Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Big performance discrepancy between JAX and TensorFlow with in-place updates
See original GitHub issueHi,
I am trying to understand what’s causing JAX to perform 100-1000x slower compared to TensorFlow on the following computation.
JAX version:
@jit
def f_jax(p0, p1):
n, _ = p0.shape
P = jnp.concatenate([p0[None], p1[None], jnp.empty([n - 2, n, n])])
def body(P, i):
X = P[i - 1] @ P[i - 2]
X /= X.sum(1, keepdims=True)
return P.at[i].set(X), None
P, _ = jax.lax.scan(body, P, jnp.arange(2, n))
return P[-1, 0, 0]
df_jax = jit(grad(f_jax))
Here is an equivalent implementation in TF:
@tf.function
def f_tf(p0, p1):
n, _ = p0.shape
P = (
tf.TensorArray(tf.float32, size=n, infer_shape=True, clear_after_read=False)
.write(0, p0)
.write(1, p1)
)
def body(P, i):
X = P.read(i - 1) @ P.read(i - 2)
X /= tf.reduce_sum(X, axis=1, keepdims=True)
return P.write(i, X)
_, P = tf.while_loop(lambda i, P: i < n, lambda i, P: (i + 1, body(P, i)), (2, P))
return P.read(n - 1)[0, 0]
@tf.function
def df_tf(p0, p1):
with tf.GradientTape() as g:
g.watch(p0)
y = f_tf(p0, p1)
return g.gradient(y, p0)
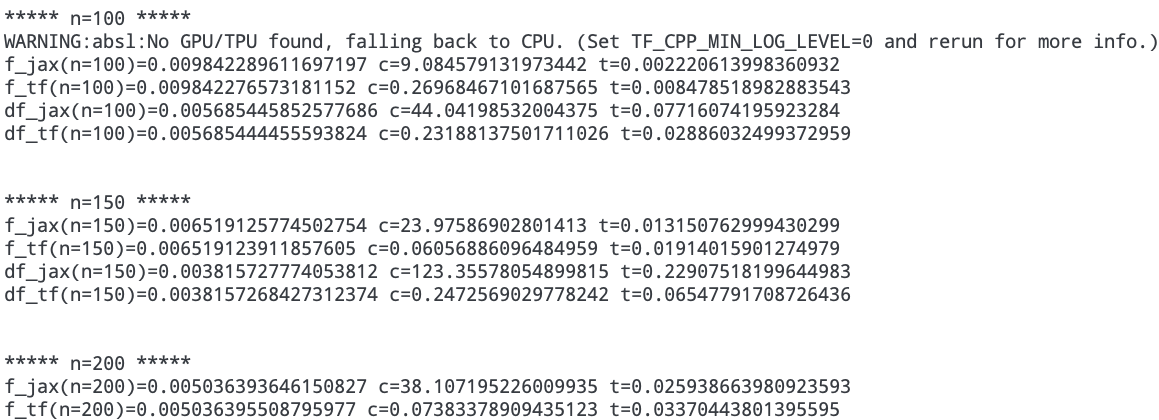
We have noticed that as the input size n increases, JAX (specifically the gradient computation) is 2-3 orders slower than TF (note log scale):
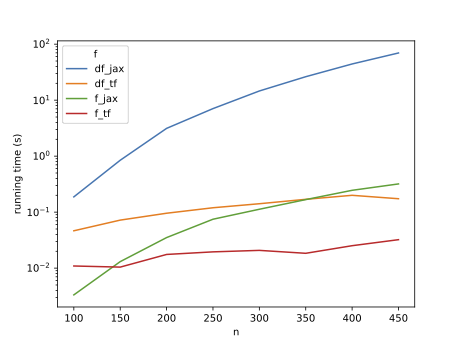
(This is after accounting for compilation time and async dispatch.)
Of course, the implementation shown above does not need in-place updates at all; it’s my attempt to distill our problem down to an MRE. Rewritten more sanely as
@jit
def f_jax(p0, p1):
n, _ = p0.shape
def body(tup, _):
X1, X0 = tup
X2 = X1 @ X0
X2 /= X2.sum(1, keepdims=True)
return (X2, X1), None
(P, _), _ = jax.lax.scan(body, (p1, p0), None, length=n - 2)
return P[0, 0]
and equivalently in TF, the difference persists but is less dramatic:
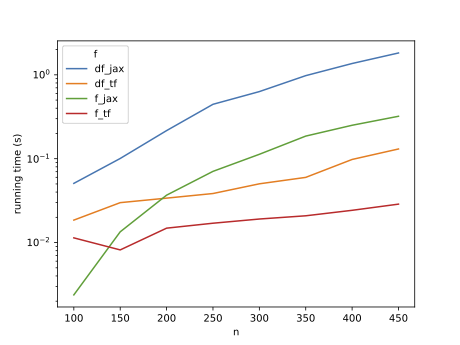
(Our actual use case, which is running the sum-product algorithm on a tree, does not have any such simplification, so we are stuck with in-place updates.)
Any ideas what could be going on? Thanks!
Issue Analytics
- State:

- Created a year ago
- Reactions:2
- Comments:18 (16 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
To narrow things down a bit. Here’s a simplified MWE, which clearly demonstrates O(n^2) asymptotics for an O(n) program. Every time the problem size doubles, the runtime increases by a factor of 4.
Moreover, it’s actually possible to induce this without even using
jax.grad. I’ve included a MWE for this case too. (Although this is a bit of a funny one, the program is naively O(n^2), it’s just that it can clearly be optimised to O(n). Maybe this one is unfair, or maybe it’s a MWE for the optimisation we’d like the backward pass of the first example to be doing?)So I’m pretty sure the problem is indeed a lack of copy elision. (c.f. also #9132)
Notably, this was on the CPU. When I try running on the GPU I get much muddier results – not clearly O(n) but not clearly O(n^2) either. I think this might be backend-dependent.
This is a really interesting use case, and I think it’s showing us a weakness in JAX (specifically
scan) that we must improve.If this turns out to be an AD+scan issue as I currently suspect, then I think the best option for the near future, if at all feasible, is not to use
scan, and for us to try to get the compilation times down in other ways. In the longer term we may need to generalize JAX’s loop constructs so that we can have non-sequential reads/writes in a loop body while maintaining sparse/efficient AD.To decide whether this is an AD+scan issue, i’m running the script with the scan fully unrolled. So far it certainly seems to ~solve~ mitigate the AD execution time issue: