
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
`surrogate_key` macro is not adding the || with concat in dbt Version > 0.20.1
See original GitHub issueDescribe the bug
With the dbt upgrade to v1.0.0/1.0.4/1.0.5 surrogate key macro is not generating the appropriate sql code.
Steps to reproduce
(1) Create a model with surrogate key macro for more than two columns. (2) dbt run will fail because of missing ‘||’ operator inside the concat statements.
Expected results
Properly formatted sql is expected with || symbol inside the concat statement.
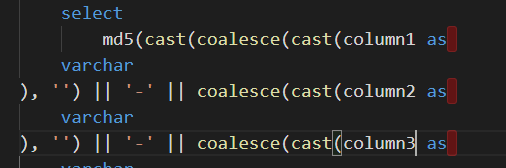
Actual results
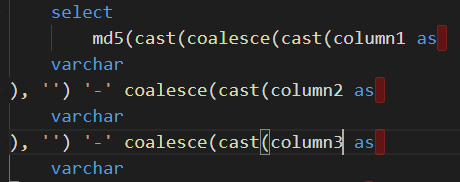
Screenshots and log output
Added above
System information
The contents of your packages.yml file:
packages:
- package: calogica/dbt_expectations version: [“>=0.5.0”, “<0.6.0”]
Which database are you using dbt with?
- postgres
- redshift
- bigquery
- snowflake
- other (specify: ____________)
The output of dbt --version:
1.0.4
Additional context
Are you interested in contributing the fix?
Issue Analytics
- State:

- Created a year ago
- Comments:7 (3 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Though, actually, this looks like the new SQL will just fail - right?
This seems like it is actually quite a significant issue…
I’d imagine a common use case for
surrogate_keyis to produce a key for an incremental model (since before 1.1.0 you could only use a single column). If the way this key is calculated has changed and people don’t do a ‘full-refresh’ on their incremental models then they’ll end up with duplicate data! In some cases a ‘full-refresh’ might not even be that feasible.I think this should be fixed ASAP and the community notified of the potential issue.