
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Extremely unstable training on multiple gpus
See original GitHub issueHi, I’m trying to reproduce the classification training results.
I tried on 2 different machines, machine A with one RTX 3090 and machine B with four A100 gpus.
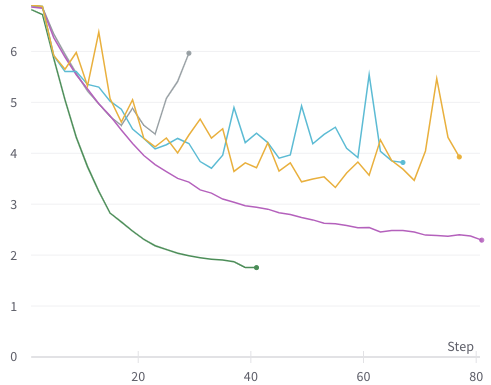
The training on machine A with a single GPU is fine; see green line (with default parameters). But on machine B with 4 gpus, it’s not training properly and very erratic; see gray, yellow, teal lines (with default and custom parameters). Purple line is DeiT training on the same machine B (default parameters).
All experiments done with --batch-size=128 (128 samples per gpu).
This is validation loss, other metrics tell the same story, some even worse.
Example of the commands I used:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py \
--model xcit_small_12_p16 --batch-size 128 --drop-path 0.05 --epochs 400
Anyone’s seen this or know how to fix it? Many thanks.
Issue Analytics
- State:

- Created 2 years ago
- Reactions:1
- Comments:7 (2 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Most of my (unstable) runs were done with a completely fresh clone of the repo, And I believe the conda environment is fresh from a docker build as well, But I’ll try to double-check/re-run and report back, many thanks.
I have run the same command you used above:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py \ --model xcit_small_12_p16 --batch-size 128 --drop-path 0.05 --epochs 400The training seems to be behaving as expected, the logs are here: https://gist.github.com/aelnouby/540738cf88dda6a2fa5197915d1f2931
I am not sure where is the discrepancy. Could you try to re-run with a fresh clone of the repo and a fresh conda environment ?