
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Unexpected result from using wav2vec 2.0 features for keyword spotting
See original GitHub issueHi, I’m trying to extract features using wav2vec 2.0 to do keyword spotting (with Dynamic Time Warping), but I’m getting some unexpected results when computing a distance matrix between two feature matrices using the XLSR53 checkpoint for feature extraction.
Say, for example, I have two audio files hello.wav and goodbye-hello-goodbye.wav. When I use librosa to extract MFCCs from each of these files and then compute a distance matrix, I get the expected outcome: a diagonal band showing a spectro-temporal correlation where the ‘hello’ is in the middle of the 2nd phrase.

Doing the same calculations but using features from wav2vec 2.0, however, gives me this:

I’m not sure if I’ve misunderstood the nature of the wav2vec 2.0 features and am mis-using it (let me know if that’s the case), or I’m missing something in the feature extraction process. To do feature extraction, I’m using the code that I found in #3134.
Thanks!
Code
import fairseq
import torch
import torchaudio
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
# Downloaded from https://dl.fbaipublicfiles.com/fairseq/wav2vec/xlsr_53_56k.pt on 2021-01-27
wav2vec2_checkpoint_path = "xlsr_53_56k.pt"
# Code from https://github.com/pytorch/fairseq/issues/3134#issuecomment-761110102
checkpoint = torch.load(wav2vec2_checkpoint_path)
wav2vec2_encoder = fairseq.models.wav2vec.Wav2Vec2Model.build_model(checkpoint['cfg']['model'])
wav2vec2_encoder.load_state_dict(checkpoint['model'])
q_dat, q_sr = torchaudio.load("hello.wav")
r_dat, r_sr = torchaudio.load("goodbye-hello-goodbye.wav")
# Resample to 16 kHz
q_dat = torchaudio.transforms.Resample(q_sr, 16000)(q_dat)
r_dat = torchaudio.transforms.Resample(r_sr, 16000)(r_dat)
# Extract features
query_wav2vec2 = wav2vec2_encoder(q_dat, features_only=True, mask=False)['x'].detach().numpy().squeeze()
reference_wav2vec2 = wav2vec2_encoder(r_dat, features_only=True, mask=False)['x'].detach().numpy().squeeze()
# Calculate distance matrix
qr_dists_w2v2 = cdist(query_wav2vec2, reference_wav2vec2, 'euclidean', V = None) # Calculate distance matrix
qr_dists_w2v2 = ((qr_dists_w2v2 - qr_dists_w2v2.min())/(qr_dists_w2v2.max() - qr_dists_w2v2.min())) # Normalized to [0, 1]
# Plot distance matrix
plt.imshow(qr_dists_w2v2, interpolation='none')
plt.show()
What’s your environment?
Google CoLab: https://colab.research.google.com/drive/1_QfbOd1UyQ4d358G54DF53p36vsuJiRp
- fairseq Version (e.g., 1.0 or master): 1.0.0a0+148327d
- PyTorch Version (e.g., 1.7.1): 1.7.1
- OS (e.g., Linux): Ubuntu 18.04 (Google CoLab)
- How you installed fairseq (
pip, source):pip install git+https://github.com/pytorch/fairseq.git - Python version: 3.6.9
Issue Analytics
- State:

