What they cannot see is that an upstream schema change silently altered the type of a value being passed across a service boundary. The source looks correct. The runtime value is wrong. Post-incident, root cause analysis tools spend hours tracing this. Runtime PR review surfaces it before the merge.
3. Downstream behavior you cannot read from the source
A validation provider that returns different reason codes under a new carrier contract. A third-party API that silently expanded its response schema. A sidecar that routes traffic differently in the production namespace than in staging. None of these failures exist in the codebase. They exist in the systems the codebase depends on, and the only way to observe them is from a live environment with real traffic.
4. Spec drift that tests never catch
The PR works correctly as written, but part of the original ticket’s documented assumptions was never validated against real data. The address validation logic passes all tests, but the ticket specified that validation should fail for roughly 1% of users. When the PR’s new logic is simulated against 100 real production samples, it fails for 40%, a 40x regression over the documented assumption that no static tool has any mechanism to detect. The Lightrun Runtime-Aware PR Verifier checks every PR against the originating ticket and flags missing use cases, edge cases, and assumption violations before the merge.
Why Every AI Review Tool Hits the Same Wall
Every AI review tool runs into the same limit eventually: you can only review what you can observe, and none of them can observe execution.
The current generation of AI review tools is genuinely useful. They bring consistency and speed to a process that used to scale only with headcount. But they all share one hard architectural ceiling: you can only review what you can observe, and none of them can observe execution.
- GitHub Copilot Code Review is strong on syntax patterns and known vulnerabilities, but its window is the diff and the surrounding file. It cannot reach the service’s runtime state in which the diff will run.
- CodeRabbit is effective at codebase history and style consistency, operating on a static source with no mechanism to query a live environment. Based on their documented positioning, static analysis catches a significant share of bugs before merge, which means a meaningful proportion still reaches production.
- CI/CD pipelines catch test failures and lint violations. They cannot simulate production traffic patterns, real upstream service states, or the configuration drift that accumulates between environments over time.
This is not a product limitation; it is architectural. The State of AI-Powered Engineering 2026 Report found that 44% of AI SRE and APM tool investigations fail because the agent cannot access the execution-level data it needs; the same holds for PR reviews. No model capability improvement changes that constraint. The context in which these tools are given is structurally incomplete.
The deeper issue is not just what these tools miss. It is what they cannot prioritize. A PR touching a code path that handles 40% of production checkout traffic carries a fundamentally different risk than one touching code that never fires. No static tool can surface that signal because it requires knowing what production traffic actually looks like. The Runtime Sensor can.
There is also a workflow dimension that matters as much as the technical one. Feedback that arrives inside the pull request, in the same thread where the diff lives, gets acted on. Feedback that requires a developer to open a separate tool, check a dashboard, or switch context gets ignored or deferred. The Lightrun Runtime-Aware PR Verifier runs as a native check inside GitHub, GitLab, and Bitbucket. The developer never leaves the PR.
How the Runtime Sensor Connects AI Agents to Live Production
The Runtime Sensor attaches to live running services and generates execution evidence on demand: variable state, branch decisions, call stacks, with no redeployment and no impact on user traffic.
The Lightrun Runtime-Aware PR Verifier runs the Runtime Sensor as a native check inside GitHub, GitLab, and Bitbucket. The entire workflow stays inside the pull request. There is no context switch to an IDE, no separate dashboard to open, and no tool to install locally. The reviewer and the PR author see execution evidence directly in the same interface where they read the diff, leave comments, and make the merge decision.
