
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Feast API: Adding a new historical store
See original GitHub issue1. Introduction
We’ve had a lot of demand for either open source or AWS batch stores (#367, #259). Folks from the community have asked us how they can contribute code to add their stores types.
In this issue I will walk through how batch stores are currently being used and how a new batch store type can be added.
2. Overview
Feast interacts with a batch store in two places
- Data ingestion: Ingestion jobs that load data into stores must be able to locate stores, apply migrations, and write data into feature set tables.
- Feature serving (batch): Feast serving executes batch retrieval jobs in order for users to export historical feature data.
3. Data ingestion
Feast creates and manages population jobs that stream in data from upstream data sources. Currently Feast only supports Kafka as a data source, meaning these jobs are all long running. Batch ingestion pushes data to Kafka topics after which they are picked up by these “population” jobs.
In order for the ingestion + population flow to complete, the destination store must be writable. This means that Feast must be able to create the appropriate tables/schemas in the store and also write data from the population job into the store.
Currently Feast Core starts and manages these population jobs that ingest data into stores, although we are planning to move this responsibility to the serving layer. Feast Core starts an Apache Beam job which synchronously runs migrations on the destination store and subsequently starts consuming from Kafka and publishing records.
Below is a “happy-path” example of a batch ingestion process:
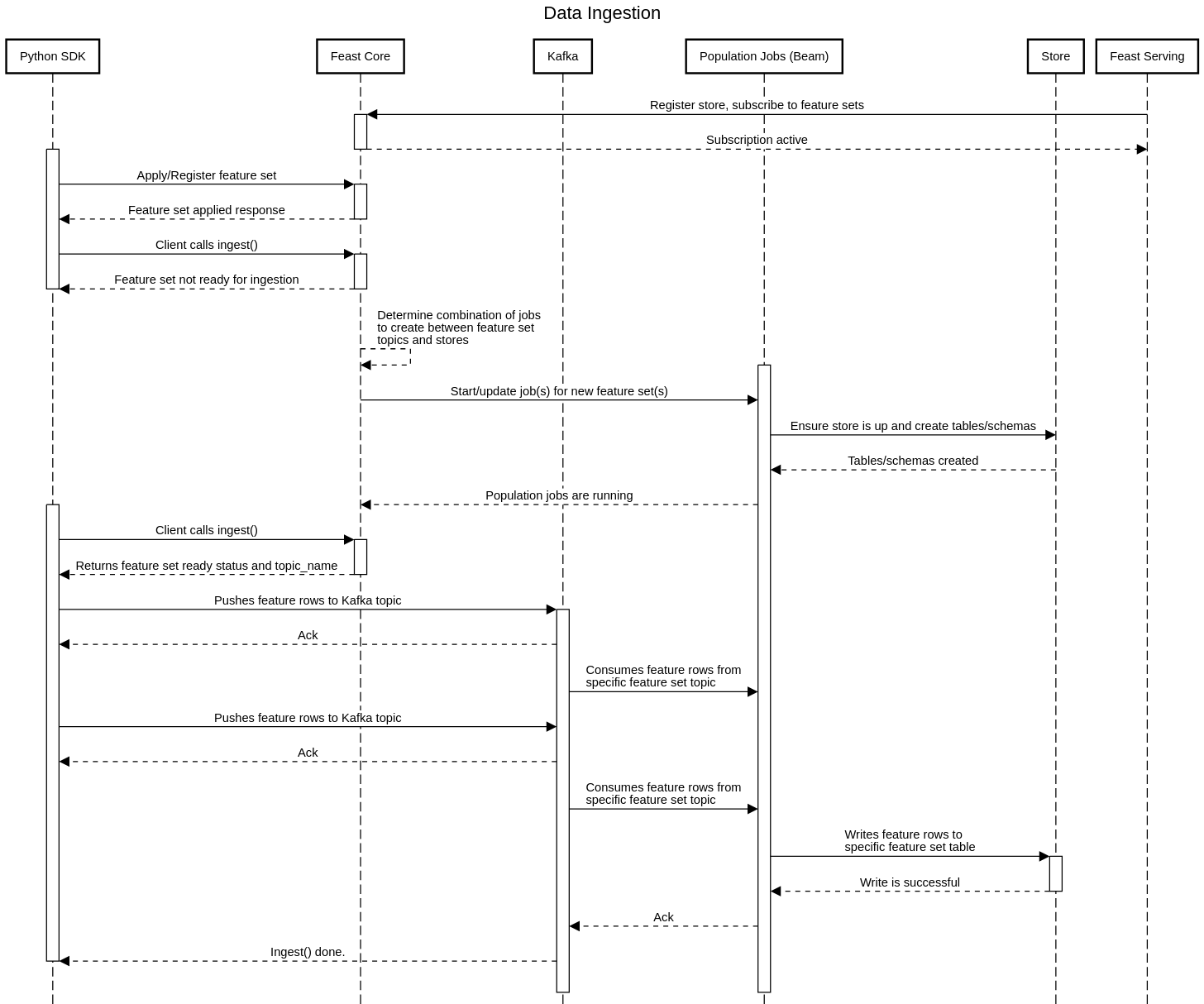
In order to accommodate a new store type, the Apache Beam job needs to be updated to support
- Setup (create tables/schemas): The current implementation for BigQuery/Redis is captured in StoreUtil.java
- Writes: A store specific client needs to be implemented that can write to a new store type in WriteToStore.java
4. Feature serving (batch)
Feast Serving is a web service that allows for the retrieval of feature data from a batch feature store. Below is a sequence diagram for a typical feature request from a batch store.

Currently we only have support for BigQuery has a batch store. The entry point for this implementation is the BigQueryServingService, which extends the ServingService interface.
public interface ServingService {
GetFeastServingInfoResponse getFeastServingInfo(GetFeastServingInfoRequest getFeastServingInfoRequest);
GetOnlineFeaturesResponse getOnlineFeatures(GetOnlineFeaturesRequest getFeaturesRequest);
GetBatchFeaturesResponse getBatchFeatures(GetBatchFeaturesRequest getFeaturesRequest);
GetJobResponse getJob(GetJobRequest getJobRequest);
}
The ServingService is called from the wrapping gRPC service ServingService, where the functionality is more clearly described.
The interface defines the following methods
- getFeastServingInfo: Get the store type, either online or offline.
- getOnlineFeatures: Get online features synchronously.
- getBatchFeatures: Get batch features asynchronously. Retrieval for batch features always happens asynchronously, because of the time taken for an export to complete. This method returns immediately with a JobId to the client. The client can then poll the job status until the query has reached a terminal state (succeeded or failed).
- getJob: Should return the Job status for a specific Job Id
Notes on the current design:
Although the actual functionality will be retained, the structure of these interfaces will probably change away from extending a service interface and towards having a store interface. There are various problems with the current implementation
- Batch and online stores share a single interface. I believe the intention here was to allow some stores to support both online and historical/batch storage, but for most stores this isn’t the case. There is also no reason why we can’t have two interfaces here. Ideally this should be split in two.
- The current approach is to extend services for each new store type, but this seems to be a poor abstractions. Ideally we would have both a batch and online store interface (not service interface), which is called from a single serving implementation. This approach would be a clearer separation of concerns and would prevent things like job management happening within a service implementation.
Issue Analytics
- State:

- Created 4 years ago
- Reactions:1
- Comments:34 (19 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@kenny-bui-slalom we are working on bringing Feast to Azure by;
This is just a preview, we will have the full proposal in a couple of days.
We will also be using managed services, you can turn off deployment of Postgres/Kafka etc in the Helm chart.
/cc @algattik @woop @ches
@nfplay I am looking at Azure support, please keep in touch.