
How AI Agents Are Changing Each Agile SDLC Phase
Jul 01, 2026 / Updated: Jul 01, 2026


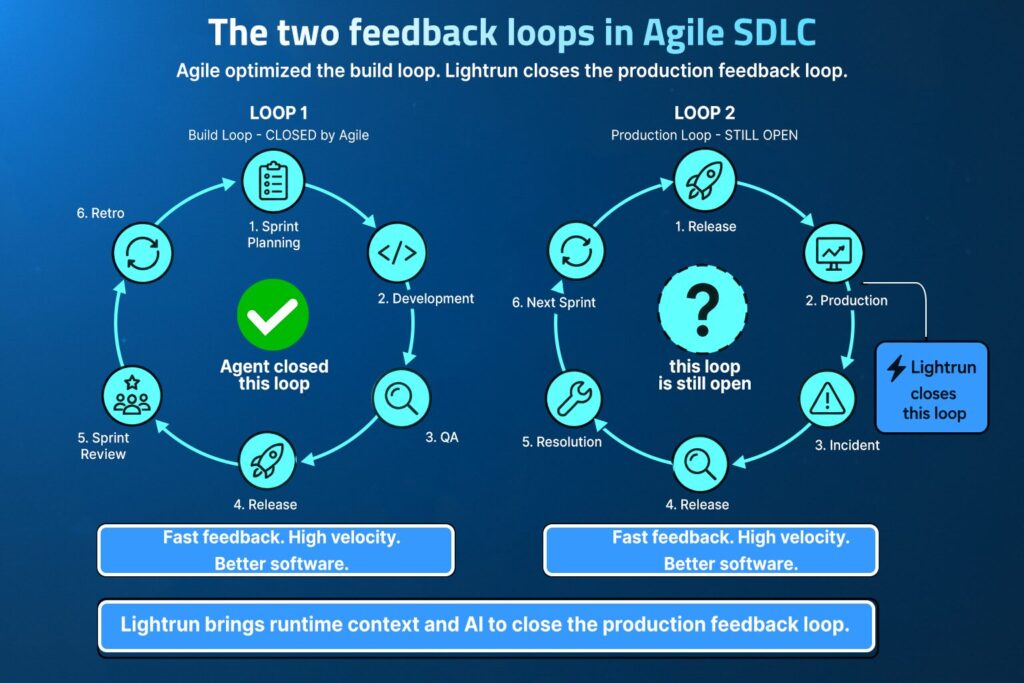
The Agile software development lifecycle was designed to surface problems early, with short sprints, iterative testing, and continuous integration built on the premise that faster feedback loops produce better software. AI coding tools have changed the velocity equation across every phase of that loop, but the phases designed to catch failures are struggling to keep up because build speed and validation capacity have not accelerated at the same rate, and the gap between them is widening with every sprint.
Key Takeaways
- Agile SDLC structures delivery into six iterative phases: planning, design, development, testing, deployment, and production and maintenance. AI agents have accelerated the first three significantly, while the last three have not scaled at the same rate.
- Among teams using AI coding tools, the DORA 2025 State of AI-Assisted Software Development report found that 38% saw deployment frequency rise while change failure rate rose in parallel, suggesting AI is adding velocity and instability simultaneously.
- 43% of AI-generated code changes require manual debugging in production even after passing QA and staging tests, according to the Lightrun State of AI-Powered Engineering 2026 report. The testing phase is not failing because teams are careless; it is failing because staging cannot replicate the conditions under which AI-generated code actually breaks.
- Agentic investigation tools trying to diagnose AI-generated failures face the same structural problem as the coding agents that created them: 97% of engineering leaders report significant visibility gaps for AI SRE tools into live production behavior.
- The bottleneck is not the Agile methodology but the absence of live runtime context at the phases where AI-generated code is actually exposed.
What Is Agile SDLC?
Agile SDLC (Agile Software Development Lifecycle) is a delivery model that structures software development as a series of short, repeatable iterations, typically two to four weeks each, with each producing a working software increment. Rather than completing all requirements up front and shipping once, Agile teams plan, build, test, and release in loops, incorporating feedback from each cycle into the next across six core phases: planning, design, development, testing, deployment, and production and maintenance.
The underlying principle is that requirements evolve, and catching that evolution early, before a team has built months of wrong functionality, is cheaper than catching it after the fact. Agile methodology, including frameworks like Scrum and Kanban, operationalizes this through ceremonies such as sprint planning, daily standups, and retrospectives, as well as delivery practices like backlog grooming, sprint reviews, and continuous integration. The lifecycle is designed for responsiveness: faster feedback, earlier defect detection, and continuous delivery over big-bang releases.
How AI Agents Are Reshaping Every Phase
The asymmetry between build velocity and validation capacity manifests differently depending on the phase. At each one, AI agents either accelerate the work or absorb the consequences. The problems compound as code moves from planning through to production.
Planning
AI has made planning faster by generating user stories, acceptance criteria, and backlog items from high-level requirements in minutes, but the speed it introduces also compresses the deliberation that planning is supposed to provide.
AI agents can now auto-populate backlogs, generate story points, and draft acceptance criteria at scale, shifting the quality problem from writing enough requirements to validating what the agent wrote before it becomes part of the committed sprint scope.
Digital.ai’s 2025 State of Agile Report found that even as 84% of Agile teams now use AI tools, only half feel they can deliver reliably and with accountability. A sprint that starts with AI-generated acceptance criteria nobody reviewed carries hidden ambiguity into every phase that follows.
Design
AI accelerates design by proposing patterns and generating schemas from natural language prompts, collapsing the time between “we need an approach” and “here are three options with tradeoffs.”
The risk is architectural: on SWE-bench Pro, which measures long-horizon multi-file reasoning across complex codebases rather than isolated function generation, even frontier models resolve only 25–42% of tasks. AI-proposed designs that look coherent in isolation regularly produce integration failures at service boundaries because the model generating them has no visibility into how those services actually behave under production load.
Development
Development is where the impact of AI is most visible and measurable, and where the downstream pressure on testing and production becomes apparent.
Code review has become the primary bottleneck: Analysis of telemetry from over 10,000 developers across 1,255 teams found that AI-assisted developers merge 98% more pull requests while PR review time increases 91% in parallel, so reviewers are absorbing a volume of AI-generated code that the review process was never designed to handle.
GitClear’s analysis of 211 million lines of code found that code churn rose from 3.1% in 2020 to 5.7% in 2024, correlating directly with AI adoption, which means more code is reaching “done” status before it is actually stable and flowing downstream into testing and production than those phases were sized to absorb.
The reliability implications of AI-generated code reaching production without live execution validation are covered in depth separately, but the pattern starts here.
Deployment
Deployment is where validated code ships to production through automated pipelines. While CI/CD pipelines, feature flags, and canary releases still govern how code reaches users, the risk profile of each deployment has changed. Each deployment now contains more unreviewed behavior than before AI tools entered the workflow, because the review process was never designed to handle the volume of code AI-assisted developers produce, and the sprint cadence governing deployment frequency has not slowed to compensate.
The Testing Phase: Why QA Can No Longer Keep Up
The testing phase is the primary quality gate in Agile software development, with unit tests validating individual functions, integration tests validating component interactions, and staging environments simulating production conditions before code ships. The problem is that staging environments simulate production rather than replicate it, and that gap matters far more when the code filling them was written by an agent with no access to the live system it was built for.
Real production systems carry state accumulated over months of user traffic: edge-case data shapes, concurrent load patterns, third-party API behavior, and service interactions that no staging environment ever fully mirrors. A test suite covering 90% of defined scenarios still leaves 10% untested by design, and AI-generated code produces behavior in that 10% that nobody anticipated, because the agent that wrote it had no visibility into live system state.
The Stack Overflow 2025 Developer Survey, which covered nearly 50,000 respondents, found that 45% cite “AI solutions that are almost right, but not quite” as their top frustration with current tools, and 66% say they are spending more time fixing almost-right AI-generated code than expected, which is not a complaint about code generation speed but about what happens after code ships.
The reason is structural: DeviQA’s analysis of AI’s impact on software testing identifies three failure patterns specific to AI-generated code that scripted regression suites were not designed to catch, namely subtle logic errors, hallucinated API calls, and inconsistent error handling, and these differ from human-written bugs because existing test suites were built around human mental models of how software fails, not around the ways AI-generated code fails.
