
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Request for comments: Move checks/tests to a literate programming format
See original GitHub issueObserved behaviour
Currently the checkrunner allows us to create python files in the Lib/fontbakery/profiles directory with relatively little boilerplate for someone comfortable programming Python.
However, our checks are not always complete and correct the first time they are committed to the master branch and included in a release, and users find what is missing or what the problems are - but are not comfortable with Python code syntax, and are unable to read the source code.
To tell users more about what they checks are doing, we added docstrings to the source code. But then we realised we needed a little more structured data for users, such as defined rationales, and a dictionary of “misc metadata.”
Here’s an example; the first 38 lines of Lib/fontbakery/profiles/fvar.py:
from fontbakery.callable import check
from fontbakery.checkrunner import FAIL, PASS, WARN
# used to inform get_module_profile whether and how to create a profile
from fontbakery.fonts_profile import profile_factory # NOQA pylint: disable=unused-import
profile_imports = [
('.shared_conditions', ('is_variable_font'
, 'regular_wght_coord', 'regular_wdth_coord', 'regular_slnt_coord'
, 'regular_ital_coord', 'regular_opsz_coord', 'bold_wght_coord'))
]
@check(
id = 'com.google.fonts/check/varfont/regular_wdth_coord',
rationale = """
According to the Open-Type spec's registered
design-variation tag 'wdth' available at
https://docs.microsoft.com/en-gb/typography/opentype/spec/dvaraxistag_wdth
If a variable font has a 'wdth' (Width) axis, then the coordinate
of its 'Regular' instance is required to be 100.
""",
conditions = ['is_variable_font',
'regular_wdth_coord'],
misc_metadata = {
'request': 'https://github.com/googlefonts/fontbakery/issues/1707'
}
)
def com_google_fonts_check_varfont_regular_wdth_coord(ttFont, regular_wdth_coord):
"""The variable font 'wdth' (Width) axis coordinate must be 100 on the
'Regular' instance."""
if regular_wdth_coord == 100:
yield PASS, "Regular:wdth is 100."
else:
yield FAIL, ("The 'wdth' coordinate of"
" the 'Regular' instance must be 100."
" Got {} as a default value instead."
"").format(regular_wdth_coord)
And this is paired with the code test in tests/profiles/fvar_test.py:
def test_check_varfont_regular_wdth_coord():
""" The variable font 'wdth' (Width) axis coordinate
must be 100 on the 'Regular' instance. """
from fontbakery.profiles.fvar import com_google_fonts_check_varfont_regular_wdth_coord as check
from fontbakery.profiles.shared_conditions import regular_wdth_coord
# Our reference varfont, CabinVFBeta.ttf, has
# a good Regular:wdth coordinate
ttFont = TTFont("data/test/cabinvfbeta/CabinVFBeta.ttf")
regular_width_coord = regular_wdth_coord(ttFont)
# So it must PASS the test
print('Test PASS with a good Regular:wdth coordinate...')
status, message = list(check(ttFont, regular_width_coord))[-1]
assert status == PASS
# We then change the value so it must FAIL:
ttFont["fvar"].instances[0].coordinates["wdth"] = 0
# Then re-read the coord:
regular_width_coord = regular_wdth_coord(ttFont)
# and now this should FAIL the test:
print('Test FAIL with a bad Regular:wdth coordinate (100)...')
status, message = list(check(ttFont, regular_width_coord))[-1]
assert status == FAIL
Overall, this is really just as impenetrable as uncommented Python code for our users; and its worse for people fluent in Python because it adds a lot of boilerplate.
Also having the check and the test in separate places isn’t ideal, I think.
Expected behaviour
I would like to suggest radically changing the format of our check files; ideally this is a “non functional” change, that doesn’t effect the command line or web UIs; it is more a community process improvement sort of thing. And it is something that can be done incrementally.
The ‘big idea’ is to invert the priority of code and docs, so that the documentation really a “first class citizen”, and the check code is relegated to a second class - but that is more compact, without any ‘human knowledge’ mixed in with Python code.
This will be better for users because the Python code will become more minimal - while code comments will be retained in code, the long explanatory strings will move to a human friendly document above the code, and the python boilerplate code will almost entirely be eliminated.
Therefore I propose creating a new repo called something like “The FontBakery Knowledge Project” which is a repo that only contains markdown files with check code; and then this fontbakery repo becomes focused on the check runner itself, which parses those files according to the Ruby on Rails maxim of “implicit is better than explicit” and “convention is better than configuation” 😃
This is of course an old idea, so called Literate Programming; and the current trend for literate programming in Python is the Jupyter Notebook (.ipynb) file format. This contains a mix of markdown and python “cells” in a JSON format structure, and there are various UIs and runtimes where users can run them sequentially or all at once.
However, for our purposes, a markdown file using the Github Markdown style code formatting means we don’t need to use a Notebook viewer app, we simply have clean markdown files in the git repo.
As first step, @felipesanches and I mocked up what the above check would become like in this case; a file with the path com.google.fonts/check/varfont/regular_wdth_coord.md - which implies the check ID - and then this contents (source here):
------- 8< --------
Is the ‘wdth’ axis Regular at 100?
If a variable font has a ‘wdth’ (Width) axis, then the coordinate of its ‘Regular’ instance is required to be 100, according to the OpenType specification’s “registered axis” definition of wdth, available at https://docs.microsoft.com/en-gb/typography/opentype/spec/dvaraxistag_wdth
Conditions
Run this when the font…
- is a variable font
- has a wdth axis
Pass Message
Regular:wdth is 100.
Fail Reason
The ‘wdth’ coordinate of the ‘Regular’ instance must be 100, but instead the default value is {regular_wdth_coord}.
Related Information
Where was this requested?
https://github.com/googlefonts/fontbakery/issues/1707
Fonts that will pass this check
cabinvfbeta/Cabin-VF.ttf
Fonts that will fail this check
cabinvfbeta/Cabin-VF-bad-wdth.ttf
Check the fonts
if regular_wdth_coord == 100:
yield PASS, pass_message
else:
yield FAIL, fail_message["reason"]
Test the check
Our reference varfont has a good Regular wdth coordinate, so it should PASS the test:
regular_width_coord = regular_wdth_coord(ttFont)
print('Test PASS with a good Regular:wdth coordinate...')
status, message = list(check(ttFont, regular_width_coord))[-1]
assert status == PASS
We then change the value so it must FAIL:
ttFont["fvar"].instances[0].coordinates["wdth"] = 0
Then re-read the coord:
regular_width_coord = regular_wdth_coord(ttFont)
and now this should FAIL the test:
print('Test FAIL with a bad Regular:wdth coordinate (100)...')
status, message = list(check(ttFont, regular_width_coord))[-1]
