
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Spark-ML Pipeline freezes and never finishes with medium-sized dataset
See original GitHub issueWhile trying to test spark-nlp out of the box I am running into a situation where the process stalls in some part of the pipeline with no further progress. I made sure you wait a significant time, but the processes never terminated…
Description
I am very interested in using Spark-NLP to generate embeddings for a medium-sized set of documents for the purposes of comparing queries to a set of sentences. In order to try it out and kick the tires a bit I have taken one of the stock examples from the python getting started page and simply inserted my dataframe (significantly undersampled) to test things. I am working on Databricks.
Here are the setups for my cluster based on what I’ve seen on your site and various tutorials • https://nlp.johnsnowlabs.com/docs/en/install#python • https://medium.com/spark-nlp/spark-nlp-quickstart-tutorial-with-databricks-5df54853cf0a
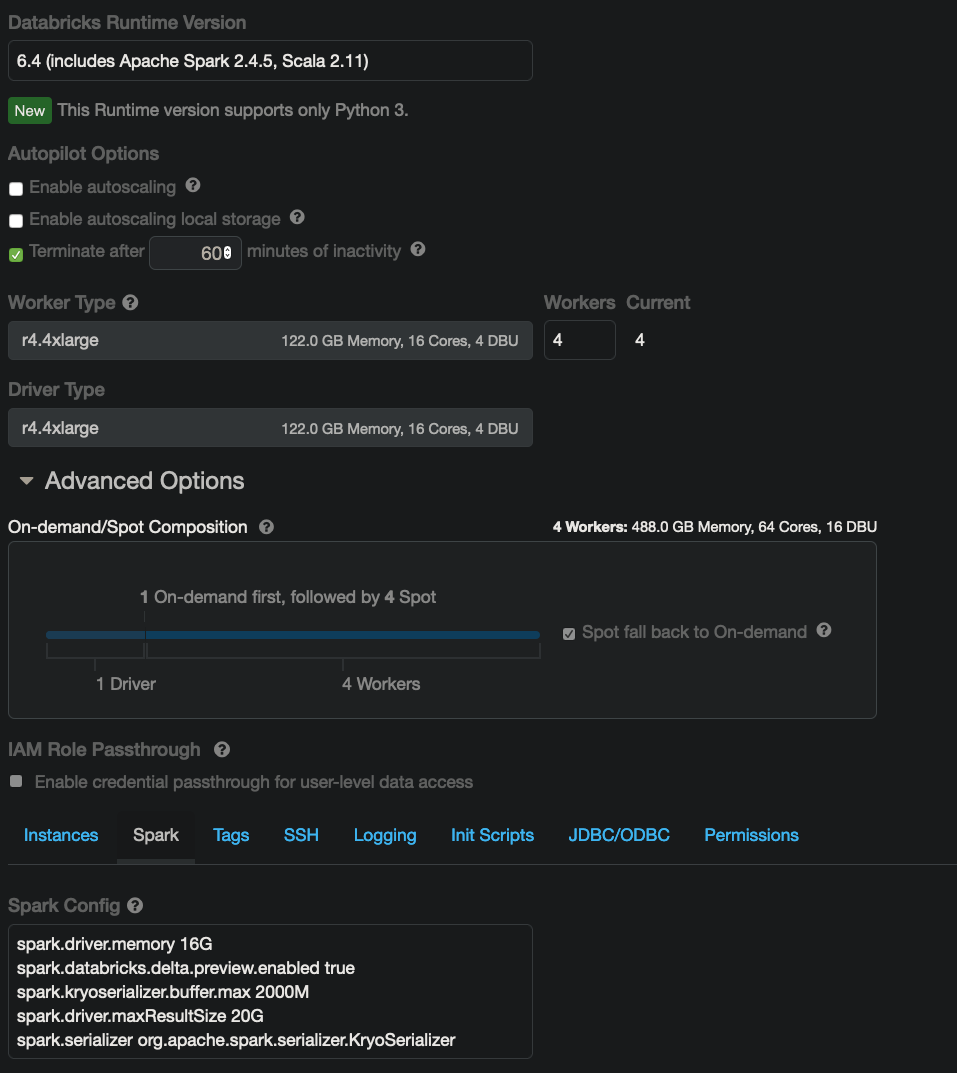
Here are the libraries installed as described:
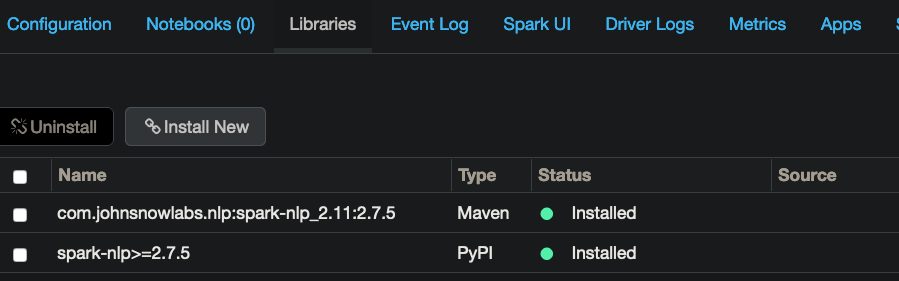
I was able to run the test process that uses a tiny dataframe. Next, I swapped in my dataset and sampled
• 100 records. It worked.
• 1000 records. It worked.
• 10000 records. it worked.