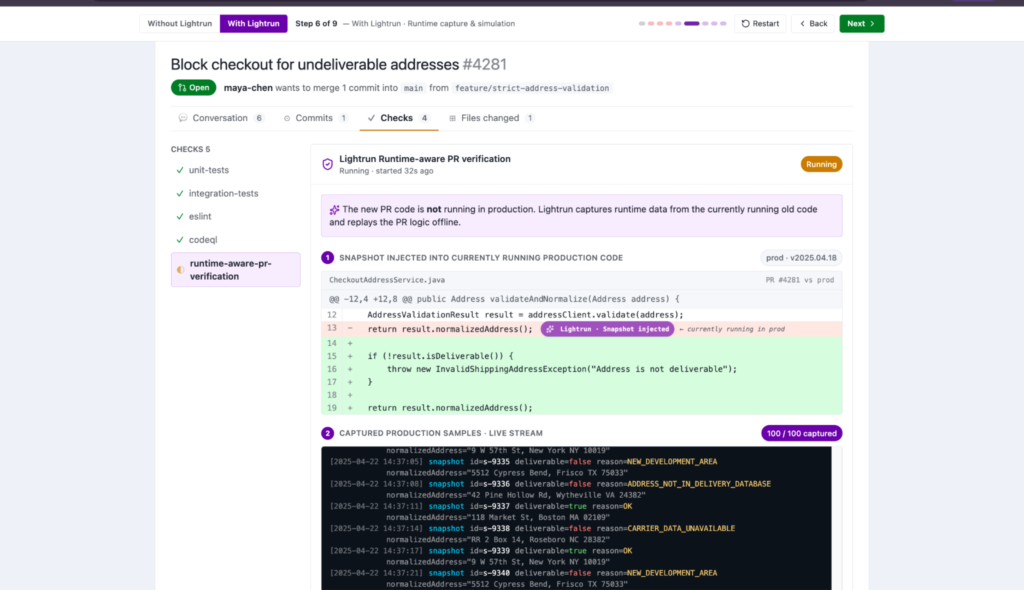
As you can see in the screenshot above:
- The snapshot is injected into the production service running the old code, version v2025.04.18, so the captured samples reflect actual production traffic distribution, not a synthetic dataset.
- The live stream shows a mix of deliverable=true and deliverable=false results with different reason codes including NEW_DEVELOPMENT_AREA, ADDRESS_NOT_IN_DELIVERY_DATABASE, and CARRIER_DATA_UNAVAILABLE, which is the exact signal the PR’s logic could not distinguish from genuine hard failures.
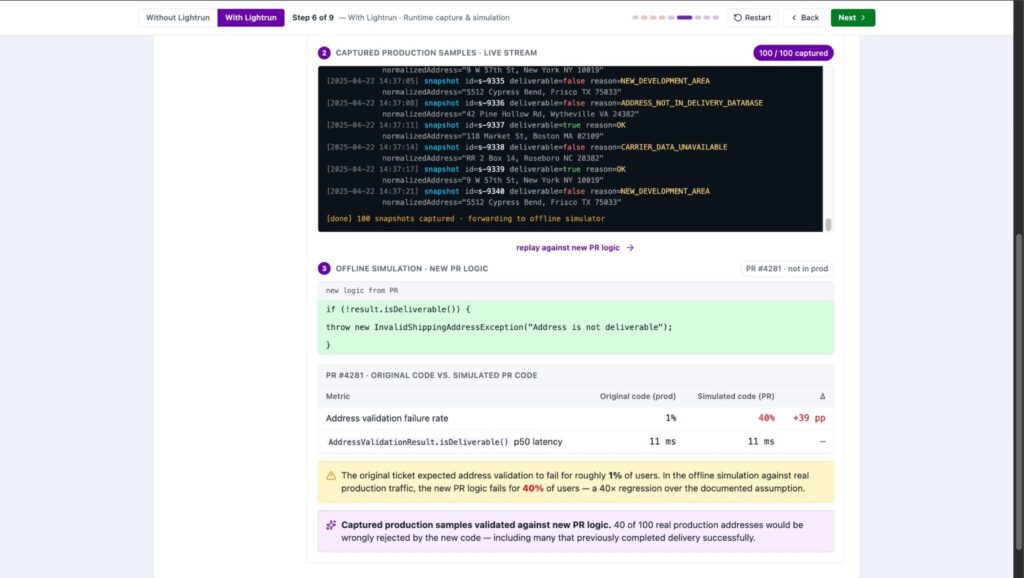
As you can see in the screenshot above:
- The comparison table surfaces what no staging test could: address validation failure rate jumps from 1% in production today to 40% under the new PR logic, while latency stays flat, so the regression would have been invisible to any performance-based alert.
- The simulation result is specific: 40 of 100 real production addresses would be wrongly rejected, including addresses that have previously completed delivery successfully, which means real customers with real order histories would have been blocked at checkout.
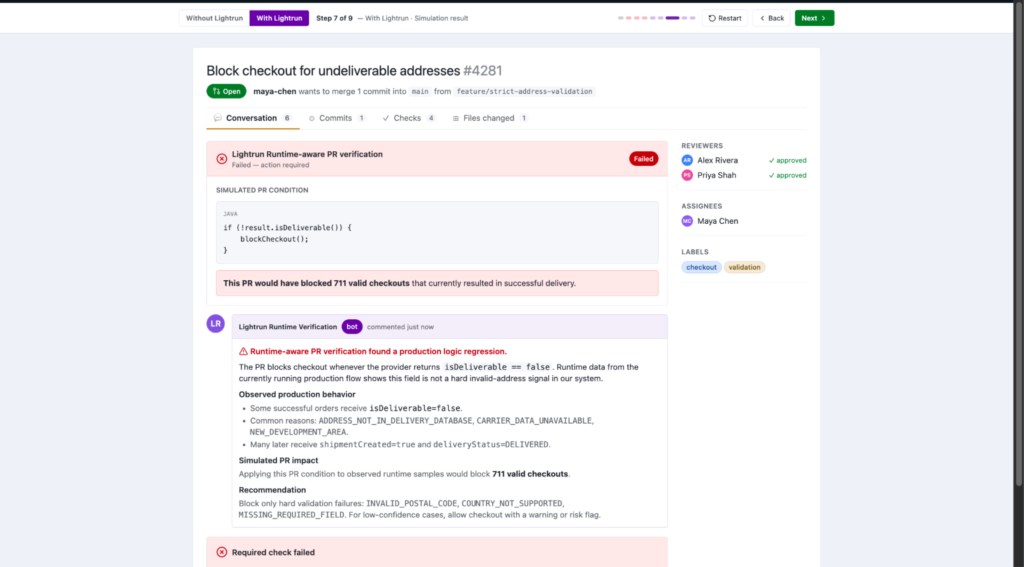
As you can see in the screenshot above:
- The verification result is actionable, not just a failure flag: the bot distinguishes hard validation failures (INVALID_POSTAL_CODE, COUNTRY_NOT_SUPPORTED, MISSING_REQUIRED_FIELD) from soft signals that should be allowed through with a risk flag rather than a hard block.
- The impact is quantified against real traffic: 711 valid checkouts, not a theoretical estimate from a synthetic test dataset, which gives the PR author a specific number to validate the fix against before resubmitting.
How to Catch a Silent Checkout Regression Before Merge
A real address validation regression, caught in live production before the PR merges, using the Lightrun Runtime-Aware PR Verifier inside GitHub. Here is exactly how it plays out.
An AI agent has submitted PR #4281 modifying the address validation logic in CheckoutAddressService.java. The diff adds a guard that throws InvalidShippingAddressException whenever the provider returns isDeliverable=false:
| // CheckoutAddressService.java — inside validateAndNormalizeif (!result.isDeliverable()) { throw new InvalidShippingAddressException(“Address is not deliverable”);}return result.normalizedAddress(); |
Every static check passes. Both reviewers approve. The lightrun/runtime-aware-pr-verification check is the only one still running.
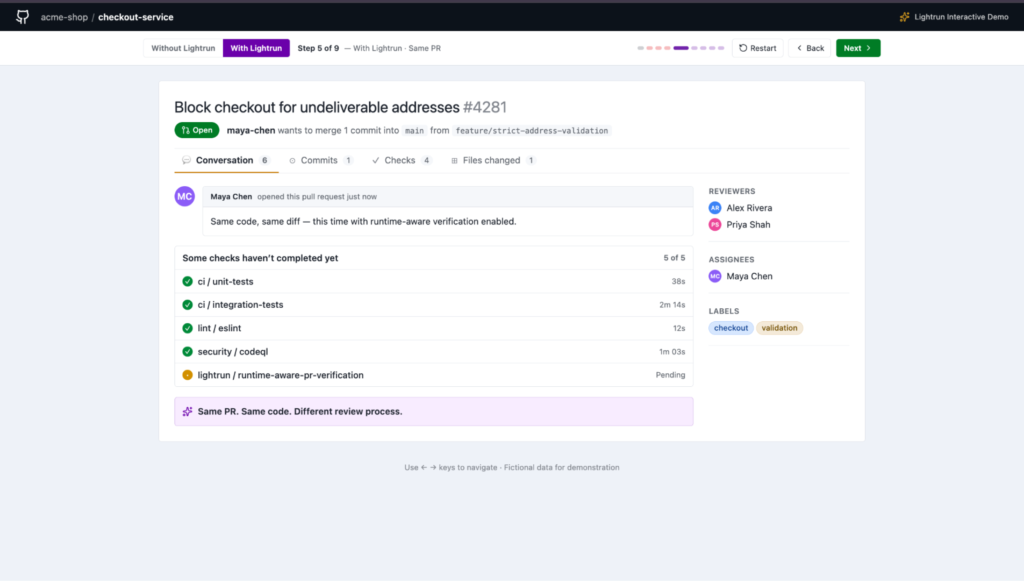
As you can see in the screenshot above:
- All four original checks have passed in identical time to the previous flow, confirming that the runtime verification check adds no friction to the existing pipeline.