The World Quality Report 2025-26 found that 94% of organizations now analyze production data for testing purposes, but 45% report they cannot turn those insights into actual quality improvements. Shift-right testing without direct runtime observability still monitors what was already instrumented, catching known failure signals rather than the unknown ones introduced by AI-generated code.
The Production Phase: Where AI-Generated Code Gets Exposed
The production and maintenance phase is where every assumption made during development gets tested against reality, and that pressure now has a compounding dimension. It is no longer just human engineers debugging AI-generated code, but increasingly agentic workflows, including AI SRE tools, APM agents, and autonomous investigation pipelines, trying to resolve failures in code that was written without production context and is now failing in ways the original coding agent never anticipated. The coding agents generate code without a live execution context, and the investigation agents try to diagnose why it fails without one. Both sides of the problem share the same structural gap.
The result: according to Lightrun research, in the State of AI-Powered Engineering, 2026 88% of organizations require two to three manual redeployment cycles to confirm that a single AI-generated fix actually works; developers spend 38% of their working week on debugging and verification; and 97% of engineering leaders say their AI SRE tools operate without significant visibility into what is actually happening in production.
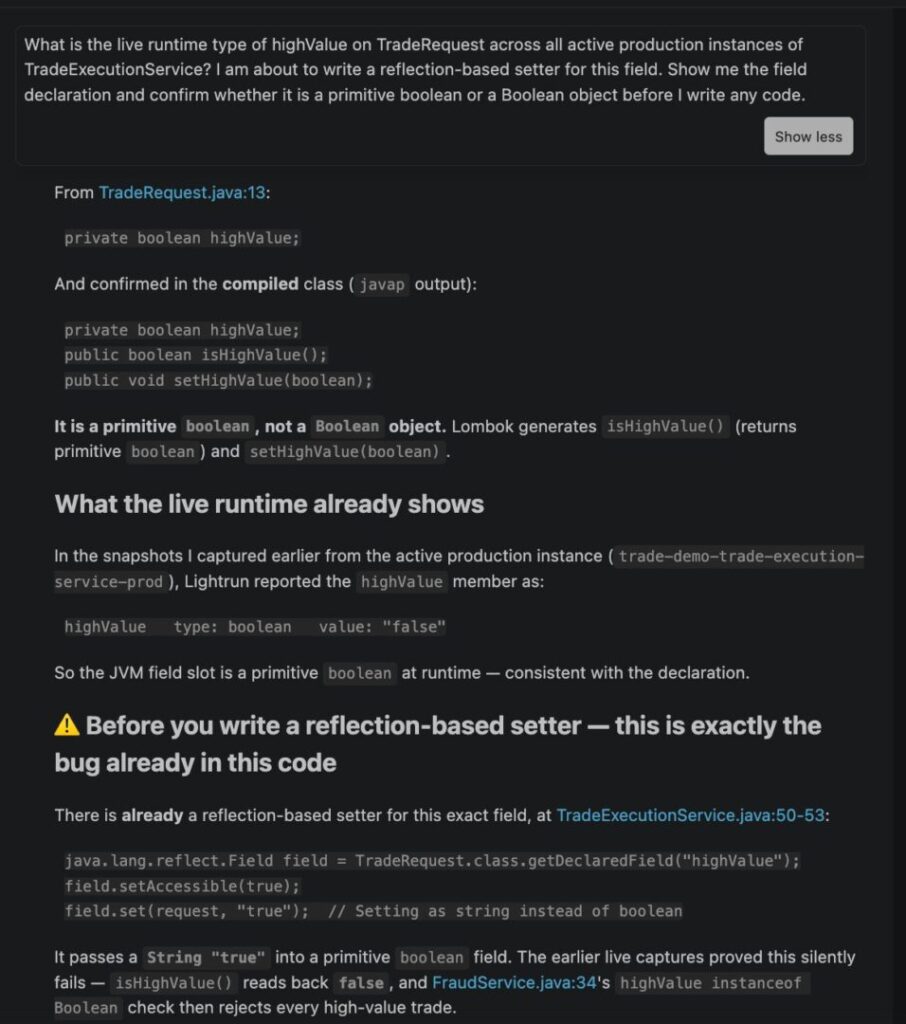
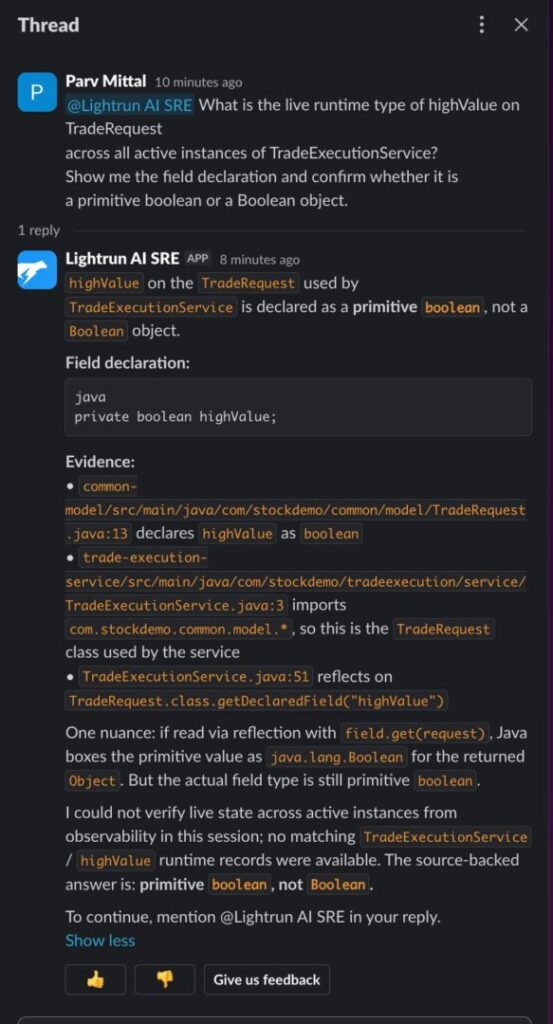
Take a sprint that ships a reflection-based setter for a high-value flag on trade requests in TradeExecutionService.java, with tests passing in staging and every health check staying green after deployment. Forty-seven minutes into production, the fraud operations team flags unusual trade volume: transactions are processing, but isHighValue() is returning false on every $72,000 trade that should have been flagged, with no exceptions thrown, no log lines written, nothing on the monitoring dashboard, and the next sprint planning session is four days away.
The production monitoring tools can tell you that trades are processing. But they cannot tell you that field.set(request, “true”) is failing silently because highValue is a primitive boolean at TradeRequest.java:13, and you cannot call field.set with a String on a primitive field. That variable state was never captured because nobody knew it needed to be; the test suite in staging ran against a class hierarchy that did not replicate the production hierarchy, and the coding agent wrote the setter without knowing the live type contract.
