
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
clarification on norm loss calculation; possible bug?
See original GitHub issuewhen i look at the image at https://github.com/JianqiangWan/Super-BPD/blob/master/post_process/2009_004607.png
shown here

the norm_pred seems to decrease to blue (< 0.5) in the center of the cat’s face (farther from the boundary). this also happen for all midpoints from the boundary of the cat. this is extremely different than the norm_gt
when I look at the code in
https://github.com/JianqiangWan/Super-BPD/blob/master/vis_flux.py#L45
that seems like the correct calculation for the norm
I’ve run this on a few other examples
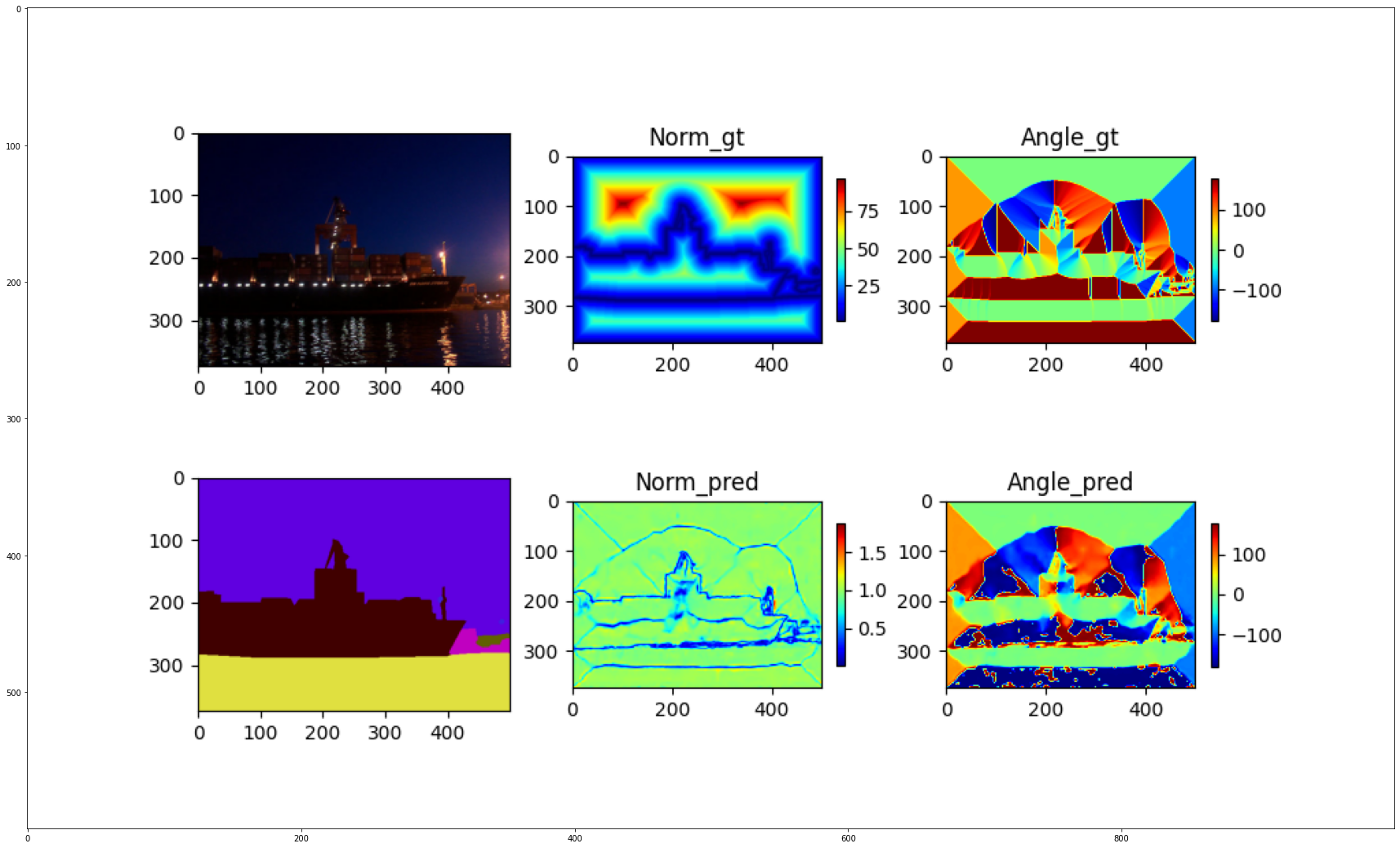
and a similar thing seems to happen.
this led me to go investigate the implementation of the loss
If I’m understanding the loss as defined in the paper

that means norm_loss should be pred_flux - gt_flux like in https://github.com/JianqiangWan/Super-BPD/blob/master/train.py#L42
norm_loss = weight_matrix * (pred_flux - gt_flux)**2
however, this happens after https://github.com/JianqiangWan/Super-BPD/blob/master/train.py#L39. which, I believe, is incorrect
I believe that L39 needs to happen after L42. otherwise, the norm_loss as-is is actually training the norm values to be angle values.
This makes sense as if we look at the norm_pred outputs, they look more similar to the norm_angle outputs than they should be.
HOWEVER, I could be completely misunderstanding the norm_loss term, so please let me know if I am! 🤞
Issue Analytics
- State:

- Created 3 years ago
- Comments:6 (3 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post{kind=link}
We define gt flux at each pixel as a two-dimensional unit vector pointing from its nearest boundary to the pixel. So gt flux around medial points have nearly opposite directions. It is difficult for neural networks to learn such sharp changes, and the network is more inclined to get a smooth transition (like from -1 to 1, network tend to output -1 -0.5 0 0.5 1).
For the norm loss, gt flux is a two-dimensional unit vector field, pred flux does not to be normalized. For the angle loss, normalize pred flux inside or outside of torch.acos is the same.
We need two channels (x, y) to express a flux field, gt flux around medial points can be roughly expressed as (x1, y1) and (-x1, -y1) since they have opposite direction. From -x1 to x1 or -y1 to y1, network hardly gets the sharp transition, tending to get smooth transition.
From -x1 to x1 or -y1 to y1, network hardly gets the sharp transition, tending to get smooth transition.
norm = sqrt( x**2 + y**2), so pred norm between medial points (x to -x) or boundary points (-x to x) is very small, but the angle is still correct (we only use angle information for image segmentation). Again, norm gt at each pixel is 1, ‘norm gt’ in the picture is a distance transform map before normalization.