
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Rethinking the Queue class to get full GPU utilization
See original GitHub issueThis is a really nice framework, however a serious issue for me is (the lack of) GPU utilization. This is an issue even with only a simple ZNormalization and a left right flip of the data as augmentation. This results in the following GPU utilization:
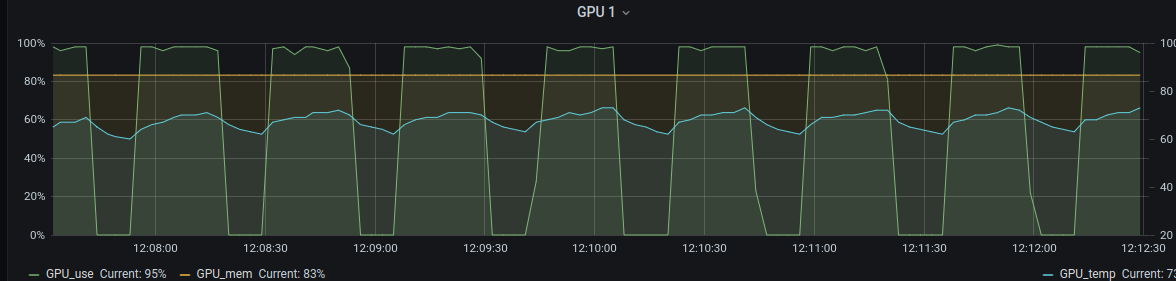
This is a training with 5 subjects and sampling 40 patches per volume and batch size 8. After every 25 iterations (which means 200 patches) there is a gap and the GPU utilization is 0.
What I did is building a custom Queue class in which I tried to get full GPU utilization. The result is as follows:
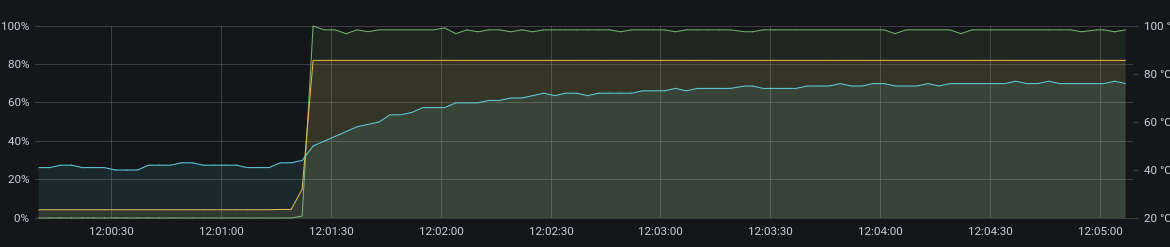 As you can see this has a GPU utilization of ~100% without gaps (0 utilization is before the start).
As you can see this has a GPU utilization of ~100% without gaps (0 utilization is before the start).
I tried to use the existing PyTorch data functionalities as much as possible. The BufferedShuffleDataset is something that is not yet in the release, but seems to be in the next release. The idea behind it is the same as for the shuffle() in Tensorflow data.
Here is the code that I made:
import random
from itertools import islice
from typing import Iterator, List
import torch
torch.multiprocessing.set_sharing_strategy('file_system')
from torch.utils.data import DataLoader, IterableDataset
from torch.utils.data.dataset import T_co
from torchio.data import PatchSampler
# https://github.com/pytorch/pytorch/commit/96540e918c4ca3f0a03866b9d281c34c65bd76a4#diff-425b66e1ff01d191679c386258a7156dfb5aacd64a8e0947b24fbdebcbee8529
class BufferedShuffleDataset(IterableDataset[T_co]):
r"""Dataset shuffled from the original dataset.
This class is useful to shuffle an existing instance of an IterableDataset.
The buffer with `buffer_size` is filled with the items from the dataset first. Then,
each item will be yielded from the buffer by reservoir sampling via iterator.
`buffer_size` is required to be larger than 0. For `buffer_size == 1`, the
dataset is not shuffled. In order to fully shuffle the whole dataset, `buffer_size`
is required to be greater than or equal to the size of dataset.