assert status == FAIL
------- 8< --------
Which on Github renders nicely, of course; and on Jupyter too:
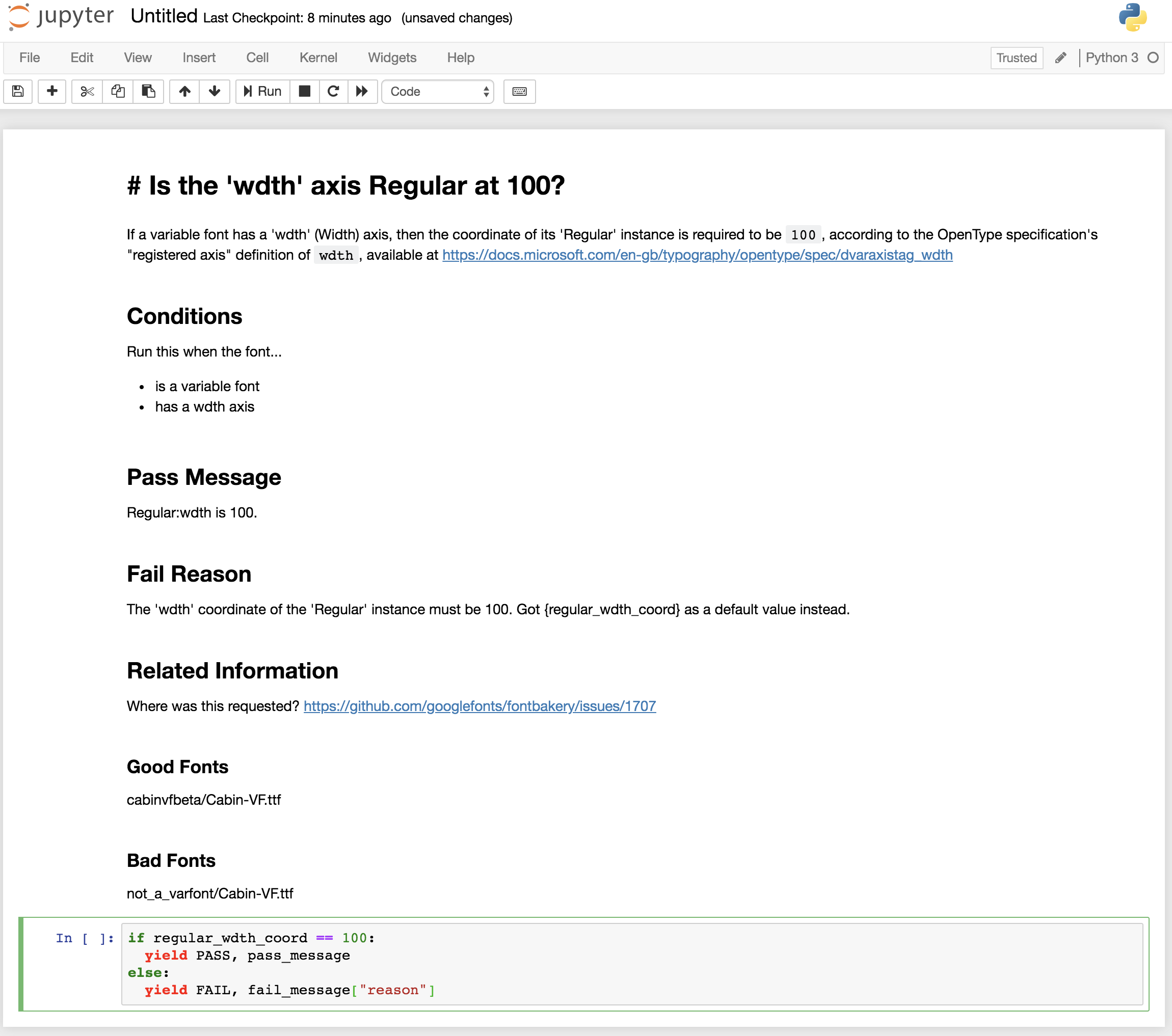
Going line by line…
An H1 and should be possible to use as a docstring - for example, the command fontbakery -L lists all checkIDs available, just as their IDs, line by line, and this is used for the bash autocompletion; while fontbakery -L --verbose list all checkIDs followed by their docstrings - which ideally fit on 1 line.
Under that is the “rationale” text; here I rewrote it to be a little more fluent than the current check rationale string, and adding some markdown formatting.
An H2 that is an “expected” string, Conditions, which is implicit structure in the document
Under that is some helpful but non-functional text Run this when the font... that can be omitted.
The list items (ordered or unordered) are expected strings though; they should be values that exact regex match to keys that are the conditional strings in the codebase today.
Next is a H2 followed by the first pass state; if there are several pass states, these should be either Markdown paragraphs, or list items.
This is followed similarly by fail states. Note here that there is one reason that uses a Python formatted string named value; this could be a positional value ({}) too
Next is the “misc metadata” and some more ‘expected’ titles; I split out the test font file paths to their own section (and added a FAIL font) so that a non-Python fluent designer can write a document like this without having to provide the check code, or if they do, they don’t have to provide the test code, but they can provide a pair of fonts and we can take care of it.
The test for this check was already with very verbose code comment which made it already very close to a ‘literate programming’ style already.
Finally, the new check file format will itself need a checker, and code tests for that checker, to remind us to include optional but helpful texts, and check that the expected section titles or conditional strings are correct 😉
Issue Analytics
- State:

- Created 4 years ago
- Comments:13 (10 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
I believe that the best approach would be to add support in the current fontbakery engine to parse and execute this new markdown check format, but still support the existing approach. This would enable us to gradually migrate to the new style while ensuring correctness and not changing the user interfaces.
I’ve been thinking, and I am not so sure we should keep the markdown files in a separate repo. I think I would continue development on a single repo for a while until some more compelling reason surfaced to have a repo split.