- The Lightrun check runs in parallel, not as a blocking gate, so the reviewer experience is unchanged while execution evidence is being gathered from the live production service.
Step 1: The Runtime Sensor captures live production samples
The Runtime Sensor injects a snapshot into the currently running production service at the exact line the PR modifies, validateAndNormalize in CheckoutAddressService.java. It captures 100 real production samples reflecting the actual distribution of address validation results under live traffic. No redeployment. No synthetic data. No staging approximation.
The live stream immediately surfaces what the diff could not encode: multiple distinct reasons behind isDeliverable=false, including NEW_DEVELOPMENT_AREA, ADDRESS_NOT_IN_DELIVERY_DATABASE, and CARRIER_DATA_UNAVAILABLE. Many of these snapshots are followed by deliverable=true results for the same normalized addresses on subsequent calls, confirming that these are soft signals, not hard failures.
Step 2: The offline simulation runs the PR logic against captured samples
With 100 production samples captured, the verifier runs the PR’s new if (!result.isDeliverable()) logic against them offline, without deploying the changed code. The comparison is direct: the original production code produces a 1% address validation failure rate. The PR’s new logic produces a 40% failure rate on the same 100 samples, a 39 percentage point increase with no latency change.
This is the failure mode that staging cannot catch. Staging datasets contain only the address types the team anticipated when building tests. Production contains every address type the carrier network has ever encountered. The regression only becomes visible when the new logic runs against the full distribution.
Step 3: Impact is quantified before anything ships
The simulation scales the observed regression to the full production traffic volume: 711 valid checkouts that currently result in successful delivery would have been blocked by the new logic. The verification check fails and posts a bot comment directly in the PR with the observed production behavior, the simulated impact count, and a specific recommendation.
The recommendation does not just flag the problem. It identifies the exact reason codes that constitute genuine hard failures (INVALID_POSTAL_CODE, COUNTRY_NOT_SUPPORTED, MISSING_REQUIRED_FIELD) and distinguishes them from soft signals that should trigger a risk flag rather than an exception. The reviewer and the PR author both have the evidence they need to fix the logic correctly, not just to fix the test.
Step 4: The fix is validated before it merges
The engineer updates CheckoutAddressService.java to block only on hard validation failures and add a risk flag for low-confidence addresses:
| if (result.reason() == INVALID_POSTAL_CODE || result.reason() == COUNTRY_NOT_SUPPORTED || result.reason() == MISSING_REQUIRED_FIELD) { throw new InvalidShippingAddressException(result.reason());}if (!result.isDeliverable()) { order.addRiskFlag(AddressRiskFlag.LOW_CONFIDENCE_ADDRESS);}return result.normalizedAddress(); |
The updated PR is re-run through the runtime verification check.