When it is used with :class:`~torch.utils.data.DataLoader`, each item in the
dataset will be yielded from the :class:`~torch.utils.data.DataLoader` iterator.
And, the method to set up a random seed is different based on :attr:`num_workers`.
For single-process mode (:attr:`num_workers == 0`), the random seed is required to
be set before the :class:`~torch.utils.data.DataLoader` in the main process.
>>> ds = BufferedShuffleDataset(dataset)
>>> random.seed(...)
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
For multi-process mode (:attr:`num_workers > 0`), the random seed is set by a callable
function in each worker.
>>> ds = BufferedShuffleDataset(dataset)
>>> def init_fn(worker_id):
... random.seed(...)
>>> print(list(torch.utils.data.DataLoader(ds, ..., num_workers=n, worker_init_fn=init_fn)))
Arguments:
dataset (IterableDataset): The original IterableDataset.
buffer_size (int): The buffer size for shuffling.
"""
dataset: IterableDataset[T_co]
buffer_size: int
def __init__(self, dataset: IterableDataset[T_co], buffer_size: int) -> None:
super(BufferedShuffleDataset, self).__init__()
assert buffer_size > 0, "buffer_size should be larger than 0"
self.dataset = dataset
self.buffer_size = buffer_size
def __iter__(self) -> Iterator[T_co]:
buf: List[T_co] = []
for x in self.dataset:
if len(buf) == self.buffer_size:
idx = random.randint(0, self.buffer_size - 1)
yield buf[idx]
buf[idx] = x
else:
buf.append(x)
random.shuffle(buf)
while buf:
yield buf.pop()
class PatchesDataset(IterableDataset):
def __init__(self, subjects_dataset, sampler, samples_per_volume):
self.subjects_dataset = subjects_dataset
self.sampler = sampler
self.samples_per_volume = samples_per_volume
def __iter__(self):
while True:
idx = random.randint(0, len(self.subjects_dataset) - 1)
sample = self.subjects_dataset[idx]
iterable = self.sampler(sample)
patches = list(islice(iterable, self.samples_per_volume))
yield patches
class Queue(IterableDataset):
def __init__(
self,
subjects_dataset: PatchesDataset,
max_length: int,
samples_per_volume: int,
sampler: PatchSampler,
num_workers: int = 0,
shuffle_subjects: bool = True,
shuffle_patches: bool = True,
verbose: bool = False,
):
self.dataset = PatchesDataset(subjects_dataset, sampler, samples_per_volume)
self.max_length = max_length
self.loader = DataLoader(self.dataset,
batch_size=None,
num_workers=num_workers,
persistent_workers=True)
self.buffer = []
def __iter__(self):
# Basically this is an unbatch operation
for patches_list in self.loader:
for patch in patches_list:
yield patch
As you can see I had to do:
import torch
torch.multiprocessing.set_sharing_strategy('file_system')
because otherwise I got this error: RuntimeError: received 0 items of ancdata
This may be something in the system that I use, but it seems to be a more common thing, see: https://github.com/pytorch/pytorch/issues/973
With using this custom implementation I could use:
# patches_queue = tio.Queue(
# self.dataset,
# max_length=self.queue_length,
# samples_per_volume=self.samples_per_volume,
# sampler=sampler,
# num_workers=self.num_workers,
# verbose=False
# )
# use the custom queue instead of the default one
queue = Queue(self.dataset,
max_length=self.queue_length,
samples_per_volume=self.samples_per_volume,
sampler=sampler,
num_workers=self.num_workers,
verbose=False)
patches_queue = BufferedShuffleDataset(queue, self.queue_length)
patches_loader = DataLoader(patches_queue, batch_size=self.batch_size)
What do you think of this? Could this replace or exist next to the existing tio.Queue?
Issue Analytics
- State:

- Created 3 years ago
- Reactions:3
- Comments:17 (13 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
To come back to this issue. The implementation now looks like this
To use it:
For my use case this gives good gpu utilization and a big speed up. But it would be good to also know about other use cases. Shall I submit a pull request?
I will test and work it out a bit more and then submit a PR