
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Difference between f1 metric and log_loss metric performance for lightgbm
See original GitHub issueEcosystem used:
autogluon.core==0.3.2b20211111 autogluon.extra==0.3.2b20211111 autogluon.features==0.3.2b20211111 autogluon.tabular==0.3.2b20211111
machine: ubuntu, r4.4xlarge
Using almost the same code (with more subsample_size items) that was previously used in this issue:
import pandas as pd
import numpy as np
from autogluon.tabular import TabularDataset, TabularPredictor
path_prefix = 'https://autogluon.s3.amazonaws.com/datasets/Inc/'
path_train = path_prefix + 'train.csv'
path_test = path_prefix + 'test.csv'
train_data = TabularDataset(path_train)
test_data = TabularDataset(path_test)
outputs = []
for subsample_size in [
5000,
10000,
50000,
100000,
150000,
200000,
400000,
800000,
1600000,
3200000,
6400000,
]:
if subsample_size is not None and (subsample_size < len(train_data)):
train_data_sample = train_data.sample(n=subsample_size, random_state=0).reset_index(drop=True)
else:
train_data_sample = train_data.sample(n=subsample_size, random_state=0, replace=True).reset_index(drop=True)
label = 'class'
predictor = TabularPredictor(
label=label,
verbosity=2,
problem_type='binary',
eval_metric='f1',
).fit(
train_data_sample,
tuning_data=test_data,
# ag_args_fit={'stopping_metric': 'log_loss'},
hyperparameters={'GBM': {}, 'XGB': {}}
)
output = predictor.leaderboard()
output['data_size'] = subsample_size
outputs.append(output)
The following results are obtained:
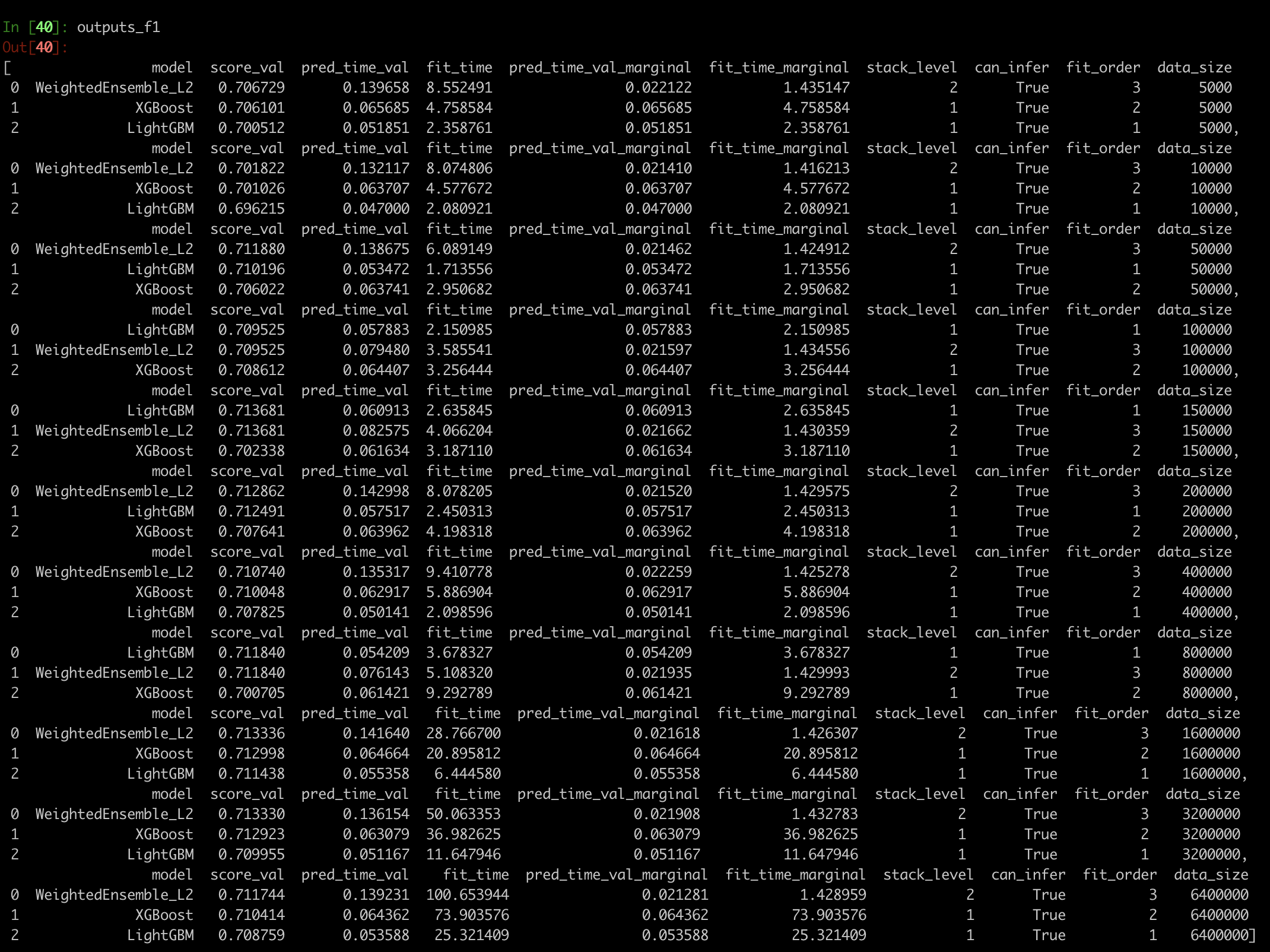
When I change the metric to log_loss, the results are following:
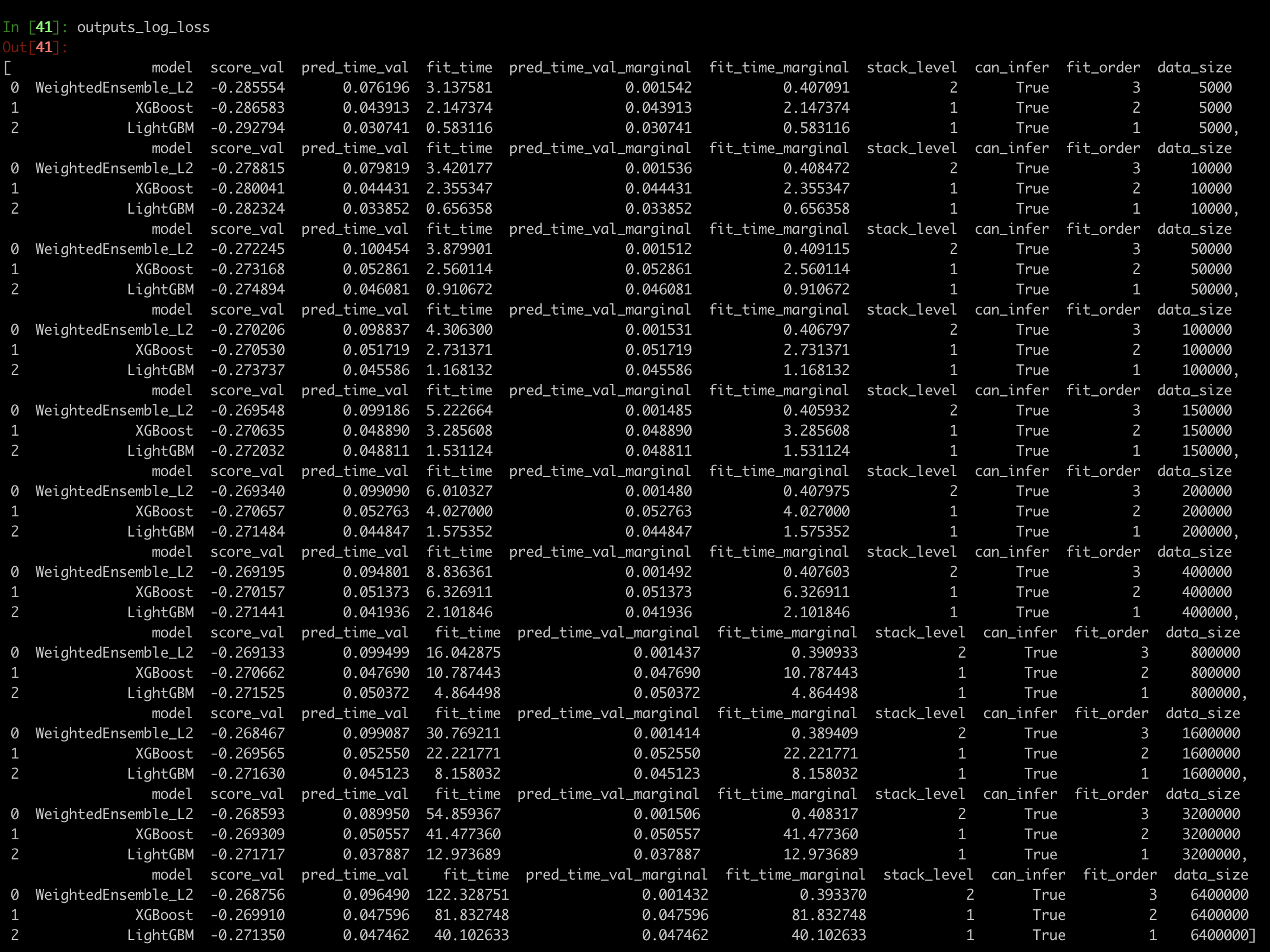
What one can see is significant reduction in training time for lightgbm for smaller data sizes. However, it goes up significantly for larger ones.
We also encountered this issue when training on our private dataset, with about 2-3x fold reduction in training time for data with 1.4M rows and 1500 columns when using log_loss metric instead of f1 for lightgbm. I’ll provide the shape of data, dtypes and hyperparameters used in training with time comparison in our case:
autogluon_fit_hparams = {'model_feature_type_group_map_special': {'text': ['search_term', 'keyword']},
