
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[BUG] Spark Cosmos connector does not close its threads
See original GitHub issueHi,
I have noticed that the cosmos connector does not close the threads that it creates. When the connector is put in a streaming application, those threads are accumulated over time. Eventually, the JVM cannot create any new threads and it crashes with the following exception
java.io.IOException: java.util.concurrent.ExecutionException: java.lang.OutOfMemoryError: unable to create new native thread
I have tested the connector in stream mode and batch mode; the behaviour is the same.
Here is how you can reproduce the problem for both scenarios (batch & stream).
The following information is the same for both scenarios:
Environment: Databricks 9.1
Library: azure-cosmos-spark_3-1_2-12 version 4.12.2
For the batch example: Databricks job:
{
"settings": {
"name": "Cosmos Connector Experiment - Batch Mode",
"email_notifications": {
"no_alert_for_skipped_runs": false
},
"timeout_seconds": 0,
"max_concurrent_runs": 1,
"tasks": [
{
"task_key": "Cosmos_Connector_Experiment",
"notebook_task": {
"notebook_path": "/point/to/notebook/batchModeNotebook.scala",
"source": "WORKSPACE"
},
"job_cluster_key": "Shared_job_cluster",
"libraries": [
{
"maven": {
"coordinates": "com.azure.cosmos.spark:azure-cosmos-spark_3-1_2-12:4.12.2"
}
}
],
"timeout_seconds": 0,
"email_notifications": {}
}
],
"job_clusters": [
{
"job_cluster_key": "Shared_job_cluster",
"new_cluster": {
"cluster_name": "",
"spark_version": "9.1.x-scala2.12",
"azure_attributes": {
"first_on_demand": 1,
"availability": "ON_DEMAND_AZURE",
"spot_bid_max_price": -1
},
"node_type_id": "Standard_DS3_v2",
"enable_elastic_disk": true,
"data_security_mode": "LEGACY_SINGLE_USER_STANDARD",
"runtime_engine": "STANDARD",
"num_workers": 1
}
}
],
"format": "MULTI_TASK"
},
}
Notebook code:
// Databricks notebook source
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{Dataset, Row}
object DeltaToCosmos {
def run(): Unit = {
val cosmosConfig = Map(
"spark.cosmos.accountEndpoint" -> "https://<fill>.documents.azure.com:443/",
"spark.cosmos.accountKey" -> "<fill>",
"spark.cosmos.database" -> "<fill>",
"spark.cosmos.container" -> "<fill>",
"spark.cosmos.applicationName" -> "Experiment",
"spark.cosmos.write.strategy" -> "ItemAppend",
"spark.cosmos.write.maxRetryCount" -> "10",
"spark.cosmos.write.bulk.enabled" -> "true")
spark
.readStream
.format("delta")
.load("<fill>")
.select("col1", "col2", "col3", "col4", "col5")
