Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
gradients of Kernels / backward functions
See original GitHub issuehere is the backward function of rbf_covariance from rbf_covariance.py. I am confused what happens in that function, could you give me a hand regrading this formula, thanks!
@staticmethod
def backward(ctx, grad_output):
d_output_d_input = ctx.saved_tensors[0]
lengthscale_grad = grad_output * d_output_d_input
return None, None, lengthscale_grad, None
second question, how can I use the rbf in order to get gradients w.r.t inputs of GP (see [1]), that means that GP stays unchangeable.
[1] - https://stats.stackexchange.com/questions/373446/computing-gradients-via-gaussian-process-regression
Issue Analytics
- State:

- Created 4 years ago
- Comments:14 (1 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Lecture 13: Kernels - Cornell CS
Gradient Descent with Squared Loss. The kernel trick is a way to get around this dilemma by learning a function in the much...
Read more >Writing custom ops, kernels and gradients in TensorFlow.js
Gradients are 'high level' code (not backend specific) and can call other ops or kernels.
Read more >python - Manually/explicitly calculate gradients of Conv kernels
In a neural network I constructed, it is needed to calculate the gradients of some features and Conv kernels with respect to my...
Read more >Backwards Pass for Convolution Layer
Convolution between upstream gradient and kernel! (can implement by flipping kernel and cross- correlation). Again, all operations can be implemented ...
Read more >Gradient estimates for heat kernels and harmonic functions
(ii) (RH_p): L^p-reverse Hölder inequality for the gradients of harmonic functions; (iii) (R_p): L^p-boundedness of the Riesz transform ...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
@cherepanovic Yes, you can forward propagate through a GP just like you would any PyTorch module, and when you call
backwardon a scalar you’ll get gradients with respect to any tensors that require grad that were involved in the computation of said scalar. In general, there are lots of great PyTorch tutorials on autograd mechanisms.In your specific example, there are a few minor GPyTorch specific issues to keep in mind. First, when you backpropagate through a GP posterior in GPyTorch, you’ll want to be conscious of the fact that we compute caches for test time computation that you’ll want to clear each time through the model (since these caches explicitly assume the parameters aren’t changing). Second, as the output of a GP is a distribution and not a tensor, your arrow going from the GP to the second NN will actually need to be some operation that gives you a tensor, like sampling from the GP posterior.
Here’s a full example that does something like what you want:
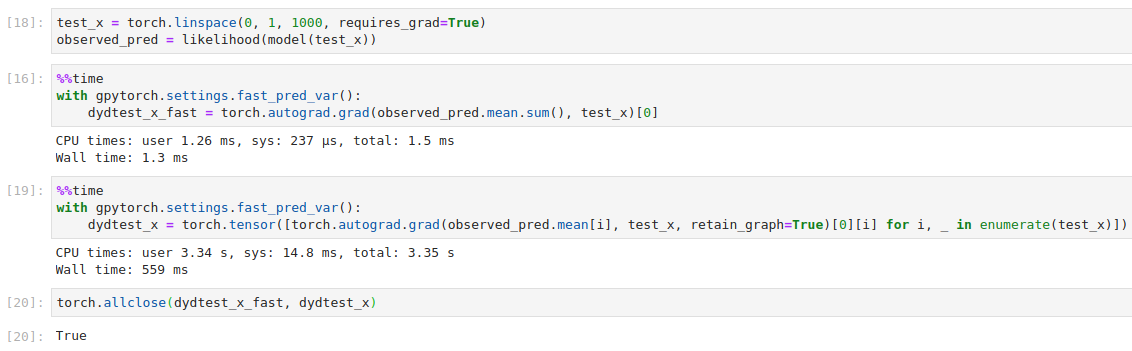
Oh actually for this special case since the derivative of the GP at each point depends only on the corresponding test point, you could do something like this instead
Speed difference: