
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Model Parallelism for Bert Models
See original GitHub issueHi,
I’m trying to implement Model parallelism for BERT models by splitting and assigning layers across GPUs. I took DeBERTa as an example for this. For DeBERTa, I’m able to split entire model into ‘embedding’, ‘encoder’, ‘pooler’, ‘classifier’ and ‘dropout’ layers as shown in below pic.
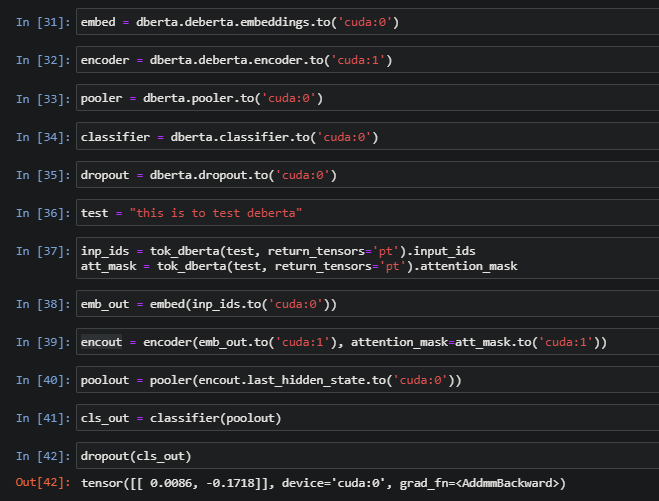
With this approach, I trained on IMDB classification task by assigning ‘encoder’ to second GPU and others to first ‘GPU’. At the end of the training, second GPU consumed lot of memory when compared to first GPU and this resulted in 20-80 split of the entire model.
So, I tried splitting encoder layers also as shown below but getting this error - “TypeError: forward() takes 1 positional argument but 2 were given”
embed = dberta.deberta.embeddings.to('cuda:0')
f6e = dberta.deberta.encoder.layer[:6].to('cuda:0')
l6e = dberta.deberta.encoder.layer[6:].to('cuda:1')
pooler = dberta.pooler.to('cuda:0')
classifier = dberta.classifier.to('cuda:0')
dropout = dberta.dropout.to('cuda:0')
test = "this is to test deberta"
inp_ids = tok_dberta(test, return_tensors='pt').input_ids
att_mask = tok_dberta(test, return_tensors='pt').attention_mask
emb_out = embed(inp_ids.to('cuda:0'))
first_6_enc_lay_out = f6e(emb_out)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-379d948e5ba5> in <module>
----> 1 first_6_enc_lay_out = f6e(emb_out)
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
TypeError: forward() takes 1 positional argument but 2 were given
Plz suggest how to proceed further…
Issue Analytics
- State:

- Created 3 years ago
- Comments:22 (10 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Yay, so glad to hear you found a solution, @saichandrapandraju!
Thank you for updating the notebook too!
If the issue has been fully resolved for you please don’t hesitate to close this Issue.
If some new problem occurs, please open a new dedicated issue. Thank you.
Tested DeepSpeed on multi-GPU as well and it worked !!
By setting
NCCL_SOCKET_IFNAME=lo, everything worked as expected.Thanks a lot @stas00