Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
jit.rawkernel decorated function cannot be used on anothor device
See original GitHub issueWhen I trying to make the kernel function decorated by jit.rawkernel() to work on another device, it shows `“CUDA_ERROR_INVALID_HANDLE: invalid resource handle”, though it can be successfully executed on the first device.
The following code can demonstrate it more clearly…
- Code to reproduce
import cupy as cp
import cupyx as cpx
from torch.utils.dlpack import to_dlpack
from torch.utils.dlpack import from_dlpack
import numpy as np
import torch
@cpx.jit.rawkernel()
def add_one_kernel(var0, out, m, n):
tid = cpx.jit.threadIdx.x + cpx.jit.blockIdx.x * cpx.jit.blockDim.x
if tid < n:
for i in range(m):
out[i, tid] = var0[i, tid] + 1
def AddOne_cupy(var0, window, valid):
var0 = cp.fromDlpack(to_dlpack(var0))
with cp.cuda.Device(var0.device.id):
out = cp.zeros_like(var0)
add_one_kernel[64, 64](var0, out, var0.shape[0], var0.shape[1])
out = from_dlpack(out.toDlpack())
out[:window, :] = np.nan
out[~valid] = np.nan
print(f"success on device {var0.device.id}")
return out
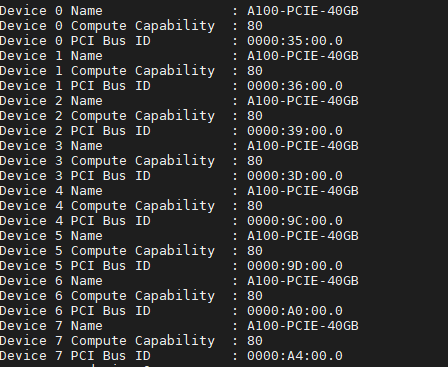
cp.show_config()
### speed test
var0 = torch.randn(2500, 4000).cuda()
valid = torch.ones(var0.shape).bool().cuda()
window=20
AddOne_cupy(var0, window, valid)
var1 = torch.randn(2500, 4000).cuda(1)
valid1 = torch.ones(var0.shape).bool().cuda(1)
AddOne_cupy(var1, window, valid1)
“success on device 0” is printed! but fail to execute on the second device
- Error messages, stack traces, or logs
Traceback (most recent call last):
File "test2.py", line 38, in <module>
AddOne_cupy(var1, window, valid1, stream1)
File "test2.py", line 19, in AddOne_cupy
add_one_kernel[64, 64](var0, out, var0.shape[0], var0.shape[1])
File "/opt/anaconda3/lib/python3.7/site-packages/cupyx/jit/_interface.py", line 123, in <lambda>
return lambda *args, **kwargs: self(grid, block, args, **kwargs)
File "/opt/anaconda3/lib/python3.7/site-packages/cupyx/jit/_interface.py", line 111, in __call__
kern(grid, block, args, shared_mem, stream, enable_cooperative_groups)
File "cupy/cuda/function.pyx", line 201, in cupy.cuda.function.Function.__call__
File "cupy/cuda/function.pyx", line 183, in cupy.cuda.function._launch
File "cupy_backends/cuda/api/driver.pyx", line 306, in cupy_backends.cuda.api.driver.launchKernel
File "cupy_backends/cuda/api/driver.pyx", line 125, in cupy_backends.cuda.api.driver.check_status
cupy_backends.cuda.api.driver.CUDADriverError: CUDA_ERROR_INVALID_HANDLE: invalid resource handle
- Conditions (you can just paste the output of
python -c 'import cupy; cupy.show_config()')- CuPy version: 9.4.0
- OS/Platform: Linux-4.18.0-147.8.1.el8_1.x86_64-x86_64-with-centos-8.1.1911-Core
- CUDA version: 11010
- cuDNN/NCCL version: 8005
Issue Analytics
- State:

- Created 2 years ago
- Comments:6 (3 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Defining __device__ kernels using cupy · Issue #1776 - GitHub
I think writing struct cuComplex and __device__ int julia( int x, int y ) definitions in the same RawKernel with __global__ function was...
Read more >Device function throws nopython exception when its returning ...
The source of your error is that the device function sub_stuff is attempting to create a list in GPU code, and that isn't...
Read more >User-Defined Kernels — CuPy 11.4.0 documentation
jit.rawkernel decorator can create raw CUDA kernels from Python functions. In this section, a Python function wrapped with the decorator is called a...
Read more >CuPy Documentation - Read the Docs
cupy.fuse() is a decorator that fuses functions. ... The cupyx.jit.rawkernel decorator can create raw CUDA kernels from Python functions.
Read more >Writing CUDA-Python — numba 0.13.0 documentation
CUDA kernels and device functions are compiled by decorating a Python function with the jit or autojit decorators. numba.cuda.jit(restype=None, ...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
Sorry for my late response. #6575 will fix this issue!
The printed cache code is as follow:
The device info: