
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[Question] Stacked-LSTM worse than Single LSTM (PPO2)
See original GitHub issueDescribe the Question Hello, I constructed Stacked-LSTM in CustomPolicy module and here’s the point that Stacked-LSTM may perform better than Single LSTM reasonably but we got the exactly opposite result (Stacked-LSTM worse than Single LSTM) in our experiment with many times. The following were the details:
-
Params Params num_env: 1 nminibatches: 1 lr: 2.5e-4 num_timesteps: 1000000 RL ALGORITHMS : PPO2
-
Single LSTM(parameter_list) ‘model/pi_fc0/w:0’ shape=(8, 64) ‘model/pi_fc0/b:0’ shape=(64,) ‘model/pi_fc1/w:0’ shape=(64, 64) ‘model/pi_fc1/b:0’ shape=(64,) ‘model/rnn1/wx:0’ shape=(64, 1024) ‘model/rnn1/wh:0’ shape=(256, 1024) ‘model/rnn1/b:0’ shape=(1024,) ‘model/vf/w:0’ shape=(256, 1) ‘model/vf/b:0’ shape=(1,) ‘model/pi/w:0’ shape=(256, 4) ‘model/pi/b:0’ shape=(4,) ‘model/q/w:0’ shape=(256, 4) ‘model/q/b:0’ shape=(4,)
-
Stacked LSTM(parameter_list) ‘model/pi_fc0/w:0’ shape=(8, 64) ‘model/pi_fc0/b:0’ shape=(64,) ‘model/pi_fc1/w:0’ shape=(64, 64) ‘model/pi_fc1/b:0’ shape=(64,) ‘model/rnn1/wx:0’ shape=(64, 1024) ‘model/rnn1/wh:0’ shape=(256, 1024) ‘model/rnn1/b:0’ shape=(1024,) ‘model/rnn2/wx:0’ shape=(256, 1024) ‘model/rnn2/wh:0’ shape=(256, 1024) ‘model/rnn2/b:0’ shape=(1024,) ‘model/vf/w:0’ shape=(256, 1) ‘model/vf/b:0’ shape=(1,) ‘model/pi/w:0’ shape=(256, 4) ‘model/pi/b:0’ shape=(4,) ‘model/q/w:0’ shape=(256, 4) ‘model/q/b:0’ shape=(4,)
-
Stacked-LSTM vs Single LSTM(Benchmark on LunarLander-v2)
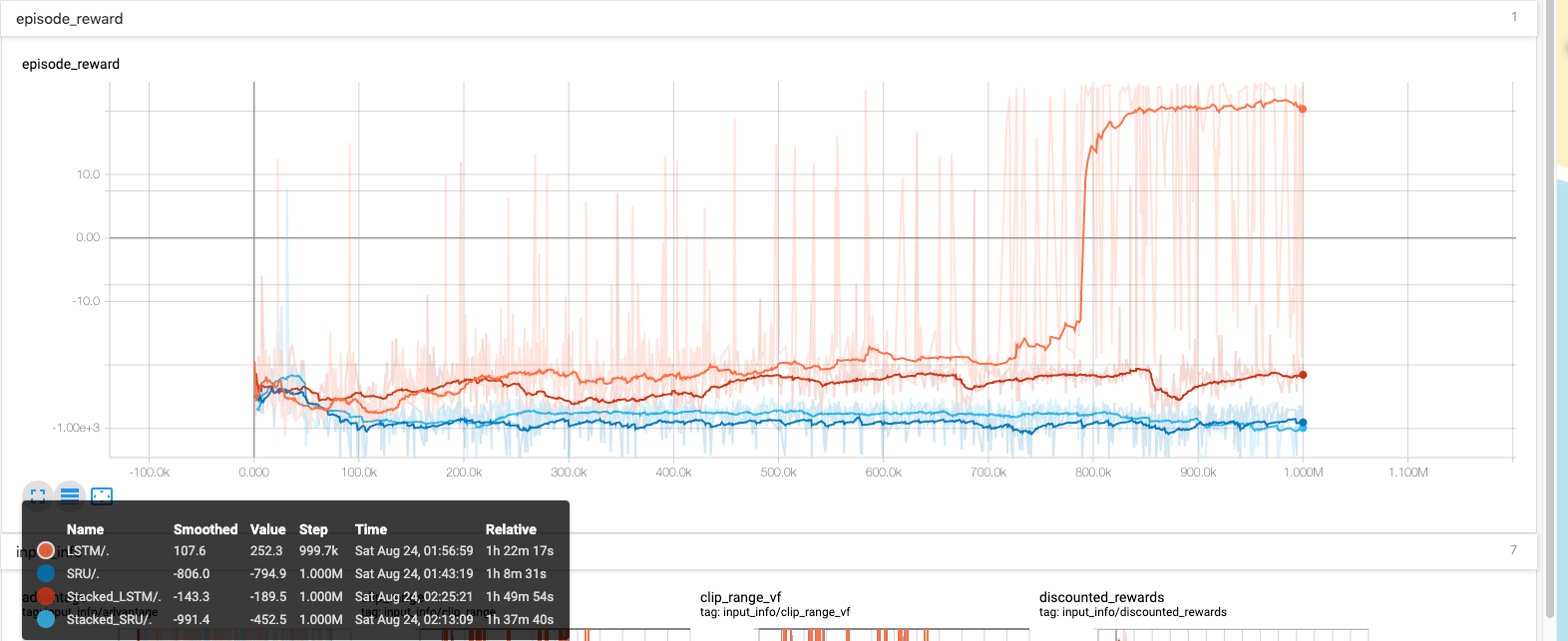
-
Stacked-LSTM
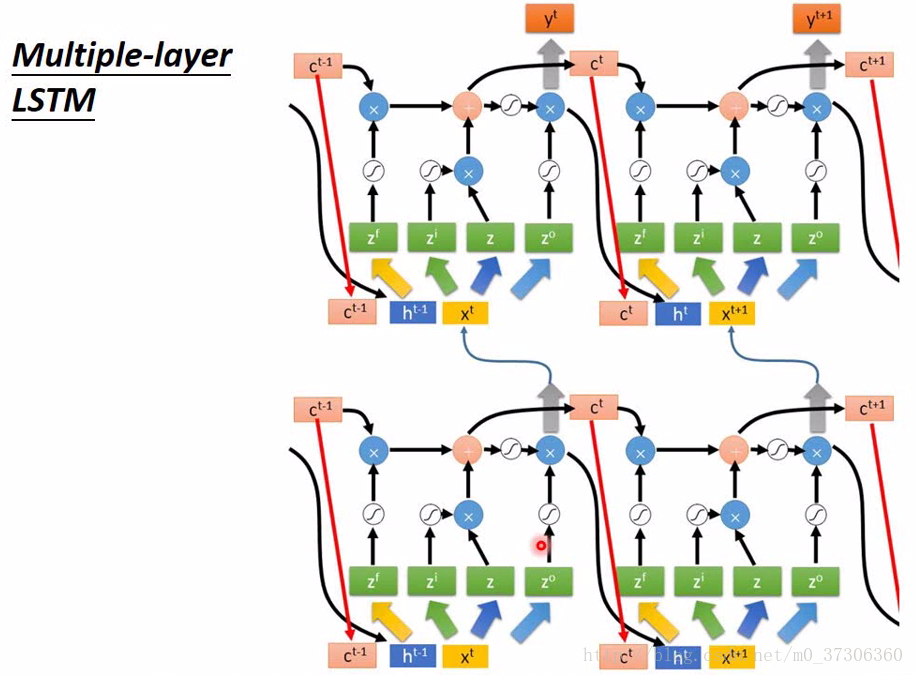
Code example
class CustomRNNPolicy(RecurrentActorCriticPolicy):
recurrent = True
def __init__(self, sess, ob_space, ac_space, n_env, n_steps, n_batch, n_lstm=256, reuse=False, layers=None,
net_arch=None, act_fun=tf.tanh, cnn_extractor=nature_cnn, layer_norm=False, feature_extraction="mlp",**kwargs):
super(CustomRNNPolicy, self).__init__(sess, ob_space, ac_space, n_env, n_steps, n_batch,
state_shape=(2 * n_lstm, ), reuse=reuse,
scale=(feature_extraction == "cnn"))
self._kwargs_check(feature_extraction, kwargs)
if net_arch is None: # Legacy mode
if layers is None:
layers = [64, 64]
else:
warnings.warn("The layers parameter is deprecated. Use the net_arch parameter instead.")