.withColumn("id", concat_ws("|", lit("copy"), col("col1"), col("col2"), col("col3"), col("col4"), col("col5")))
.writeStream
.outputMode("append")
.queryName("experiment")
.option("checkpointLocation", "<fill>")
.foreachBatch((batch: Dataset[Row], batchId: Long) =>
batch
.write
.format("cosmos.oltp")
.options(cosmosConfig)
.mode(SaveMode.Append)
.save()
)
.start()
}
}
DeltaToCosmos.run()
For the stream example: Databricks job:
{
"settings": {
"name": "Cosmos Connector Experiment - Stream Mode",
"email_notifications": {
"no_alert_for_skipped_runs": false
},
"timeout_seconds": 0,
"max_concurrent_runs": 1,
"tasks": [
{
"task_key": "Cosmos_Connector_Experiment",
"notebook_task": {
"notebook_path": "/point/to/notebook/streamModeNotebook.scala",
"source": "WORKSPACE"
},
"job_cluster_key": "Shared_job_cluster",
"libraries": [
{
"maven": {
"coordinates": "com.azure.cosmos.spark:azure-cosmos-spark_3-1_2-12:4.12.2"
}
}
],
"timeout_seconds": 0,
"email_notifications": {}
}
],
"job_clusters": [
{
"job_cluster_key": "Shared_job_cluster",
"new_cluster": {
"cluster_name": "",
"spark_version": "9.1.x-scala2.12",
"azure_attributes": {
"first_on_demand": 1,
"availability": "ON_DEMAND_AZURE",
"spot_bid_max_price": -1
},
"node_type_id": "Standard_DS3_v2",
"enable_elastic_disk": true,
"data_security_mode": "LEGACY_SINGLE_USER_STANDARD",
"runtime_engine": "STANDARD",
"num_workers": 1
}
}
],
"format": "MULTI_TASK"
}
}
Notebook code:
// Databricks notebook source
import org.apache.spark.sql.functions._
object DeltaToCosmos {
def run(): Unit = {
val cosmosConfig = Map(
"spark.cosmos.accountEndpoint" -> "https://<fill>.documents.azure.com:443/",
"spark.cosmos.accountKey" -> "<fill>",
"spark.cosmos.database" -> "<fill>",
"spark.cosmos.container" -> "<fill>",
"spark.cosmos.applicationName" -> "Experiment",
"spark.cosmos.write.strategy" -> "ItemAppend",
"spark.cosmos.write.maxRetryCount" -> "10",
"spark.cosmos.write.bulk.enabled" -> "true")
spark
.readStream
.format("delta")
.load("<fill>")
.select("col1", "col2", "col3", "col4", "col5")
.withColumn("id", concat_ws("|", col("col1"), col("col2"), col("col3"), col("col4"), col("col5")))
.writeStream
.format("cosmos.oltp")
.queryName("Experiment")
.option("checkpointLocation", "<fill>")
.options(cosmosConfig)
.outputMode("append")
.start()
}
}
DeltaToCosmos.run()
As you can see, both examples are quite simple. They read data from a delta lake and they push that data into a cosmos container. You will need to fill in any sensitive information (such as endpoints & keys) to run them.
