
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
RFC: Collection-Aware HLG Layer Design for Dataframe Column Projection
See original GitHub issueSummary
The purpose of this issue is to propose a general design for collection-aware HLG-Layers in Dask. More specifically, we focus on a design that will satisfy the specific challenge of multi-layer column projection in Dask-DataFrame. In order to make this proposal self-contained, we will start by reviewing the basics of high-level graphs and column projection.
Note that a rough implementation of the changes proposed in this document can be found in #7896.
Terminology HLG = High-level graph LLG = Low-level (materialized) graph
Background
The High-Level Graph (HLG)
Click for HLG Basics
Dask is a flexible python library for parallel task scheduling and execution. At its heart is a remarkably simple graph specification: A dask graph is a dictionary that maps keys to computations. A computation may be one of the following:
- Any key present in the Dask graph
- Any other literal value
- A task
- A list of computations
Here, a key is any hashable value that is not a task, and a task is a tuple that can be used to define a required computation. The first element of a task is a callable function (like add), and the succeeding elements are arguments for that function. An argument may be any valid computation. In this document, we will also refer to a dask-graph as a “low-level graph” or a “materialized graph.”
In addition to a low-level graph representation, Dask also makes it possible to define a set of operations in the form of a high-level graph (HLG). In contrast to the low-level graph, an HLG does not require an explicit encoding of all the keys and tasks required to produce the desired output. Instead, the HLG comprises a set of abstract Layer objects, which can each lazily generate their required key-task pairs when the graph is processed by the scheduler.
The advantage of the HLG is most apparent for naturally-parallel array and dataframe workloads, where the materialized dask-graph can be both large and repetitive (i.e. the same computation is performed on many individual chunks of a larger dataset). In cases like this, there is no need to materialize every element of the graph on a client process and communicate redundant information to the scheduler process. There is also no need to materialize the full graph on the client if the user is ultimately selecting a subset of the data in question (very common in array computing).
The high-level graph concept was first introduced to Dask in 2018. However, the API was not used consistently throughout the Dask codebase until more recently. In a recent effort to accelerate client-side graph construction, processing, and communication, the HighLevelGraph API was significantly revised after the dask-2.30.0 release. For example, the current API now provides the necessary machinery to completely avoid materializing a “full” low-level task graph on the client process.
Column Projection
Column projection is a relatively simple relational-database optimization concept intended to minimize the amount of IO required for a given query operation. This optimization is already implemented in Dask-Dataframe for cases in which an explicit column selection is performed immediately after a DataFrameIOLayer (e.g. read_parquet). Take the following Dask code, for example:
ddf = dd.read_parquet(path)
ddf[“rating”].max().compute()
In this case, the user’s end goal is to calculate the maximum value in the “rating” column of the parquet dataset stored at path. To achieve this goal, it is only necessary for the read_parquet call to read the “rating” column from disk. Reading in any other data is completely unnecessary. Therefore, during the HLG optimization pass, Dask will modify the read_parquet DataFrameIOLayer tasks to include the columns argument:
ddf = dd.read_parquet(path, columns=[”rating”])
ddf[“rating”].max().compute()
The current logic for this HLG Dask-Dataframe optimization, as currently defined in optimize_dataframe_getitem, is simple:
- Make a list of all
DataFrameLayerinstances in the HLG. - For each of these instances, check if it immediately precedes a
getitem-basedBlockwiselayer. If yes, proceed to (3). If none of the layers meet this criteria, return without modifying the original HLG. - If the
getitem/Blockwiselayer is a column selection, use the project_columns method on the DataFrameLayer to modify the column selection in the underlying IO tasks. - If the
DataFrameLayerwas modified in (3), modify the dependentgetitem/Blockwiselayer to depend on the newDataFrameLayername. Note that the name of the IO layer must be modified if the column selection is changed.