Above that it did not work and freezes each time in some stage of the pipeline
The cluster has good cluster memory (the cluster I sent here is much smaller than the original with the same behavior.
I have looked into every possible diagnostic, log, stderr, stdout, etc. but nothing seems to indicate a problem. It just never finishes or yields a result.
Here’s the code:
from pyspark.sql.functions import udf
from pyspark.sql.types import *
from pyspark.sql import functions as F
import sparknlp
from pyspark.ml import Pipeline
from sparknlp.pretrained import PretrainedPipeline
from sparknlp.annotator import *
from sparknlp.base import *
spark = sparknlp.start() # I have tried it with this and without this. I don't think it's required in DB, but it does not change the outcome
# Load my dataframe
HyperTextDF = spark.read.format("delta").load(fName)
print("There are {:,} records".format(HyperTextDF.count()))
HyperTextDF = (HyperTextDF
.filter("textCat IN ('predicate')")
.filter("numChars <= 128")
# Undersample
.limit(sc.defaultParallelism*10000)
# We only need these fields
.select("imdbId", "text")
# make sure to take advantage of the cores we have
.repartition(sc.defaultParallelism*10)
).cache()
print("There are {:,} records".format(HyperTextDF.count()))
There are 640k records in this test
The pipeline:
# Basic Spark NLP Pipeline
document_assembler = (DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
cleanUpPatterns = ["a-zA-Z"] # "[^\w\d\s]", "<[^>]*>", "\-\_"]
removalPolicy = "pretty_all"
document_normalizer = (DocumentNormalizer()
.setInputCols("document")
.setOutputCol("normalizedDocument")
.setAction("clean")
.setPatterns(cleanUpPatterns)
.setPolicy(removalPolicy)
.setLowercase(True)
)
sentence_detector = (SentenceDetector()
.setInputCols(["normalizedDocument"])
.setOutputCol("sentence")
)
tokenizer = (Tokenizer()
.setInputCols(["normalizedDocument"])
.setOutputCol("token")
)
elmo = (ElmoEmbeddings
.pretrained()
.setInputCols(["token", "normalizedDocument"])
.setOutputCol("elmo")
.setPoolingLayer("elmo")
)
nlpPipeline = Pipeline(stages=[
document_assembler,
document_normalizer,
sentence_detector,
tokenizer,
elmo,
])
Run it:
nlp_model = nlpPipeline.fit(HyperTextDF)
processed = nlp_model.transform(HyperTextDF).cache()
print("There are {:,} records".format(processed.count()))
Then we see this…forever:
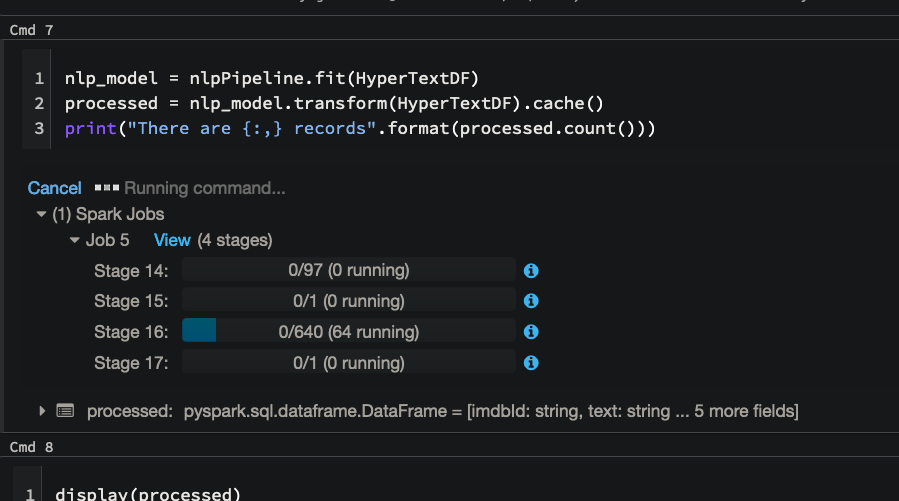
I appreciate any help or insight into this issue. Thanks
Expected Behavior
Process finished and yields annotated dataframe
Current Behavior
Process freezes and never yield an outcome
Possible Solution
Steps to Reproduce
Run the stock example with a different, bigger dataset
Context
Trying to process a large set of sentences to get embedding for an application where we need to finds nearest neighbors in embedding space for a query
Your Environment
- Spark NLP version
sparknlp.version(): 2.7.5 - Apache NLP version
spark.version: - Java version
java -version: - Setup and installation (Pypi, Conda, Maven, etc.): Maven, pypi
- Operating System and version:
- Link to your project (if any):
From Databricks:
System environment
Operating System: Ubuntu 16.04.6 LTS
Java: 1.8.0_252
Scala: 2.11.12
Python: 3.7.3
R: R version 3.6.2 (2019-12-12)
Delta Lake: 0.5.0
Issue Analytics
- State:

- Created 2 years ago
- Comments:10 (2 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks for the clarification. Good news — I was able to run 16M sentences thru BERT in about 12 Minutes. So, I am on my way to getting the collection I wanted to experiment with. I’m going to try out Universal Sentence Embeddings, XLNet and I should be golden. Thanks for the help and the great module!
BTW, your advice for parameter tuning has panned out and I have been able to churn through some good-sized queries in a timely manner. Still cleaning some things, but I am in a good spot now. Although I do have one more question WRT
DocumentNormalizer