
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Performance Discrepancy
See original GitHub issueIn the docs, Tin processing time scales linearly and processes in the order of one million points per second:
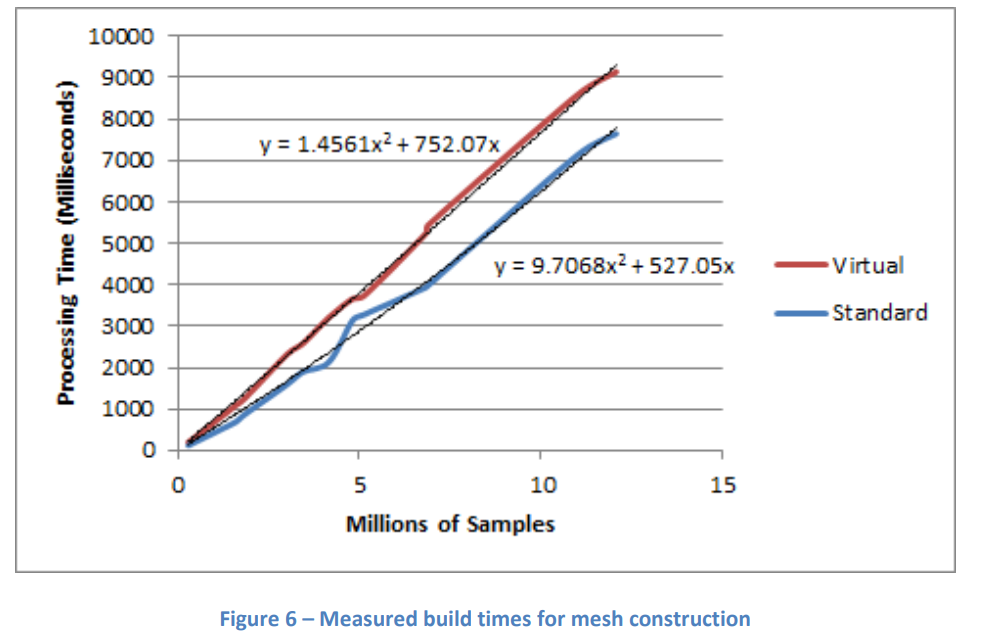
Yet, the following code takes ~125s, and playing around with different values for N, performance is very much non-linear.
int N = 1_000_000;
List<Vertex> vertices = new ArrayList<>();
for (int i = 0; i < N; i++) {
double x = Math.random() * 1000;
double y = Math.random() * 1000;
vertices.add(new Vertex(x, y, 0));
}
long tStart = 0;
IIncrementalTin tin = new IncrementalTin();
tStart = System.nanoTime();
tin.add(vertices, null);
long tTinfour = System.nanoTime() - tStart;
10,000 points: ~65ms 100,000 points: ~2.7s 200,000 points: ~9.4s
What’s going on?
Issue Analytics
- State:

- Created a year ago
- Comments:6 (6 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Analyzing Performance Discrepancies : Journal for Nurses in ...
The next series of questions are directed at uncovering possible explanations for a performance discrepancy that is not a knowledge deficit or skill...
Read more >Analyzing performance discrepancies with line managers
performance discrepancy is class- room training. The costs, which include instructor salaries, student salaries, travel expenses, course.
Read more >Performance discrepancy logic. - APA PsycNet
Presents a 7-step behavior modification procedure that can be used in the management of performance discrepancy (PD). The steps are: describe the PD, ......
Read more >Discrepancy Model: What You Need to Know - Understood.org
At a glance. The discrepancy model is what some schools use to determine if kids are eligible for special education services. The term...
Read more >The management implications of performance discrepancy in ...
Performance discrepancy (PD) is capable of adversely affecting the goals of a library organization. Discusses managerial implications and effects of PD.
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
Michael,
I think that you are right that I have to make the recommendation for using the Hilbert sort much more prominent. It’s hard for me to look at this stuff with a fresh perspective, so I was hoping you might have a suggestion. Is there a place in the documentation that I could include the discussion so that it would have the highest probability of a new user finding it?
Also, I did a test where I processed a random number of samples between 1000 and 1 million with samples at random coordinates. It turns out that the best fit for the time-complexity curve for the non-sorted sample set was of O(N^2). The Hilbert sort reduces that to basically O(N) with a small quadratic component.
Non-sorted:
But, sorted, with a much smaller processing time: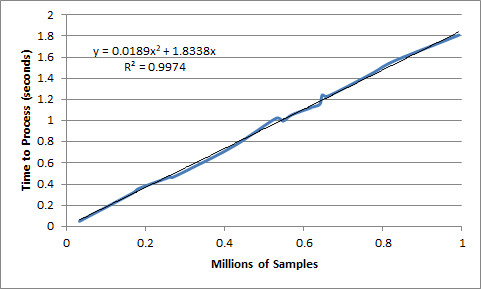
I’ve attached a zip file showing the test program. The other thing I would probably try is to include the time-to-sort as part of the processing-time tabulation. Properly speaking, it does contribute to the overall processing time.
TimeComplexity.zip
Incidentally, I was looking through my Tinfour test project in Netbeans to pick a good place to store your test program, and I realized I have a package called test.micycle1. I think that’s a good tribute. Thanks for sending me so many interesting questions over the last few years.
Gary