Multi-Layer Column Projection
Although column projection is already implemented in Dask-Dataframe, its value is limited by the requirement that the IO layer and getitem layer are directly connected. In practice, we would also like to avoid reading in and shuffling unnecessary data for operations like set_index. For example, a powerful optimization would be to automatically change
ddf = dd.read_parquet(path)
ddf.set_index(“id”)[“rating”].persist()
to
ddf = dd.read_parquet(path, columns=[”id”, “rating”])
ddf.set_index(“id”)[“rating”].persist()
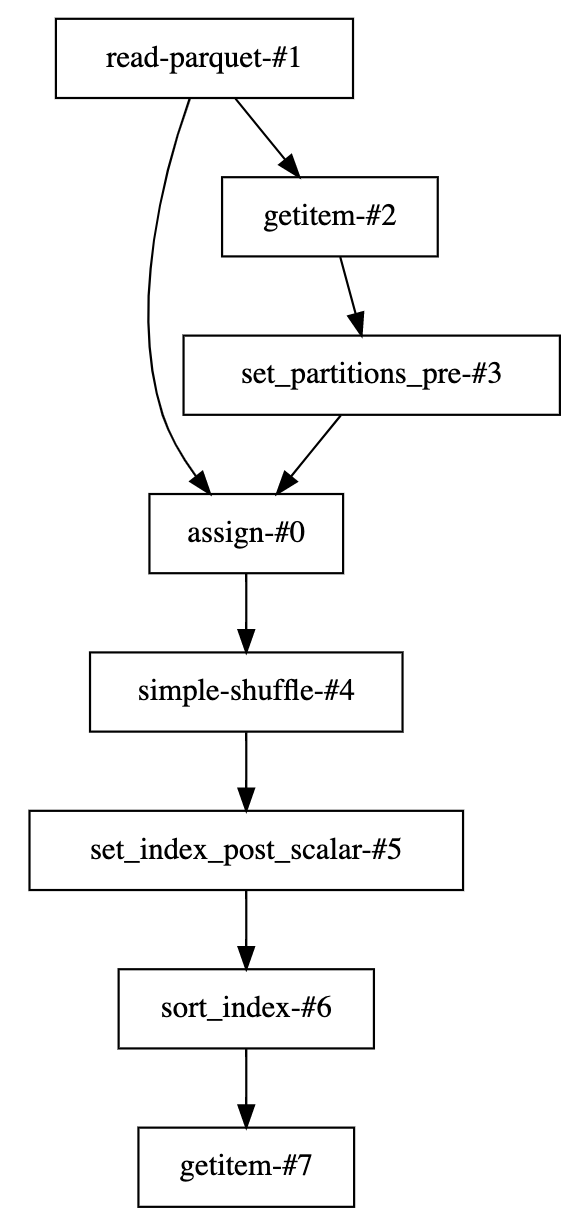
This optimization is absolutely possible in Dask-Dataframe, but the existing column-projection logic and Layer-class organization would need to be extended. The optimization logic would ultimately need to work backwards from the output HLG layer, while collecting column-dependency information for the root DataFrameIOLayer object(s). Even for the simple case of set_index, the HLG comprises many Layer instances, with non-trivial dependencies. Here is a literal visualization of the set_index HLG:
Proposed Changes
Note that most of the changes described below are roughly implemented in #7896
Step 1 - Remove project_columns from DataFrameLayer
The purpose of project_columns is to completely replace a given Layer if/when the columns handled by that Layer need to change. For column-projection, this operation is only absolutely necessary for a DataFrameIOLayer (not for the general DataFrameLayer).
Other Considerations Once project_columns is removed from DataFrameLayer, optimize_dataframe_getitem should also be changed to loop over DataFrameIOLayer instances (instead of DataFrameLayer instances).
Note that it is not completely true that a method like project_columns is never useful for non-IO Layers. It turns out that any map_partitions-based Layer using apply_and_enforce will fail if the metadata columns do not match the real columns at run time. This exact situation may occur if a map_partitions Layer is between an IO layer and a getitem layer (and column-projection occurs in the root IO layer). As discussed in Step 5, there are several possible ways to deal with this.
Step 2 - Make All DataFrame Layers Inherit from DataFrameLayer
At this point, the DataFrameLayer class will just be an alias for Layer (since we removed project_columns), but it will also provide a convenient space to define DataFrame-specific attributes in the future. Changing classes like SimpleShuffleLayer to inherit from DataFrameLayer, rather than Layer, is simple. The trickier part is dealing with Blockwise layers, since these layers can be used to operate on both Array and DataFrame collections. The proposed solution to this is to define a DataFrameBlockwise class. Although we will need to add some DataFrame specific attributes to this class to implement general column projection, we can start with a very simple definition:
class DataFrameBlockwise(Blockwise, DataFrameLayer):
pass
With this new class in place, the only thing left to do is make sure the new DataFrameBlockwise constructor is used by the Dask-Dataframe API. The good news is that Blockwise layers are typically constructed with one of the following three code paths:
partitionwise_graph -> blockwise -> Blockwiseelemwise -> partitionwise_graph -> blockwise -> Blockwisemap_partitions -> partitionwise_graph -> blockwise -> Blockwise
Therefore, ensuring that the DataFrame API will construct DataFrameBlockwise layers means that need to modify blockwise so that the calling function (i.e. partitionwise_graph) can optionally override the default Blockwise constructor with DataFrameBlockwise. For example, this can be implemented by adding a initializer=None kwarg to blockwise, which partitionwise_graph can always set to initializer=DataFrameBlockwise (while the default behavior will remain initializer=Blockwise).
