
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Training is not progressing with optuna [question]
See original GitHub issueI’m building my own custom mini-grid environment.
Now when I’m using optuna for hyperparameter tuning the iteration is not progressing it is just iterating on the first epoch and not moving on the next step
Here is the overview of the environment:-
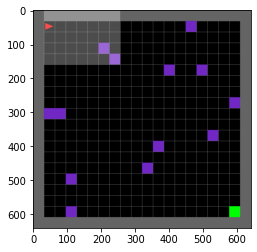
Obstacle Class:-
class nfa(WorldObj):
def __init__(self, color='purple'):
super().__init__('ball', color)
def can_overlap(self):
"""Can the agent overlap with this?"""
return True
def render(self, img):
fill_coords(img, point_in_rect(0, 1, 0, 1), COLORS[self.color])
Environment Class:-
class airforce(MiniGridEnv):
def __init__(self, size, seed=None):
super().__init__(
grid_size=size,
max_steps=10*size*size,
# Set this to True for maximum speed
see_through_walls=False,
seed=None
)
self.reward_range = (-10, 10)
def _gen_grid(self, width, height):
assert width >= 5 and height >= 5
# Create an empty grid
self.grid = Grid(width, height)
# Generate the surrounding walls
self.grid.wall_rect(0, 0, width, height)
# Place the agent in the top-left corner
self.agent_pos = (1, 1)
self.agent_dir = 0
# Place a goal square in the bottom-right corner
self.goal_pos = np.array((width - 2, height - 2))
self.put_obj(Goal(), *self.goal_pos)
#generate official locations 3
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((random.randint(2,width-4),random.randint(2,width-4)))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((1,9))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((14,1))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((3,height-2))
self.put_obj(nfa('purple'), *self.wall_pos)
self.wall_pos = np.array((width-2,8))
self.put_obj(nfa('purple'), *self.wall_pos)
self.mission = (
"avoid the official location and attacking system and get to the green goal square"
)
def _reward(self):
"""
Compute the reward to be given upon success
"""
return 1
def step(self, action):
self.step_count += 1
reward = 0
done = False
# Get the position in front of the agent
fwd_pos = self.front_pos
# Get the contents of the cell in front of the agent
fwd_cell = self.grid.get(*fwd_pos)
# Rotate left
if action == self.actions.left:
self.agent_dir -= 1
if self.agent_dir < 0:
self.agent_dir += 4
# Rotate right
elif action == self.actions.right:
self.agent_dir = (self.agent_dir + 1) % 4
# Move forward
elif action == self.actions.forward:
if fwd_cell == None or fwd_cell.can_overlap():
self.agent_pos = fwd_pos
if fwd_cell != None and fwd_cell.type == 'goal':
reward = 1
done = True
if fwd_cell != None and fwd_cell.type == 'lava': # attacking system
reward= -0.5
# done = True
if fwd_cell != None and fwd_cell.type == 'box': #outersensor
reward= -0.1
if fwd_cell != None and fwd_cell.type == 'key': #innersensor
reward= -0.2
if fwd_cell != None and fwd_cell.type == 'ball': # non flying zone
reward= -1
# done = True
# Pick up an object
elif action == self.actions.pickup:
if fwd_cell and fwd_cell.can_pickup():
if self.carrying is None:
self.carrying = fwd_cell
self.carrying.cur_pos = np.array([-1, -1])
self.grid.set(*fwd_pos, None)
# Drop an object
elif action == self.actions.drop:
if not fwd_cell and self.carrying:
self.grid.set(*fwd_pos, self.carrying)
self.carrying.cur_pos = fwd_pos
self.carrying = None
# Toggle/activate an object
elif action == self.actions.toggle:
if fwd_cell:
fwd_cell.toggle(self, fwd_pos)
# Done action (not used by default)
elif action == self.actions.done:
pass
else:
assert False, "unknown action"
# if self.step_count >= 20000:
# reward = -200
# done = True
obs = self.gen_obs()
return obs, reward, done, {}
def reset(self):
# Current position and direction of the agent
self.agent_pos = None
self.agent_dir = None
# Generate a new random grid at the start of each episode
# To keep the same grid for each episode, call env.seed() with
# the same seed before calling env.reset()
self._gen_grid(self.width, self.height)
# These fields should be defined by _gen_grid
assert self.agent_pos is not None
assert self.agent_dir is not None
# Check that the agent doesn't overlap with an object
start_cell = self.grid.get(*self.agent_pos)
assert start_cell is None or start_cell.can_overlap()
# Item picked up, being carried, initially nothing
self.carrying = None
# Step count and penalty since episode start
self.step_count = 0
self.penalty = 0
# Return first observation
obs = self.gen_obs()
return obs
env = airforce(size=20)
Optuna Code:-
from typing import Any, Dict
from torch import nn
def ppo_params(trial: optuna.Trial) -> Dict[str, Any]:
"""
Sampler for PPO hyperparams.
