
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Very slow select queries (Ignoring Indexing?)
See original GitHub issueI have a table with 1M rows that has the following index:
psql -U user -d db -c “SELECT * FROM pg_indexes WHERE tablename = ‘messages’;”
schemaname | tablename | indexname | tablespace | indexdef
------------+-------------+---------------------------+------------+---------------------------------------------------------------------------------------------
public | messages| updates_timestamp_idx | | CREATE INDEX updates_timestamp_idx ON public.updates USING btree (“timestamp” DESC)
When I do a select query for the first 10 entries in desc order on the timestamp key on PSQL it runs in 0.039s while hasura takes 4.735s.
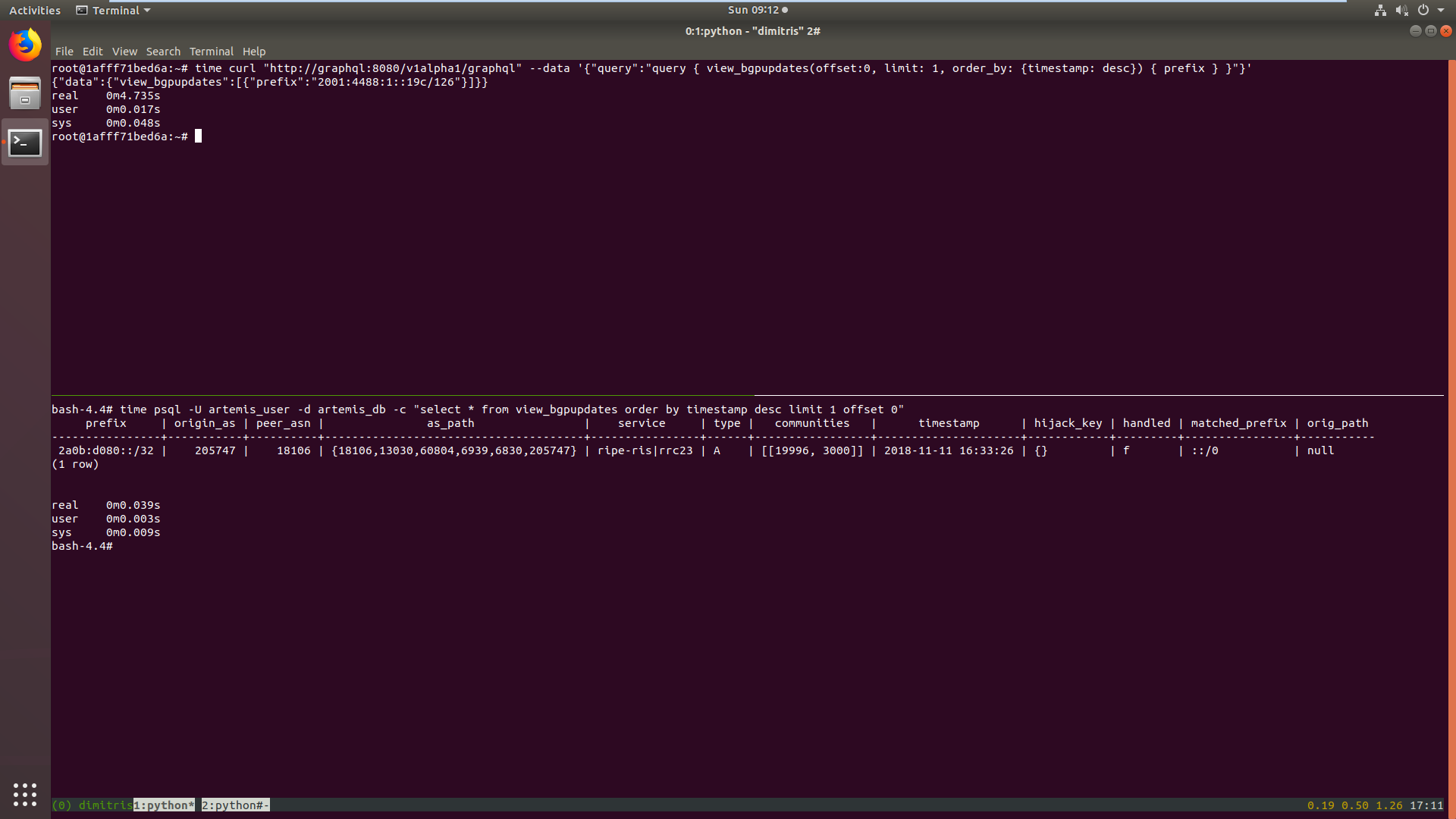
This difference is orders of magnitude bigger. Any idea what’s the reason?
P.S. It returns a different result as well. Maybe it doesn’t use the indexes at all?