'hyperparameters': {'GBM': {}},
'hyperparameter_tune_kwargs': 'auto',
'presets': 'medium_quality_faster_train',
'num_bag_folds': 2,
'num_bag_sets': 2,
'keep_only_best': True,
'save_space': True,
'distill': False,
'use_bag_holdout': True,
'verbosity': 2,
}
Our dataset info:

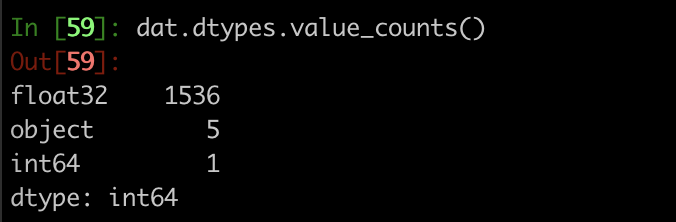
We also tested version with 100K data rows.
Obtained training times as reported by autogluon:
100K rows: 43 min 8 sec with f1 score (lightgbm) 15 min 30 sec with log_loss (lightgbm)
Full data (1377524 rows): 8 hr 28 min 40 sec with f1 score (lightgbm) 4 hr 6 min 27 sec with log_loss (lightgbm)
So for our data we obtained lower times for lightgbm with log_loss even with almost 1.4M rows, however the difference was less significant than with 100K rows.
Would like to know your comment about these differences, thank you.
Issue Analytics
- State:

- Created 2 years ago
- Comments:5
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Ok, I’ll investigate how does it look with the newest features, thank you!
Marking this as resolved. Please re-open if the issue persists on pre-release.