
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Duplicate/combined word (lists) when using the response 'SpeechRecognitionResult' from longRunningRecognizeAsync
See original GitHub issueWhen looping trough the ‘SpeechRecognitionResult’ objects, I noticed that the transcript attribute and the ‘words_’ list do not match for (at least) the last result. In our app, we always use the first and only alternative. I noticed that the word lists do match the transcript from the first few results, but for the last result, all words including the last one will be returned in words. I would expect that the last result only contains the words which are related to that specific transcript.
I assume this is a bug. If not; please advice.
Environment details
- OS: Windows 10
- Java version: 1.8.0_102
- google-cloud-java version(s): google-cloud-speech-0.67.0-beta
Code snippet
In order to clarify this, I added a simplified code snippet below.
List<SpeechRecognitionResult> results = response.getResultsList();
for (SpeechRecognitionResult result : results) {
SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0);
String transcript = alternative.getTranscript();
for (WordInfo wordInfo : alternative.getWordsList()) {
String word = wordInfo.getWord();
}
}
In my current example, we have 3 results. The number of words are correct for the first two, but the third (last) is incorrect and includes all words from the whole text.
Result 0: Only the word Jaguar (both the transcript and the only word)
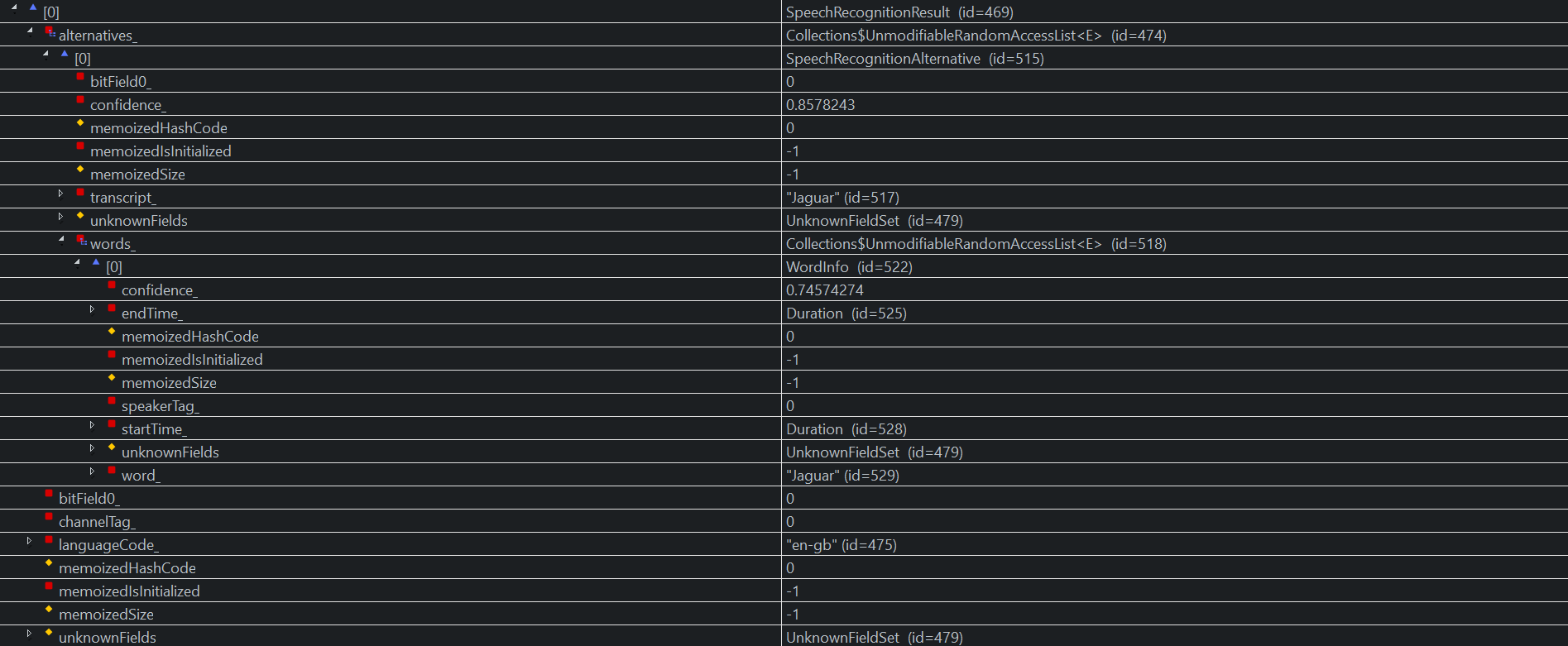
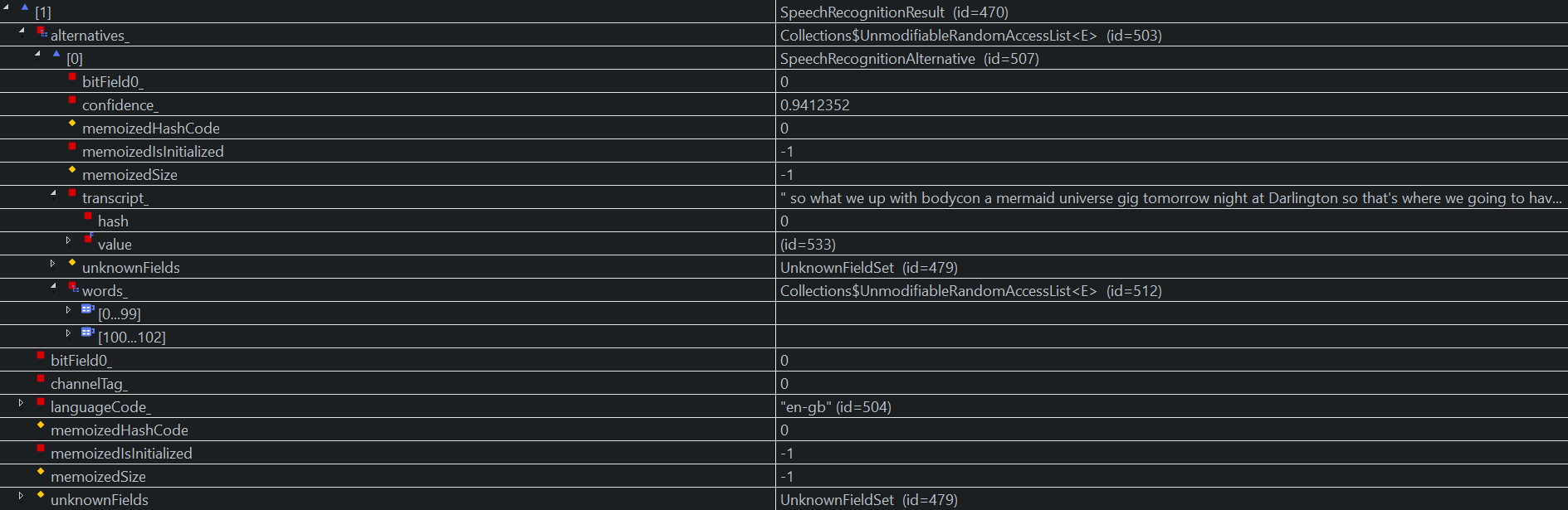
Result 1: A longer transcript, with 102 (correct) words in total
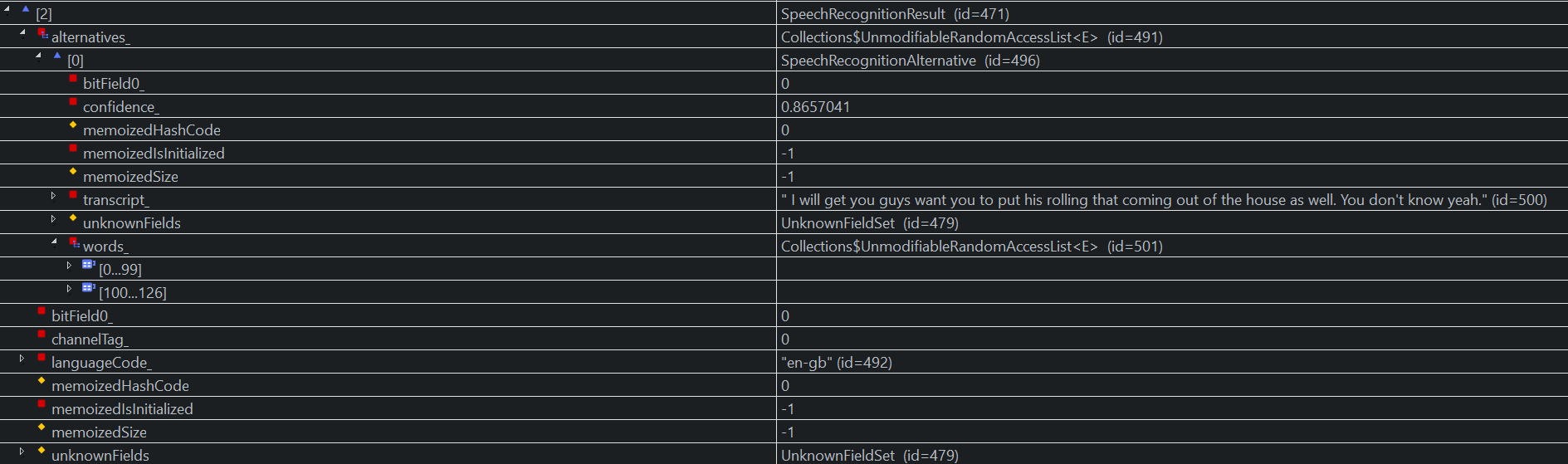
Result 2: A short transcript with only 23 words. As you can see, the list with words includes all 126 words (1+102+23).
Issue Analytics
- State:

- Created 5 years ago
- Comments:9 (6 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
I agree that the behavior is a little strange and unintuitive, I can start a discussion with the Speech team to see if it can be re-thought, or if there’s a workaround in place that I’m not aware of.
In the meantime, maybe a workaround could be to keep track of the word counts given in previous iterations, and on the last one get the relevant portion using List.subList()?
You may have tried this, but the code you provided in the original question could be replaced by something like this.
I’m wondering if it’s related to the fact that when EnableSpeakerDiarization is true, the words list is expected to contain all words from the beginning of the audio, even though the transcript does not.
Related documentation: https://github.com/googleapis/google-cloud-java/blob/master/google-api-grpc/proto-google-cloud-speech-v1p1beta1/src/main/java/com/google/cloud/speech/v1p1beta1/SpeechRecognitionAlternative.java#L187
If EnableSpeakerDiarization is set to true, can you set it to false and see if you experience the same problem?