Other Considerations Once the DataFrameBlockwise layer is plumbed into Dask-Dataframe, optimize_dataframe_getitem can explicitly check these types of layers for getitem operations.
Step 3 - Add required_input_columns Method to DataFrameLayer
Now that most (if not all) DataFrame-specific HLG layers inherit from DataFrameLayer, we can start adding DataFrame-specific attributes to these layers. For column projection, we need to provide a method like required_input_columns, that will tell us the required input columns needed to produce a specified set of output columns. By default, we have this method return None, which means that there is no column-dependency information available for that layer. If a layer returns None, it means we should also return None in any dependency layer (disabling column projection in the root IO layer) unless the dependency is a getitem-based DataFrameBlockwise layer. Note that some getitem-based layers can be treated as “special”, because the required input-column list is “known” (independently of the specified output-column set).
The logic needed for a specific required_input_columns definition is clearly layer specific. For some layers we will simply pass through the specified output columns as the required input columns. For others, we will have more-complex dependencies. The good news is that we do not need to have a non-default implementation for all DataFrameLayers to cover all simple column-projection cases, and many complex cases. For the case of set_index, the primary challenge is covering the common DataFrameBlockwise layers.
There are likely many ways to encode column-dependency logic for DataFrameBlockwise layers. For now, I propose a new _column_dependencies attribute that can be set via partitionwise_graph(column_dependencies=…) -> blockwise -> DataFrameBlockwise during initialization. By allowing the user to pass in a column-dependency dictionary, we can always work out the general required_input_columns logic. In the simplest case, the dictionary will simply map output column names to required input columns. To handle special cases, like getitem and assign operations, we also introduce “special” keys (like ”__known__” and “__const__”) to capture required columns that are independent of the specified output-column set).
Step 4 - Add replace_dependencies Method to Layer Class
At this point, we should have a reliable required_input_columns method on all DataFrameLayer objects, and all layers relevant for DataFrame column-projection should be DataFrameLayer instances. Therefore, we are only missing one critical requirement for general (multi-layer) column projection, and that is a simple method/utility to replace a Layer’s dependency. That is, after we perform column projection on a DataFrameIOLayer, the new IO layer will have a new name, and so any dependent layers will need to be updated with this information.
I propose that we introduce an abstract method for this in Layer (raising a NotImplementedError), and start by defining this logic only for Blockwise and the layers inheriting from DataFrameLayer.
Step 5 - Generalize optimize_dataframe_getitem
We now have all the required components in place for generalized multi-layer column projection. Instead of searching for all DataFrameIOLayers and checking if any getitem operations immediately follow. We can now start with layers that have an empty set of dependents, and call required_input_columns for every layer in the HLG while working backwards to the DataFrameIOLayer instances. If we start by specifying None as the required output columns, and finish with a non-empty set of required columns for a specific DataFrameIOLayer instance, then we know it is safe to call project_columns on that layer (and replace_dependencies on any of its dependents).
Other Considerations The only sticking point here is that we are only calling project_columns on DataFrameIOLayer instances, and are therefore only replacing IO layers with new logic. We are not, for example, modifying the metadata being used to construct any of the layers located between the IO and getitem layers. Therefore, if the underlying task in one of these “in-between” layers is explicitly validating the real data against the metadata, we can have problems.
In #7896, I have addressed this issue by adding an optional allow_column_projection option to apply_and_enforce. I think it may be reasonable to continue in this direction, and also introduce a related configuration parameter to allow the user to enable/disable multi-layer column projection in general.
The other alternative is to make an additional pass over the HLG to call project_columns on non-IO layers.
Issue Analytics
- State:

- Created 2 years ago
- Comments:7 (7 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Right. I guess that idea depends on task fusion being very good and potentially happening before the lower level graph is even materialized (not sure if that makes sense).
I’m speaking with Jim later today. I’ll do my best to nerd snipe him.