:param trial:
:return:
"""
batch_size = trial.suggest_categorical("batch_size", [8, 16, 32, 64, 128, 256, 512])
n_steps = trial.suggest_categorical("n_steps", [512, 1024, 2048])
gamma = trial.suggest_categorical("gamma", [0.9, 0.95, 0.98, 0.99, 0.995, 0.999, 0.9999])
learning_rate = trial.suggest_loguniform("learning_rate", 1e-5, 1)
lr_schedule = "constant"
# Uncomment to enable learning rate schedule
# lr_schedule = trial.suggest_categorical('lr_schedule', ['linear', 'constant'])
ent_coef = trial.suggest_loguniform("ent_coef", 0.00000001, 0.1)
clip_range = trial.suggest_categorical("clip_range", [0.1, 0.2, 0.3, 0.4])
n_epochs = trial.suggest_categorical("n_epochs", [1, 5, 10, 20])
gae_lambda = trial.suggest_categorical("gae_lambda", [0.8, 0.9, 0.92, 0.95, 0.98, 0.99, 1.0])
max_grad_norm = trial.suggest_categorical("max_grad_norm", [0.3, 0.5, 0.6, 0.7, 0.8, 0.9, 1, 2, 5])
vf_coef = trial.suggest_uniform("vf_coef", 0, 1)
net_arch = trial.suggest_categorical("net_arch", ["small", "medium"])
# Uncomment for gSDE (continuous actions)
# log_std_init = trial.suggest_uniform("log_std_init", -4, 1)
# Uncomment for gSDE (continuous action)
# sde_sample_freq = trial.suggest_categorical("sde_sample_freq", [-1, 8, 16, 32, 64, 128, 256])
# Orthogonal initialization
ortho_init = False
# ortho_init = trial.suggest_categorical('ortho_init', [False, True])
# activation_fn = trial.suggest_categorical('activation_fn', ['tanh', 'relu', 'elu', 'leaky_relu'])
activation_fn = trial.suggest_categorical("activation_fn", ["tanh", "relu"])
# TODO: account when using multiple envs
if batch_size > n_steps:
batch_size = n_steps
if lr_schedule == "linear":
learning_rate = linear_schedule(learning_rate)
# Independent networks usually work best
# when not working with images
net_arch = {
"small": [dict(pi=[64, 64], vf=[64, 64])],
"medium": [dict(pi=[256, 256], vf=[256, 256])],
}[net_arch]
activation_fn = {"tanh": nn.Tanh, "relu": nn.ReLU, "elu": nn.ELU, "leaky_relu": nn.LeakyReLU}[activation_fn]
return {
"n_steps": n_steps,
"batch_size": batch_size,
"gamma": gamma,
"learning_rate": learning_rate,
"ent_coef": ent_coef,
"clip_range": clip_range,
"n_epochs": n_epochs,
"gae_lambda": gae_lambda,
"max_grad_norm": max_grad_norm,
"vf_coef": vf_coef,
# "sde_sample_freq": sde_sample_freq,
"policy_kwargs": dict(
# log_std_init=log_std_init,
net_arch=net_arch,
activation_fn=activation_fn,
ortho_init=ortho_init,
),
}
def optimize_agent(trial):
""" Train the model and optimize
Optuna maximises the negative log likelihood, so we
need to negate the reward here
"""
model_params = ppo_params(trial)
env = make_vec_env(lambda: make_env())
model = PPO('MlpPolicy', env, verbose=0, **model_params)
model.learn(90000)
mean_reward, _ = evaluate_policy(model, env, n_eval_episodes=5)
return -1 * mean_reward
study = optuna.create_study(direction='maximize')
study.optimize(optimize_agent, n_trials=10)
I’m using flaobswrapper and monitor wrapper for wrapping the environment.
This is what happening it is not progressing even after 30 minutes
[I 2021-07-22 07:39:57,317] A new study created in memory with name: no-name-20591f96-48ab-49c6-9ce2-7eea95c0c44c
Issue Analytics
- State:

- Created 2 years ago
- Comments:10 (2 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks for your help and fast reply you guys are the best. I tried with smaller environment and it is working The problem is
evaluate_policyis a little slow in giving results with my environment since I removed the steps constraint but now it is solved.Thanks again.
I have removed that constraint so that my agent can explore but the problem is it is not printing the first reward which shows that model is not predicting the next state