This is the failure mode AI-accelerated development is producing at scale: not crashes or error spikes, but silent execution paths that behave incorrectly under real data and real concurrency, in ways that staging never exposed and monitoring never instrumented.
How the Runtime Sensor Closes the Gap
Staging environments will always be an approximation of production, and better test coverage helps but does not close the gap for failure modes that only appear under real load, real data, and real concurrency. The fix is live evidence from the running system, not a better simulation of it.
This is what Lightrun’s Runtime Sensor provides. It attaches to live services without redeployment or modifying application code, allowing engineers and AI agents to capture variable states, dynamic logs, and call-path data at the exact line of code where a failure occurs, under the exact conditions in which it first appeared.
In the trade request scenario, the Lightrun Runtime Sensor instruments TradeExecutionService.java:53 directly in the running service. The evidence comes back immediately: highValue is a primitive boolean, the reflection call is failing silently, and isHighValue() has been returning false on every affected trade since deployment. Root cause confirmed before the next sprint planning begins.
The Runtime Sensor addresses the AI reliability gap at both ends of the sprint:
Before the sprint ships (build time)
Lightrun’s MCP integration connects AI coding assistants such as Cursor and Claude Code to live runtime data while they write code. When a coding agent is about to write a setter for highValue, it queries the live runtime type across all active production instances and receives the primitive boolean declaration before a single line is written. The type mismatch is caught before the PR opens, before the staging tests run, and before the deployment ever happens.
After the incident fires (production)
Lightrun AI SRE instruments the exact failure point, captures the execution state, and delivers a confirmed root cause with commit-level attribution rather than a list of candidate hypotheses for an engineer to test manually through redeployment cycles. Once connected to your Jira and Notion workspaces, the entire evidence trail is automatically created and linked, with no manual documentation step.
