
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
How to reduce memory usage when loading large parquet dataset?
See original GitHub issueDescribe the bug
I am trying to load a dataset of 200 parquet files (≈11GB in total) from s3 and convert it into a DataFrame. Note that I only use a small subset of columns so most of the data is redundant. When I download the data manually, load them one by one using pd.read_parquet, and merge them using pd.concat, the program uses ≈12GB of RAM. However, when I try doing the same using wrangler, I can see it using up to ≈30GB of RAM before it errors with
File "/Users/jannikbertram/opt/miniconda3/envs/wit/lib/python3.8/site-packages/pyarrow/parquet.py", line 270, in read_row_group
return self.reader.read_row_group(i, column_indices=column_indices,
File "pyarrow/_parquet.pyx", line 1079, in pyarrow._parquet.ParquetReader.read_row_group
File "pyarrow/_parquet.pyx", line 1098, in pyarrow._parquet.ParquetReader.read_row_groups
File "pyarrow/error.pxi", line 99, in pyarrow.lib.check_status
OSError: IOError: ("Connection broken: ConnectionResetError(54, 'Connection reset by peer')", ConnectionResetError(54, 'Connection reset by peer')). Detail: Python exception: ProtocolError
To Reproduce I installed wrangler using pip within a miniconda environment, python version 3.8.2 running on macOS Catalina.
dfs = wr.s3.read_parquet(
s3_path_to_folder_with_parquet_files,
dataset=True,
columns=['column1', 'column2', 'column3'],
chunked=True
)
df = pd.concat(dfs)
To reproduce, obviously, you also need a dataset of similar size.
Can somebody explain what’s happening here? Perhaps it’s just a mistake in my setup or this behaviour is intentional?
Issue Analytics
- State:

- Created 3 years ago
- Comments:5 (4 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@janbe-ts
I will try to improve this explanation to make things cleaner. But it will only help you to save memory if you process each chunk at once.
e.g.
Hmm… I also don’t know the difference reason, but let me know if you find out.
P.S. If you want save memory, you should consider the
categoriesargument, it helps in some cases.Hi @igorborgest, thanks for your quick and detailed reply!
You were right, I had a slightly different setup locally. I used
fastparquetas parquet engine and accessed a nested column fielda.b.crather thana.bas my wrangler setup (I didn’t expect it to make such a big difference). I can confirm that the memory usage is almost equal with the same columns and using thepyarrowengine.Based on this line in the code, I expected
chunked=Trueto make it more memory-efficient. Thanks for pointing out that this is not the case in my setup 😃Also, I wonder why the Activity Monitor shows me a completely different amount of memory used by the program: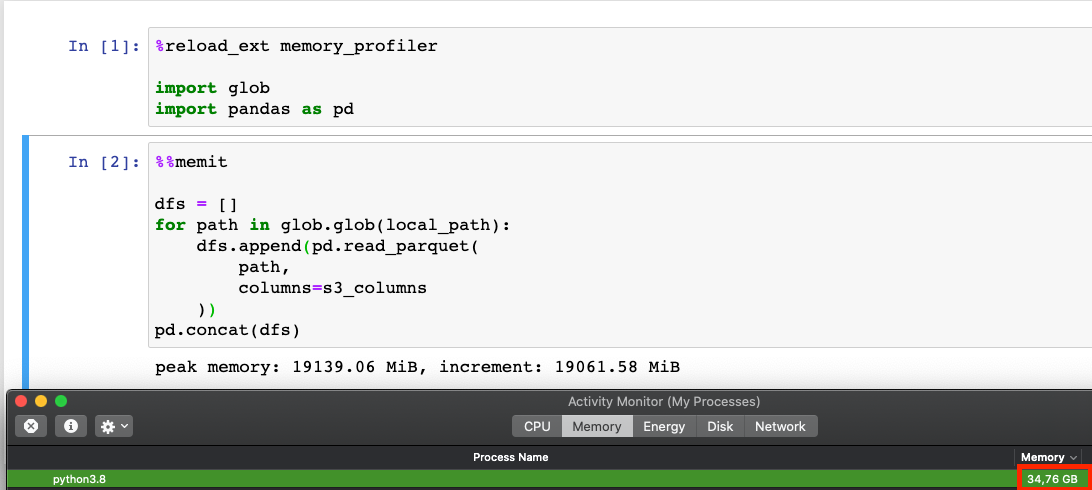
Anyway, as this is certainly not a memory leak, I will close this issue!