with tf.variable_scope("model", reuse=reuse):
if feature_extraction == "cnn":
extracted_features = cnn_extractor(self.processed_obs, **kwargs)
else:
extracted_features = tf.layers.flatten(self.processed_obs)
for i, layer_size in enumerate(layers):
extracted_features = act_fun(linear(extracted_features, 'pi_fc' + str(i), n_hidden=layer_size,
init_scale=np.sqrt(2)))
input_sequence = batch_to_seq(extracted_features, self.n_env, n_steps)
masks = batch_to_seq(self.dones_ph, self.n_env, n_steps)
if name == 'SRU':
rnn_output, self.snew = sru_opt(input_sequence, masks ,self.states_ph , 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
elif name == 'Stacked_SRU':
rnn_out, _ = sru_opt(input_sequence, masks, self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = sru_opt(rnn_out, masks, self.states_ph, 'rnn2', n_hidden=n_lstm, layer_norm=layer_norm)
elif name == 'LSTM':
rnn_output, self.snew = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
elif name == 'Stacked_LSTM':
rnn_out, _ = lstm(input_sequence, masks ,self.states_ph, 'rnn1', n_hidden=n_lstm,layer_norm=layer_norm)
rnn_output, self.snew = lstm(rnn_out, masks ,self.states_ph, 'rnn2', n_hidden=n_lstm,layer_norm=layer_norm)
else:
pass
rnn_output = seq_to_batch(rnn_output)
value_fn = linear(rnn_output, 'vf', 1)
self._proba_distribution, self._policy, self.q_value = \
self.pdtype.proba_distribution_from_latent(rnn_output, rnn_output)
self._value_fn = value_fn
else: # Use the new net_arch parameter
......
self._setup_init()
def step(self, obs, state=None, mask=None, deterministic=False):
if deterministic:
return self.sess.run([self.deterministic_action, self.value_flat, self.snew, self.neglogp],
{self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
else:
return self.sess.run([self.action, self.value_flat, self.snew, self.neglogp],
{self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
def proba_step(self, obs, state=None, mask=None):
return self.sess.run(self.policy_proba, {self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
def value(self, obs, state=None, mask=None):
return self.sess.run(self.value_flat, {self.obs_ph: obs, self.states_ph: state, self.dones_ph: mask})
name = 'Stacked_LSTM'
env = DummyVecEnv([lambda: gym.make('LunarLander-v2')])
model = PPO2(CustomRNNPolicy, env, verbose=1, tensorboard_log='./tensorboard/', nminibatches=1)
model.learn(1e6)
System Info Describe the characteristic of your environment:
- Describe how the library was installed (pip, docker, source, …)
- Python version : 3.5.6
- Tensorflow version : 1.12.0
- stable-baselines : 2.7.0
Looking forward to your kindly reply , thank you. @araffin @hill-a Sincerely , RonaldJEN
Issue Analytics
- State:

- Created 4 years ago
- Comments:11
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
I am sorry to say neither are correct: In 1) you are mixing hidden states together, and in 2) you are not updating the hidden state (which is essential part of recurrent networks, as this carries the information between activations). Try backtracking what the
self.states_phcontains (e.g. check thestepfunction and what is fed in there etc.)The solution requires tracking two completely separate states. However the underlying code only supports one variable (the
stateinstepfunction). You’d have to figure out including both LSTM states in this variable, and then separating them into separate states for two LSTM layers.Do note that even higher end papers with large RL models (e.g. Deepmind IMPALA) do not use more than one LSTM layer. Deepmind CTF paper has multiple layers of LSTM but with more complicated model (different LSTM layers run at different rates).
@iza88
No, that’s just one LSTM layer (at location “lstm”).