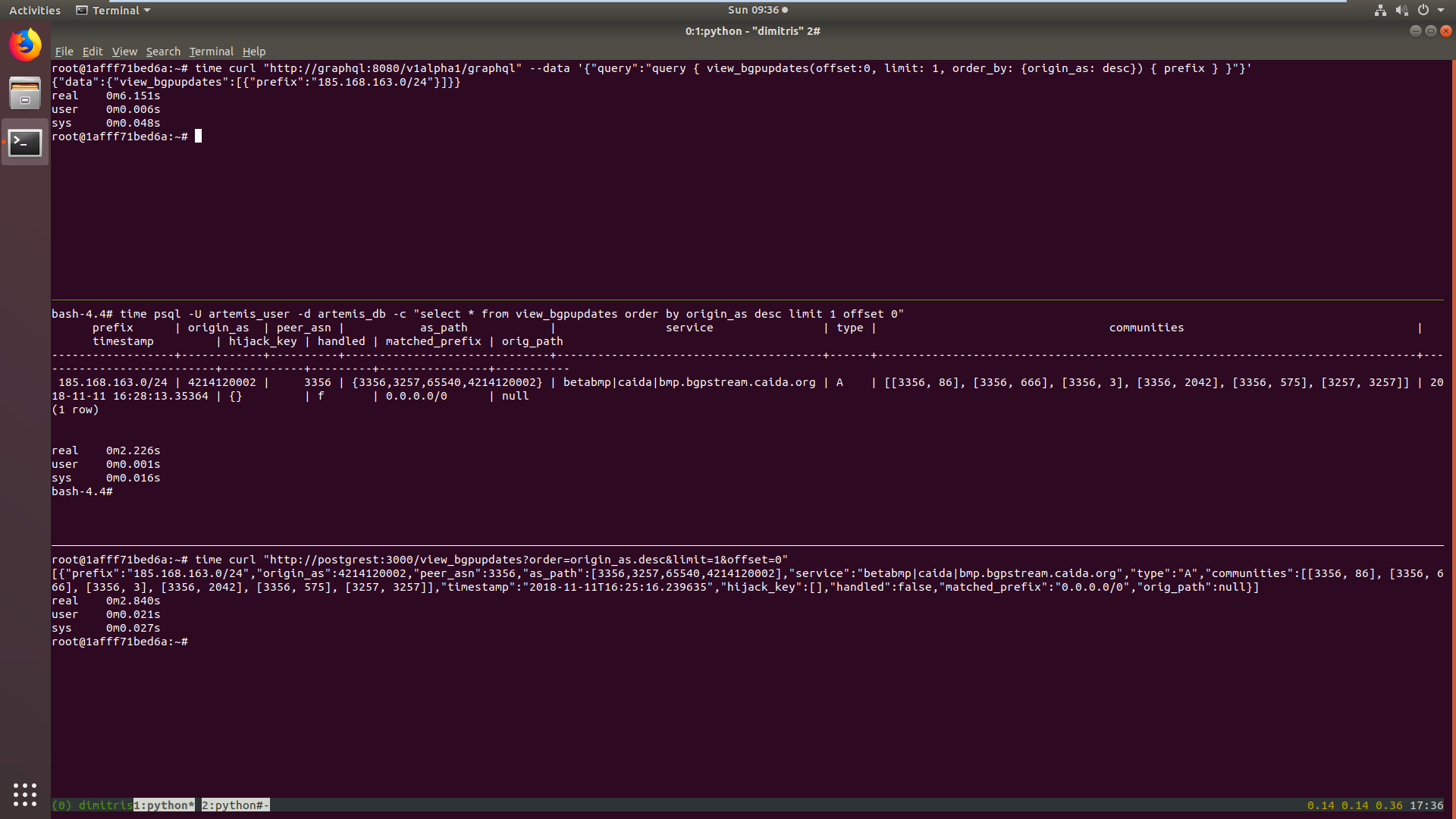
Also, example times from a query on a non indexed column from 1. hasura, 2. psql, 3. postgrest
Issue Analytics
- State:

- Created 5 years ago
- Comments:11 (10 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
MySQL difficulty with optimizing slow query with index but ...
"To me this tells me that the index 'scraper_index' is so inefficient that it's nearly as slow as not having a index at...
Read more >Query with Indexes slower than without Indexes - Stack Overflow
Another issue... A common problem is running timings is 'caching' which makes the same query take less time the second time you run...
Read more >Ignored Indexes | MariaDB
In this blog, we use IGNORED indexes, a new feature in MariaDB Server 10.6, ... And, slow queries are a frequent cause of...
Read more >Improve performance: database indexes and slow queries
When the slowness is on the database server it is usually slow due to non optimal queries which take most of the transaction...
Read more >Chapter 4. Query Performance Optimization - O'Reilly
Use a covering index (“Using index” in the Extra column) to avoid row accesses, and filter out nonmatching rows after retrieving each result...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
Please consider adding a section in the docs about optimizations like this so that this kind of info does not remain “out of sight” in the issues.
upon logging the generated queries I found out that the root of the evil was the
NULLS LASTstatement that is added in the query. So as suggested in #657 I used theNULLS FIRSTapproach and the query is working as expected.Is there a reason that the default is
NULLS LASTand this cause the indexes to not be used? Maybe make the_ascand_descto generate the correct query in order to use the indexes (like NULLS LAST for _asc and NULLS FIRST for _desc, or an enum for no NULLS handling at all)?