- Created 3 years ago
- Reactions:1
- Comments:14 (1 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks for your suggestion @alexeib! However, it seems that probing the different transformer layers does not help in solving the problem. Similar to @fauxneticien, I computed the distance matrix between the audio samples provided in https://github.com/pytorch/fairseq/issues/3181#issue-797288871 using features from the different transformer layers. Meaningful results are obtained for the monolingual wav2vec 2.0 model, but not for the multilingual model (visualizations using features from layer 5, 10, 15, and the top layer are shown below).
Monolingual model, layer 5: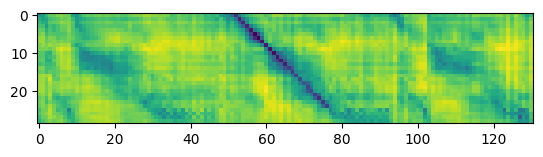
Multilingual model, layer 5: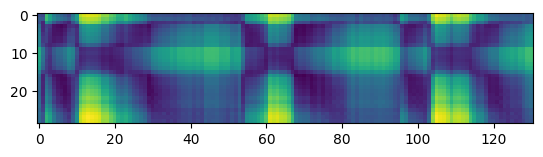
Monolingual model, layer 10: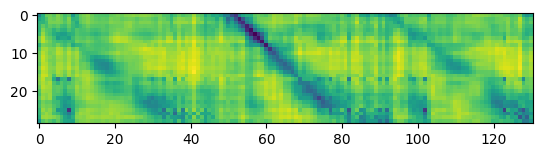
Multilingual model, layer 10: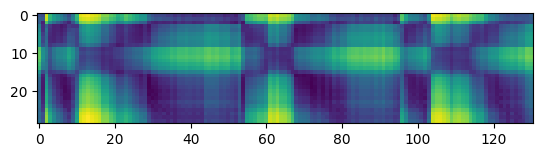
Monolingual model, layer 15: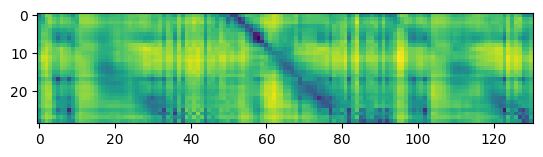
Multilingual model, layer 15: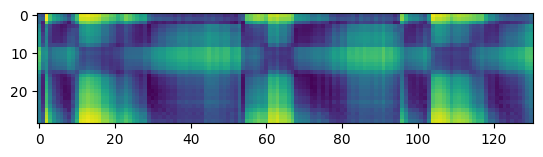
Top layer monolingual model: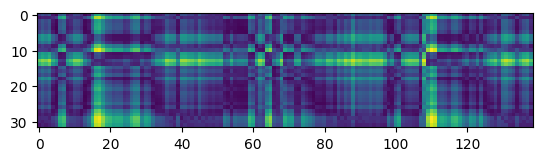
Top layer multilingual model: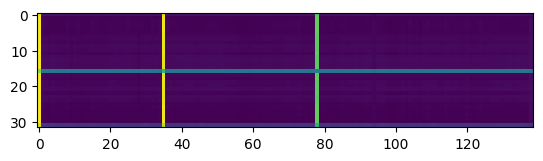
Could you indicate if you have seen or obtained meaningful results by probing the different transformer layers in the multilingual model?
Thanks @mdda — I’m not that technically proficient with digging inside models, but I’ve tried adapting some extraction code from a colleague of mine (see original code here).
For this code, I load the model in as follows:
Then, for feature extraction, I can use:
I don’t quite get what’s going on but this seems to produce more reasonable outputs:
Features for
hello.wav(note time on x axis):Features for
goodbye-hello-goodbye.wav:Distance matrix between two feature matrices (note the expected diagonal band):
At the same time, I can’t seem to get it to work with my colleague’s layer extraction code. As reported here, Martijn found that using the middle layers (e.g. layer 10) from the wav2vec 2.0 English model offered better representations for doing automated pronunciation comparisons than the output layer, which he suspected was better suited for the original training task. In any case, trying this code with the XLSR model:
Presumably
extract_w2v2_feats(wav_data, None)should return the same final layer output as the code above (since thei == layer_icondition is never satisfied), but alas:hello.wavis:goodbye-hello-goodbye.wavis:And the distance matrix is: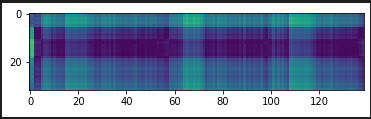
But I gather the XSLR model internals may be different to the mono-lingual models, so we might need to play with the code a bit to get this aspect to work (if any maintainers have clues on how to approach this, that’d be a big help!). Hope the first part helps, @mdda!