
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
overview at the end of `dvc repro` and the deterministic feature
See original GitHub issueHey, we talked about this feature in our telephone conference at wednesday.
Initial situation: I build a pipeline (+execute it) and share only the git repository to others. This git repository contains all the code and dvc files needed to reproduce the entire pipeline. Additional there are also the metric files and the hash sums in the dvc files. The user who can only see my git can’t see the dvc repo. So all cache files for him are missing!
What I want: I want guarantee the user, that just clone my git repository, that my resulst comes from the same pipeline!
First Feature Request: overview at the end of dvc repro
The user cloning my git repository is now running dvc repro -P, and the user sees the following table at the end of the pipeline as output.
The difference to dvc status:
- Some steps need to be reproduced for the user because he has missing output files that are cached by dvc.
- If he reproduces the pipeline with
dvc repro -P, the hashes are overwritten, so he has no chance of seeing that this are the same results or not. (This could manage the third column in the table.)
| Stages | Reproduced | Changed | Info |
|---|---|---|---|
| pull_data.dvc | yes | no | - |
| preprocess_data.dvc | yes | no | - |
| visualize.dvc | yes | no | - |
| train_model.dvc | yes | yes | models/model1.npy, tensorboards/tensorboard1, … |
| test_model.dvc | yes | yes | metrics/metric1, summary.rd, … |
| visualization1.dvc | yes | yes | img3.png |
| visualization2.dvc | yes | no | - |
| visualization3.dvc | yes | yes | img1.png |
The problem with the first feature request: Many ML scripts cannot (or will not) be written to achieve exactly the same results every time. You can see how hard this can be here.. This is why I want to ask for a second Feature:
Second Feature Request: the deterministic feature
I would like to have a determenistic flag in all DVC files that can be used for any DVC stages and/or other dependencies and describes whether this is deterministic or not. For example:
If I have the following Pipeline:
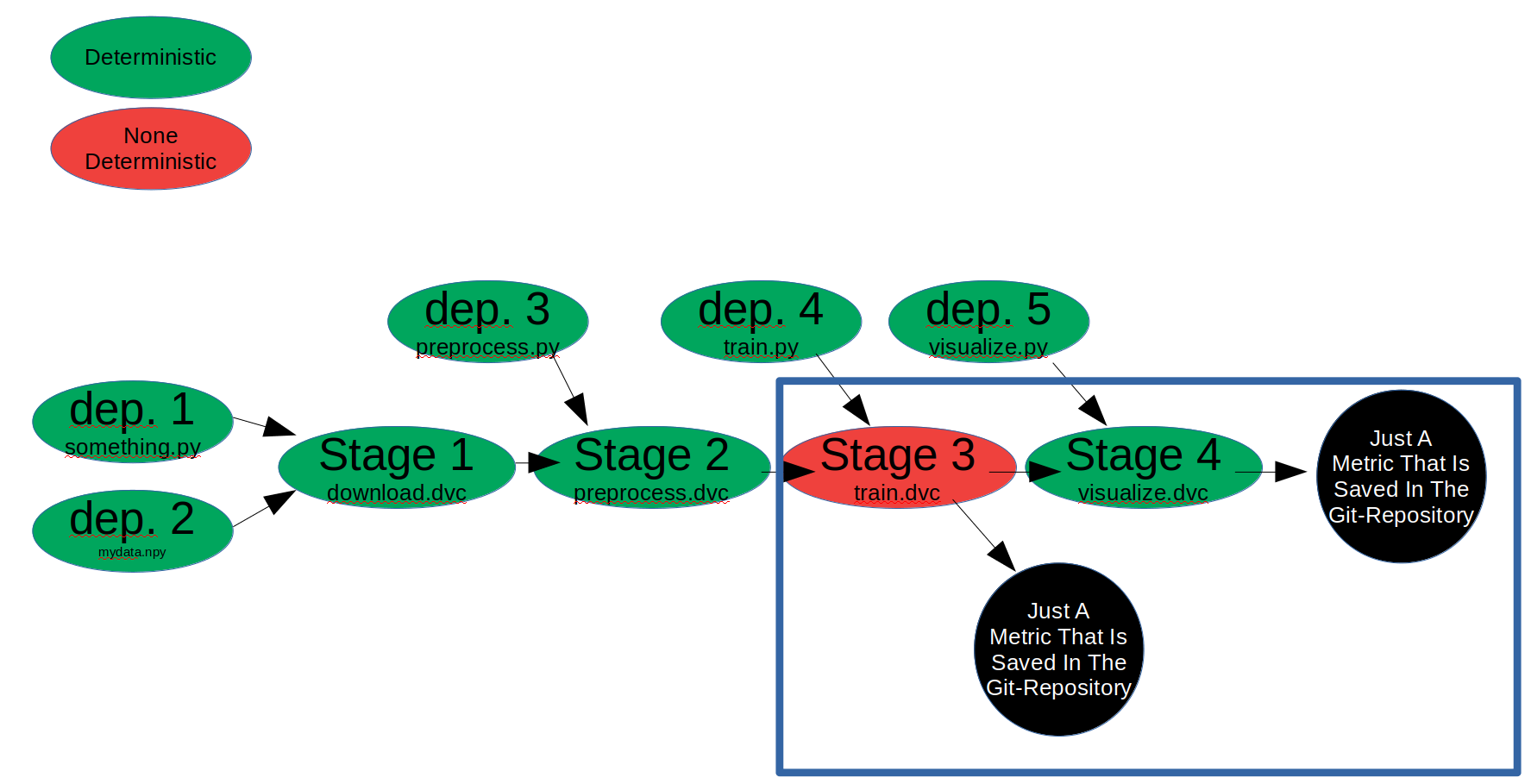
I want that all files that are none deterministic or depend on a non-deterministic stage or dependencies get a second checksum. So all in the blue square. If this feature is interest, than we would need to talk about how the second checksum could be calculated. One example could be:
(first) checksum of all deterministic stages + own (first) checksum ====== a function ======> the second checksum for this non-deterministic stages and output files.
dvc check deterministic
Output:
Dependencies and stages that are deterministic:
- dep. 1
- dep. 2
- dep. 3
- dep. 4
- dep. 5
- Stage 1
- Stage 2
- Stage 5
Dependencies and stages that are none deterministic:
- Stage 3
- metric 1
- metric 2
Dependencies and stages that are deterministic but depend on a none deterministic stage:
- Stage 4
Check output-files by the given deterministic stages:
- metric 1: is valid
- metric 2: is valid
Why could I want this feature? A user who clones my git repository can now see without reproducing the entire pipeline whether the metric file he can see really comes from that pipeline or not. So it’s a little protection against fraud for the user. You can still cheat, but it would make it a lot harder.
Issue Analytics
- State:

- Created 4 years ago
- Reactions:1
- Comments:11 (5 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Hi @efiop, it needed a lot of time but now I created an example 😃 And I think you are right. You need already really bad habits to manipulate the pipeline.
But here is the example:
Lets maybe use some specific example.
Use case - non deterministic training : for example CNN trained on GPU.
dvc checkout