
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
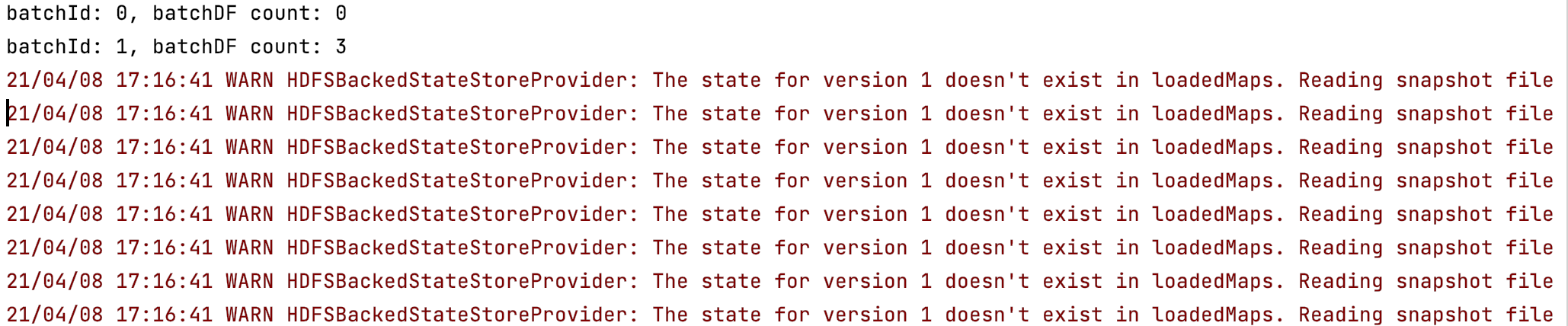
BUG: SparkStreaming in update mode with match operation to a DeltaLake sink produces "WARN HDFSBackedStateStoreProvider: The state for version 1 doesn't exist in loadedMaps" when print operations are performed in foreachbatch
See original GitHub issueI am using spark 3.0.1 and delta lake 0.8.0. I am using spark stream in update mode to write to a delta lake sink (with a match operation).
I have found out that when a println operations is performed inside a foreachBatch body, a warning message
WARN HDFSBackedStateStoreProvider: The state for version ... doesn't exist in loadedMaps. Reading snapshot file and delta files if needed...Note that this is normal for the first batch of starting query.
is generated every new data batch. However, when the println is removed in the foreachbatch operation no warning is produced.
In the code below a stream of two columns (an integer and a random label (“red”, “yellow”, “blue”)) is generated using a “rate” source. Then data is grouped by label and the integers are collected to a list. The output is written in update mode with a merge operation to a delta lake.
Please find the code below:
/* TestDataLakeError.scala */
package TestDeltaLake
import org.apache.spark.sql.{DataFrame, Encoders, Row}
import io.delta.tables._
import org.apache.spark.sql.functions.{collect_list, udf}
import scala.reflect.io.Directory
import java.io.File
import scala.util.Random
case class DeltaLakeSink(label: String, value: Array[Int])
object TestDeltaLakeError extends App {
val spark: SparkSession = {
SparkSession
.builder()
.appName("TestDeltaLake")
.master("local[*]")
.config("spark.eventLog.enabled", "false")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
}
val sc: SparkContext = spark.sparkContext
val conf = sc.hadoopConfiguration
import spark.implicits._
val deltaTablePath: String = "src/main/resources/deltalake"
val deltaLakeSchema = Encoders.product[DeltaLakeSink].schema
/**
* Get a random label among yellow, blue and red
* @return label
*/
def getRandomLabel(): String = {
val labelsList: Seq[String] = Seq("yellow", "blue", "red")
val random = new Random
labelsList(random.nextInt(labelsList.length))
}
/* create a udf for generating a column of random labels */
val getRandomLabelUDF = udf(getRandomLabel _)
/**
* Create an empty DeltaLake
* @param deltaTablePath path to deltalake
*/
def generateEmptyDeltaLake(deltaTablePath: String): Unit = {
/* Create an empty DeltaLake table */
val isDeltaTable = DeltaTable.isDeltaTable(deltaTablePath)
/* Delete and create an empty DeltaLake */
if(isDeltaTable){
val dLakeFolder = new Directory(new File(deltaTablePath))
dLakeFolder.deleteRecursively()
}
val emptyDF = {
spark
.createDataFrame(spark.sparkContext.emptyRDD[Row], deltaLakeSchema)
}
emptyDF
.write
.format("delta")
.mode("overwrite")
.save(deltaTablePath)
}
/* Generate a sample data stream grouping by labels */
val inputStreamDF: DataFrame = {
spark
.readStream
.format("rate")
.load()
.drop("timestamp")
.withColumn("label", getRandomLabelUDF())
.groupBy("label")
.agg(collect_list($"value").as("value"))
}
/**
* Function to store new batch data in delta lake
* @param batchDF input batch dataframe
* @param batchId id of the batch
*/
def upsertToDeltaLake(batchDF: DataFrame, batchId: Long): Unit = {
DeltaTable
.forPath(spark, deltaTablePath)
.as("dLakeDF")
.merge(
batchDF.as("batchDF"),
"dLakeDF.label = batchDF.label"
)
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
/* Initialise an empty delta lake */
generateEmptyDeltaLake(deltaTablePath)
/* Update new data to delta lake*/
inputStreamDF
.writeStream
.foreachBatch{
(batchDF: DataFrame, batchId: Long) =>
{
/* IF THE NEXT LINE IS COMMENTED THE WARN DOES NOT HAPPEN */
println(s"batchId: ${batchId}, batchDF count: ${batchDF.count()}")
upsertToDeltaLake(batchDF, batchId)
}
}
.outputMode("update")
.start()
.awaitTermination()
}
Issue Analytics
- State:

- Created 2 years ago
- Comments:6 (4 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
good point @jaceklaskowski I was assuming that the upsert function was trigger all the Spark job to compute the streaming state anyways. my new guess is that the warning is somehow caused by making multiple jobs on the same foreachBatch dataframe. again, its not a correctness issue as the state management should be robust to extra reloading of state stores, and the multiple jobs in foreach batch is hitting that rare, but correctly handled corner case of the state management causing warnings. either way definitely not a delta issue, hence closing this ticket.
Yes, the following batches print the same warning:
In any case I totally agree with you. Indeed leaving
batchDF.count()but removing theprintlngenerates the same issue