
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Unexpected gpu-id behaviours
See original GitHub issueIssue description
Full disclosure: I discovered these while reviewing a PR for AxonDeepSeg (PR# 701), so I’ve only tested it with the settings/API that @mariehbourget used to implement that functionality there
Current behavior
When selecting a gpu-id other than 0 (eg. 5), memory is allocated to gpu-id 0 regardless, and it does so both prior and during the use of the given gpu-id (eg. 5).
Also, if CUDA_VISIBLE_DEVICES is set for the session to something other than starting from 0 (eg CUDA_VISIBLE_DEVICES=3,4,5, then gpu-id does not set the device number that is set, but is in fact the ID relative to the visible devices (eg for CUDA_VISIBLE_DEVICES=3,4,5, a gpu-id of 1 (remember that in python, count starts at 0), the gpu device that would be set would be the gpu-id 4, and not 1.
Expected behavior
Only the selected gpu-id should have memory used.
gpu-id documentation should also reflect how it behaves with CUDA_VISIBLE_DEVICES values set.
Steps to reproduce
While testing our PR, I would set the gpu-id to 5 through the ADS/IVADOMED API, but noticed while monitoring the the nvidia-smi that the GPU ID would get some memory allocated in addition, and it would start before the memory started being used in the ID I set to 5.

Command: axondeepseg -t SEM -i AxonDeepSeg/models/model_seg_rat_axon-myelin_sem/data_test/image.png --gpu-id 5
Looking online, some commentators say that it’s because when pytorch “turns on”, it automatically initializes the CUDA device using device 0 (but more on that later): https://github.com/pytorch/pytorch/issues/2383#issuecomment-323112926
People in another suggested using CUDA_VISIBLE_DEVICES so that the device 0 isn’t used.
Trying this, I discovered the second behaviour bug.
Command: CUDA_VISIBLE_DEVICES=5,6 axondeepseg -t SEM -i AxonDeepSeg/models/model_seg_rat_axon-myelin_sem/data_test/image.png --gpu-id 5
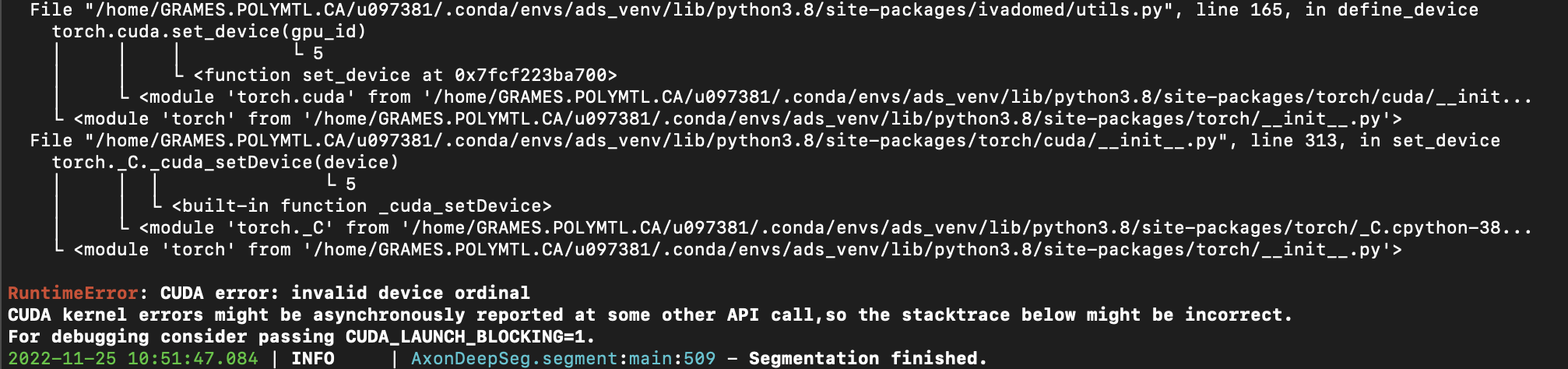
The code now errors.
This is because the gpu-id (as now implemented in IVADOMED) is in fact not the ID of the GPU, but instead the ID relative to the visible devices: https://discuss.pytorch.org/t/runtimeerror-cuda-error-invalid-device-ordinal/67488
So changing it to
Command: CUDA_VISIBLE_DEVICES=5,6 axondeepseg -t SEM -i AxonDeepSeg/models/model_seg_rat_axon-myelin_sem/data_test/image.png --gpu-id 0
Now works:

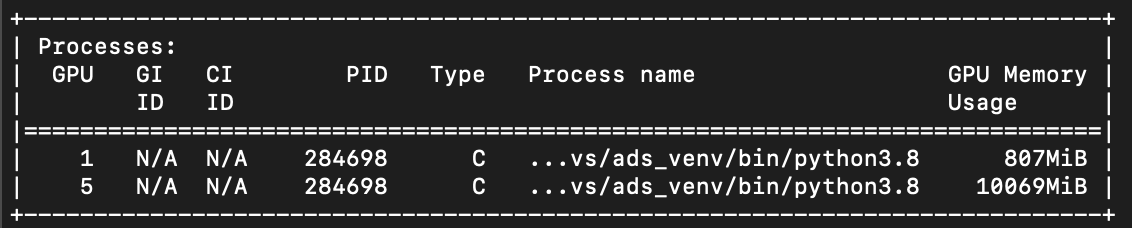
However, note that if the list visible devices don’t begin with the device I want to use, then the first visible device will still have some memory used from the point earlier on, it’s not always device 0 that has memory taken to boot up pytorch (and to this point, I don’t know where and if this can be stopped/changed), but it’s the first in the list of available devices that this will occur for, for example:
Command: CUDA_VISIBLE_DEVICES=1,3,5,7 axondeepseg -t SEM -i AxonDeepSeg/models/model_seg_rat_axon-myelin_sem/data_test/image.png --gpu-id 2
Will result in:
I thought you should all be aware of these behaviours, as I’ve looked at your documentation and didn’t see these details noted.
I’ve also shown all of this to @mariehbourget on Zoom, so if anything isn’t well explained, hopefully she can clarify to you.
Environment
See the AxonDeepSeg PR linked above.
System description
rosenberg machine at Poly.
Installed packages
See the AxonDeepSeg PR linked above.
Issue Analytics
- State:

- Created 10 months ago
- Reactions:2
- Comments:8 (8 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks @mathieuboudreau, for uncovering this bug and the extensive details.
@mariehbourget There might be more than a single issue to be addressed but let’s start with one at a time.
Since the
dataloaderdoesn’t utilize GPU (might be wrong but assuming this is correct for now) and there is as suggested by you nothing wrong withget_preds. This essentially means as discussed in the meeting, somewhere after the call to thedataloaderand before the call toget_predsanother GPU is set in the global space and looks like https://github.com/ivadomed/ivadomed/blob/5b2e313154e94bbcc350ab56be7adf10f3d089c4/ivadomed/utils.py#L165 should be blamed for it. I’m curious to know the behavior when we comment out this line particularly because the docs discourage its use and it might lead to the above behaviours (will link to the issue shortly)Thanks @kanishk16 for double-checking this and for the links, they clarify the behavior and will be useful when we move forward with other pytorch versions 🚀.