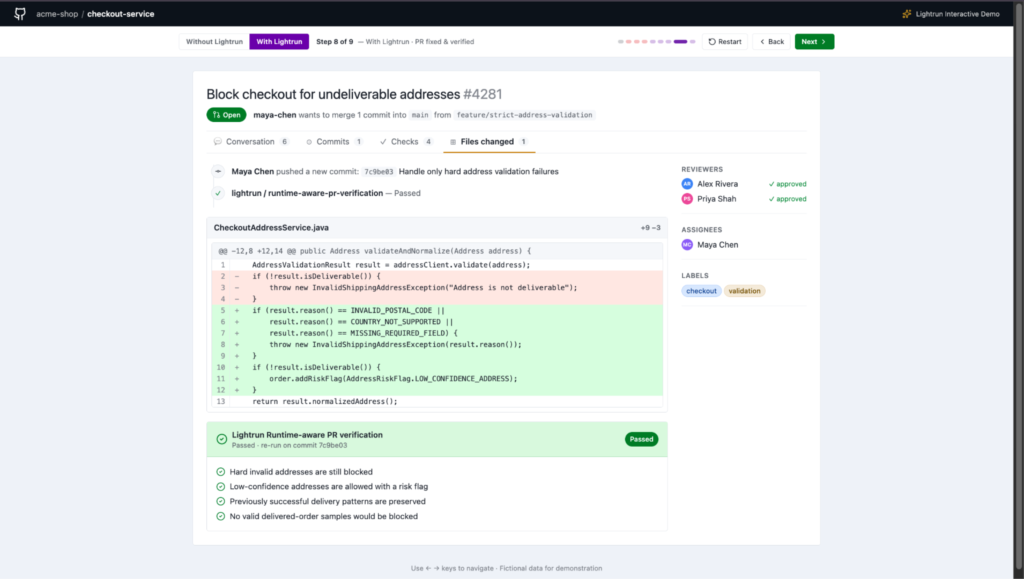
As you can see in the screenshot above:
- The verification result is granular: four distinct behavioral confirmations, not a single pass/fail signal, so both the reviewer and the PR author can confirm that each production concern identified in Step 3 has been addressed.
- The check re-runs automatically on the new commit, confirming that the fix resolves the regression against the same 100 real production samples used to detect it; the evidence base is consistent across both runs.
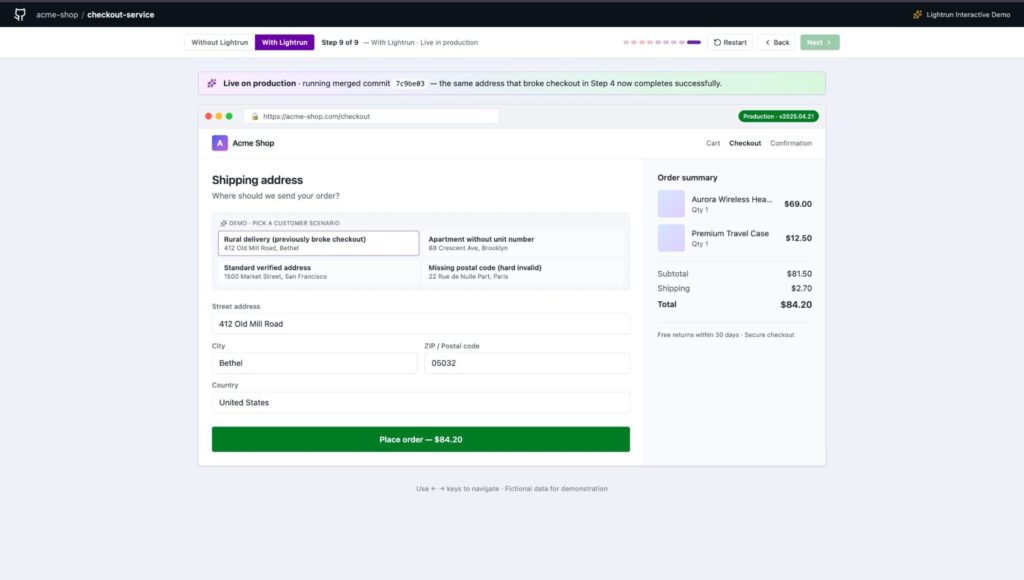
This is what eliminates the two to three redeploy cycles that 88% of organizations currently burn through to verify a single AI-generated change. The fix was confirmed against real production conditions before it shipped, not after a second incident exposed what the first fix missed.
Where Runtime PR Validation Fits Across the Dev Lifecycle
Runtime PR validation belongs at every stage where execution behavior matters, not only at the merge gate.