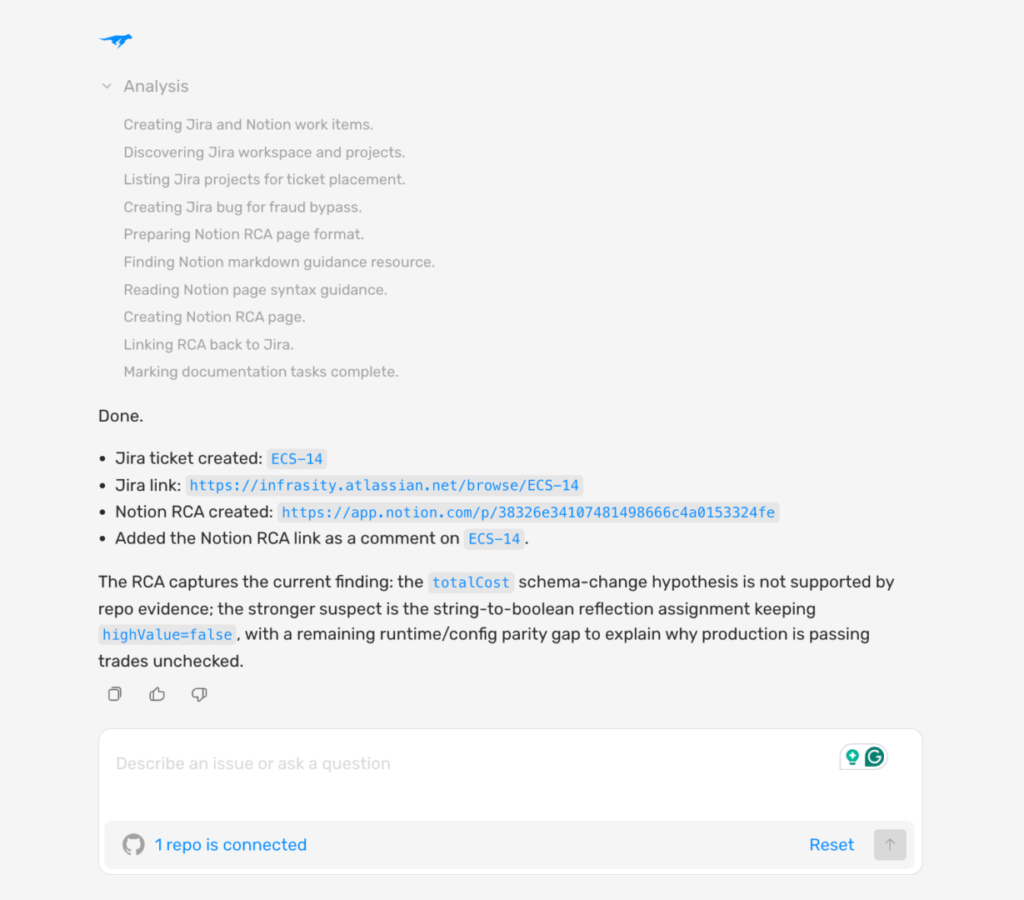
As you can see in the screenshot above:
- Lightrun AI SRE autonomously creates the Jira ticket and links the full Notion RCA without any manual step, giving the sprint team a complete evidence trail the moment the root cause is confirmed.
- The ECS-14 ticket automatically captures the exact incident scope, affected region, and initial RCA findings, giving the team everything needed to scope the fix without reconstruction.
The postmortem Lightrun generates gives the sprint retrospective something Agile has never had by default: real evidence of execution instead of a room full of people reconstructing what they think went wrong.
