
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[Performance] will a decompressed bytebuffer cache help?
See original GitHub issueThe flame-graph sampled from our production cluster shows that a large portion of CPU time has spent on LZ4Decompression (probably 60%+ of all querying related methods), as shown in the following picture.
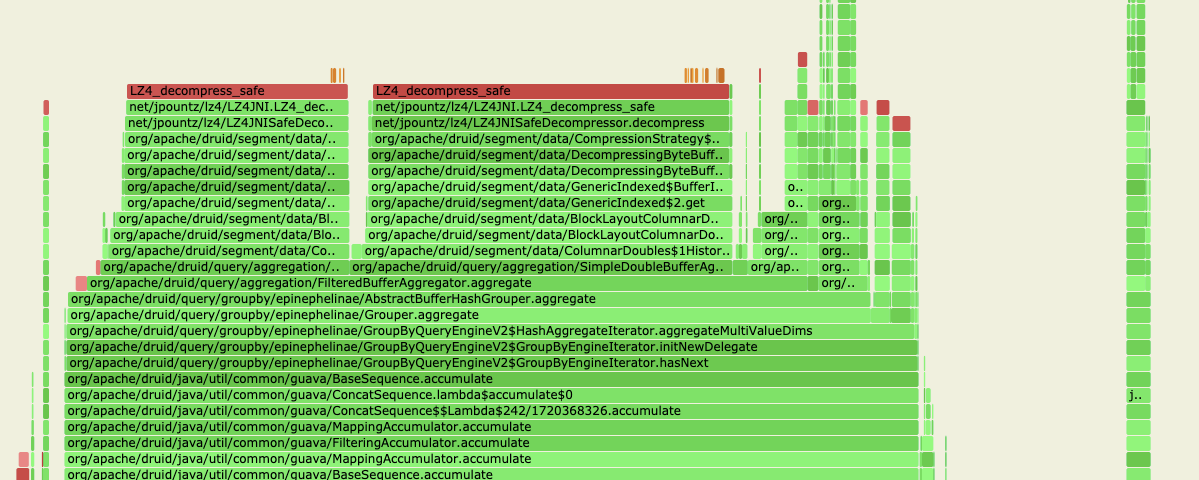
I wonder would a (probably on disk) LRUCache on de-compressed data help?
It seems it would not be hard to implement. A, say, BufferedGenericIndexd can be created with a generated UUID, and then we can use <uuid>-bufferNumber as the cache key.
But I’m not sure about the effectiveness. It does introduce extra cost of cache miss penalty, random disk IO, etc.
That’s why I would like to raise a discussion here and find out is it a feasible solution.
Thanks
Issue Analytics
- State:

- Created 4 years ago
- Comments:5 (5 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
An alternative to this would be to just leave the data uncompressed (which is supported at indexing time currently), then let the kernel manage the page cache on its own. That way we wouldn’t need to do special buffer handling.
Thanks guys. It seems I need more investigation and evidence before dive into implementation.