At first glance, the streams work fine. They work as they should, they read data from the delta lake and store them into the cosmos container.
Looking at the logs of the job, you will see the aforementioned exception occur periodically, i.e. once per day.
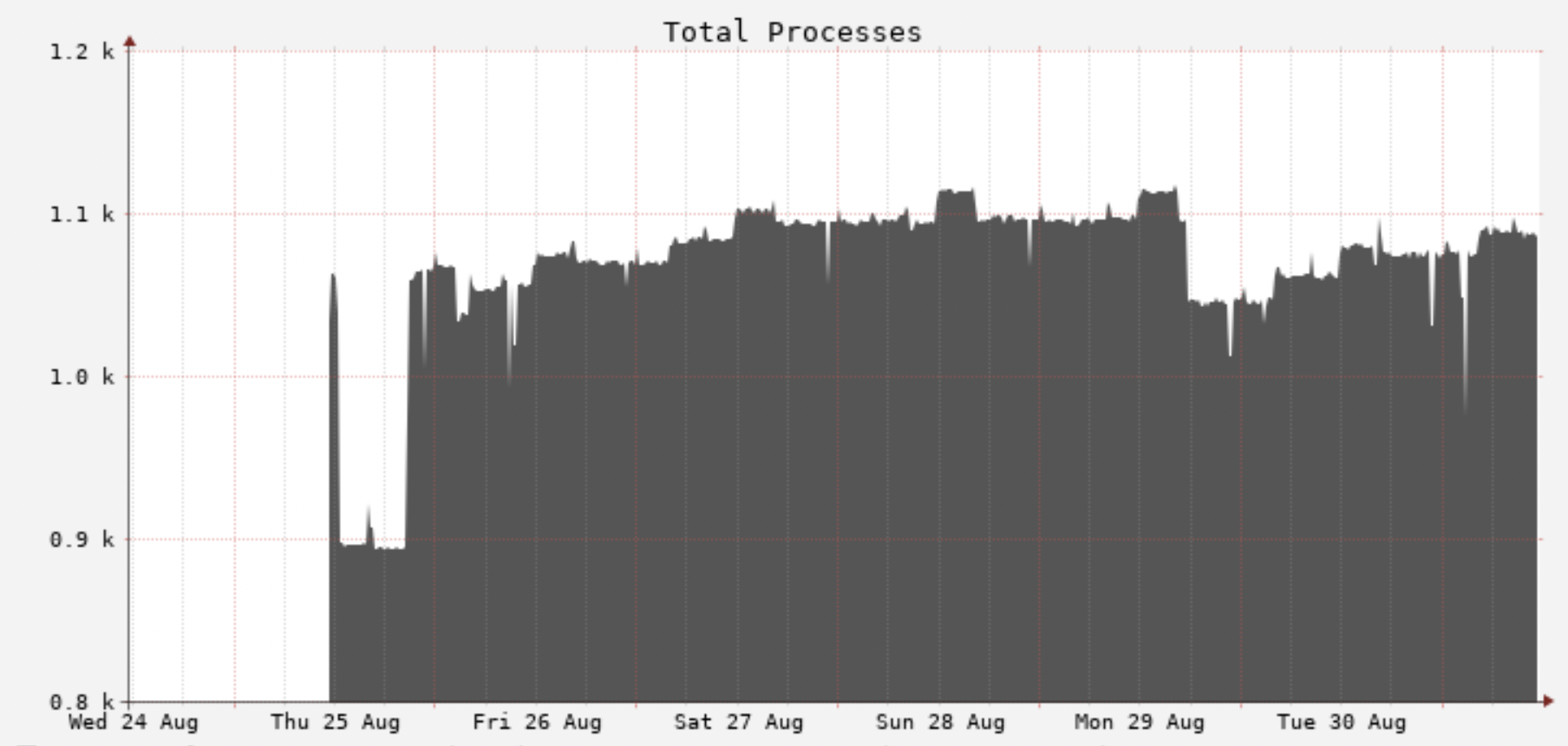
The metrics of the jobs show a good picture of what is happening. The following graph shows the total processes of the worker over time:

You can see that threads are accumulating over time. Eventually, the worker reaches the upper limit for max processes and crashes. A new worker instance is spawned and the cycle continues. The timestamp of the exception matches the timestamp of the worker crash. The end of the graph shows a dangerous outcome of the problem: it is possible that the worker is unable to restart and it stays “stuck” indefinitely. This is why the graph reaches a plateau. At this point, the worker VM needs to be restarted manually.
So far, I have explained that threads accumulate over time but I have not explained why the cosmos connector is responsible for that. I wrote a small piece of code that prints the total number of threads and the name of each thread. I injected that code into the worker VMs. Out of tens of thousands of threads, the majority of them had the prefix spark-cosmos-db-.... In case it helps, here’s the snippet:
import scala.collection.JavaConverters._
val threads = Thread.getAllStackTraces.keySet().asScala.toList
val builder = new StringBuilder
threads.map(t => t.getName).foreach(tuple => builder.append(tuple))
println(s"there are currently ${threads.size} threads ${builder.toString}")
As an extra sanity check, I removed the connector from the streaming applications. Instead, I used the delta lake connector. As expected, the total threads remain stable over time.
This bug may not be noticeable for short-living applications but it is a big problem for streaming applications that run 24/7.
Issue Analytics
- State:

- Created a year ago
- Comments:10 (6 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@achistef - Thanks! You did most of it by putting together the excellent problem description. We will also adjust our long-running release-validation tests. We didn’t clearly identify the leak there because the number of micro-batches executed was too low - we are changing the test - so chances are in the future we will identify this kind of leak earlier. So, thanks for the feedback again and please let me know if you hit any other issues in the future.
@achistef - thank you! I am working on a fix. Worst case hotfix will be available at the end of this month.