Before the merge, the PR is still open and the Runtime Sensor queries live production state. Variable values, branch decisions, and downstream behavior are verified against the actual environment before the reviewer approves. At merge, the change rolls out to canary and the Lightrun Sandbox captures execution state across the affected paths. If behavior deviates from what was validated at review time, it surfaces before the rollout expands to full production. After the merge, the Runtime Sensor stays attached. If production behavior drifts from what was validated, the agent queries the live service immediately without a new redeploy cycle.
Deviations at canary affect a fraction of users. Deviations in full production affect everyone. The MTTR reduction that runtime context enables depends on catching those deviations at the earliest possible stage.
How Runtime Context Closes Each PR Review Gap
| PR review gap | Why static review misses it | How the Lightrun Runtime-Aware PR Verifier catches it |
| Logic errors in paths that only fire under production conditions | The triggering condition never appears in the test environment | Agent queries the live execution path under real traffic before the merge |
| Soft-signal misclassification from downstream providers | Provider response semantics are not visible in the source declaration | Runtime Sensor captures actual reason codes and delivery outcomes at the execution point |
| Downstream service behavior across boundaries | Service responses are not observable from the source code | Agent traces execution across service boundaries without redeployment |
| Spec drift: failure rate assumptions that tests never validate | Static tools have no mechanism to check a diff against the ticket’s documented assumptions | Lightrun Runtime-Aware PR Verifier checks the PR against the ticket and flags assumption violations |
| AI-generated code with no execution history | The model has no visibility into the production environment for which it generated code | The Runtime Sensor captures real production behavior and runs it against the PR logic before merge |
| Fix validation risk before deployment | Staging does not replicate production conditions or traffic distribution | The Lightrun Sandbox confirms fixes against live production state before anything ships |
The Merge Decision Is Only as Good as the Evidence Behind It
The review process itself is not broken. The evidence it runs on is too thin for the volume and complexity of code being merged today.
AI agents generate correct-looking diffs faster than any reviewer can simulate their execution. Static tools can only read what is written. Every AI review tool in the current generation hits the same architectural wall: they reason over pre-captured telemetry and static source context, but they cannot reach the execution state that only exists at runtime.
More analysis capability, better models, and faster pipelines do not change what those tools can actually observe. The evidence boundary is fixed by access to the runtime.
The Lightrun Runtime Sensor is what moves that boundary. When your agent and your reviewer can see live variable values, real branch decisions, and downstream service behavior before the merge decision is made, the review stops being an approximation and becomes a confirmation. That is the evidence standard that AI-generated code at this volume demands.
FAQ
Runtime-aware PR review means validating a code change against live variable state, real execution paths, and downstream service behavior before the merge decision is made. Rather than approving code based on how it reads in a diff, the reviewer and the AI coding agent both have access to execution evidence from the running production service, so the approval is grounded in what the code actually does when real traffic hits it.
AI code review tools operate on static inputs: source code, test history, and codebase context. None of those inputs contain live variable state, real execution paths, or downstream service responses. When a failure depends on a runtime condition the model has never seen, such as a provider returning isDeliverable=false for addresses that successfully ship, there is no signal to flag it regardless of how capable the model is. This is an architectural constraint, not a model quality problem.
Runtime context is live visibility into how code behaves while it runs: execution paths, variable state, conditional branches, and downstream responses, captured on demand without redeployment. It is the evidence layer that lets an agent or engineer confirm behavior rather than infer it. The Lightrun Runtime Sensor captures and delivers this context directly into your PR review workflow and your IDE.
The verifier attaches the Runtime Sensor to the currently running production service and captures real traffic samples at the exact code path the PR modifies. It then runs the PR’s new logic against those samples offline in a simulation, compares the behavioral outcomes to the original production code, and checks the results against the assumptions documented in the originating ticket. The check runs as part of the CI pipeline and posts findings directly in the pull request before the merge decision is made.
Staging environments rarely match production in traffic distribution, data variety, or dependency behavior. The Lightrun Sandbox runs the Runtime Sensor against the live production process in read-only mode with zero performance overhead and zero impact on user traffic, so a fix validated there is confirmed against the actual conditions the change will face, not an approximation that may not include the specific address types, carrier response codes, or traffic patterns that caused the original failure.