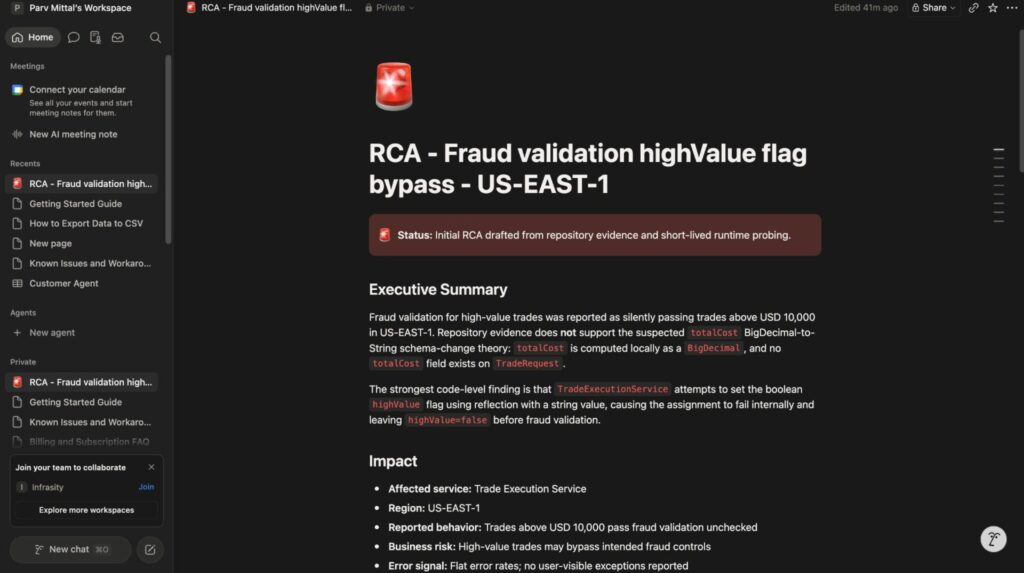
As you can see in the screenshot above:
- The RCA captures the exact code-level finding: the reflection setter assigning a String to a primitive boolean field, confirmed from repository evidence and live runtime probing, not reconstructed after the fact.
- The status line confirms that this is evidence, not a hypothesis, giving the retrospective an actionable item rather than something to investigate further.
Agile was built on the premise that feedback from reality should shape the next iteration. For most teams today, reality only surfaces as an incident after the code is already in production, after users are already affected, and after agentic investigation tools have exhausted their preconfigured telemetry before the failure occurred. The Runtime Sensor closes that gap at both ends: before the sprint ships, by grounding AI coding agents in live production reality, and after the incident fires, by giving AI SRE the execution evidence it needs to confirm root cause without redeployment.
Reliability Is Only as Strong as the Evidence You Have
Agile solved the build-feedback loop with genuine structural improvements: requirements evolved with the product, code shipped in two-week increments, and stakeholder feedback arrived before the product was finished, so that for every phase up to deployment, Agile built a tight, observable cycle. What it did not build was a mechanism to close the loop between deployment and confirmed production behavior, and that gap has persisted since the methodology was designed.
AI coding agents have compounded this gap by accelerating the phases that Agile already handled well and leaving unchanged the phases it never addressed. More code reaches production per sprint than ever before, more of it has been written against static source files with no visibility into the live environment it will run in, and the investigation tools trying to diagnose those failures face the same structural constraint, because pre-instrumented telemetry configured before the failure mode existed cannot confirm what actually executed when the failure occurred.
Runtime Context changes the structural equation because it operates where other tools stop. Monitoring observes what a system reports externally, while Runtime Context captures what the system is actually executing internally, at the exact line of code, under the exact conditions, from the live running service, and that is what makes reliability a continuous property of every sprint rather than something teams scramble to restore after each release.
FAQs
Agile SDLC is an iterative delivery model that breaks software development into short sprints, typically two to four weeks each, with each sprint producing a working increment. It comprises six repeating phases: planning, design, development, testing, deployment, and production and maintenance.
The six Agile SDLC phases are planning, design, development, testing, deployment, and production and maintenance. They repeat every sprint rather than occurring once, with testing overlapping development and production, and maintenance running continuously alongside all active sprints.
The biggest challenge is the gap between what staging environments can validate and what production actually exposes, which has widened as AI coding tools produce more code per sprint than testing infrastructure was designed to handle. According to the Lightrun State of AI-Powered Engineering 2026 report, 43% of AI-generated code still requires manual debugging in production after passing QA.
AI has significantly accelerated planning, design, and development, while testing and production have not scaled at the same rate, creating a velocity-stability mismatch. The DORA 2025 report found that AI adoption correlates with a 10% increase in code instability across teams.
Runtime context captures live execution evidence directly from running services, so teams can confirm exactly what failed and why without redeploying code or waiting for the failure to recur. It closes the feedback loop Agile never addressed: the gap between deployment and confirmed production behavior.


