
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[KED-2956] When `before_node_run` hook mutates the catalog, the immediate node doesn't get the updated catalog
See original GitHub issueDescription
First raised by @maria-olivia-lihn, who found it while working in Databricks, Python 3.8, Kedro 0.17.5.
Context
How has this bug affected you? What were you trying to accomplish?
Mutate the catalog (i.e. update parameters) dynamically inside a node hook - before_node_run.
Steps to Reproduce
kedro new -s pandas-iris
The structure of the pipeline looks like this:
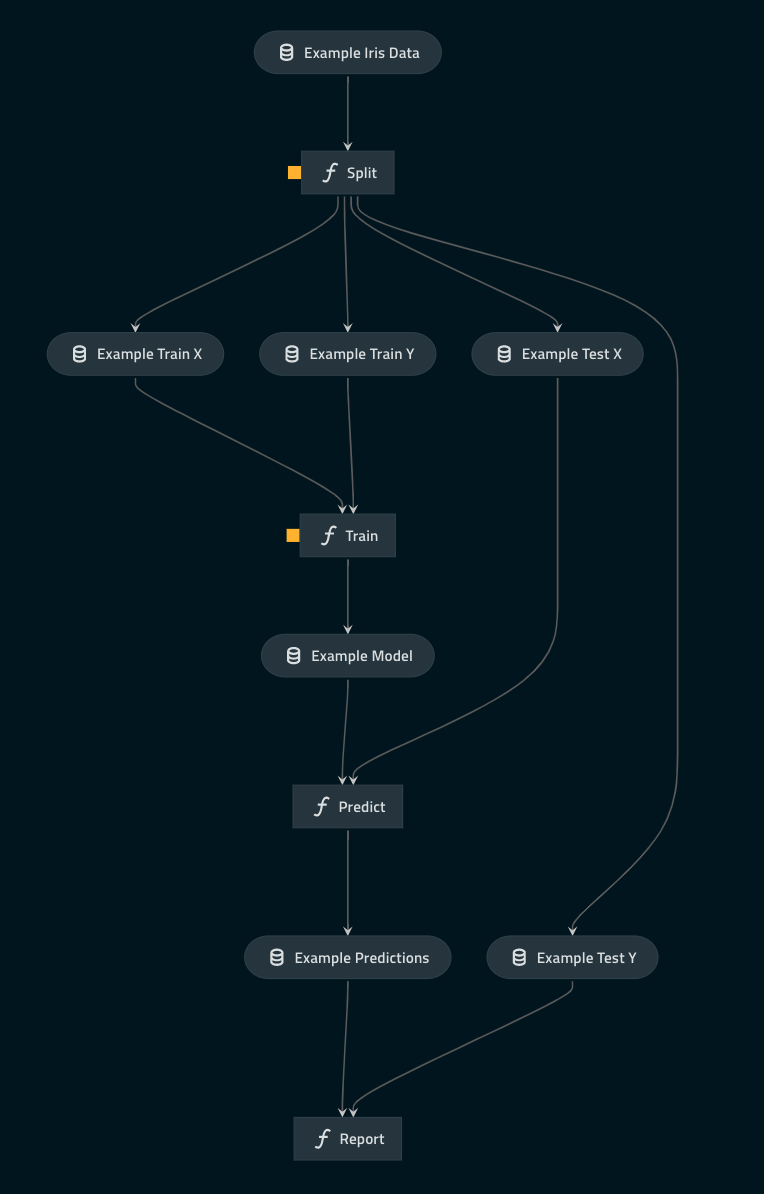
- update
hooks.pywith the following:
@hook_impl
def before_node_run(self, node, catalog):
if node.name == "train":
new_parameter = MemoryDataSet(data=0.05)
catalog.add("params:example_learning_rate", new_parameter, replace=True)
logger.info("CONTENTS OF params:example_learning_rate")
logger.info(catalog.load("params:example_learning_rate"))
Make sure there’s a logger at the top of the file
logger = logging.getLogger(__name__)
- update the signature of the node function
train_modelinsrc/package_name/data_science/nodes.pyand add a logging statement:
def train_model(
train_x: pd.DataFrame, train_y: pd.DataFrame, num_iter, lr,
) -> np.ndarray:
"""Node for training a simple multi-class logistic regression model. The
number of training iterations as well as the learning rate are taken from
conf/project/parameters.yml. All of the data as well as the parameters
will be provided to this function at the time of execution.
"""
log.info("VALUE OF example_learning_rate is %f", lr)
X = train_x.to_numpy()
Y = train_y.to_numpy()
log comes from log = logging.getLogger(__name__) which I’ve moved to the top from inside report_accuracy().
- update the pipeline definition in
src/package_name/data_science/pipeline.pyfor the followingnode
node(
train_model,
["example_train_x", "example_train_y", "params:example_num_train_iter", "params:example_learning_rate"],
"example_model",
name="train",
),
kedro run
Expected Result
train node would log VALUE OF example_learning_rate is 0.05 (update value from the hook).
Actual Result
train node logs VALUE OF example_learning_rate is 0.01 (original value in parameters.yml.
Workaround
Moving the mutating behaviour to a node upstream, e.g. split, ensures that nodes downstream actually get the updated version of the catalog object.
Not entirely sure what’s going on yet, if it’s a back-to-pass-by-reference-basics journey or not, needs more investigation.
Your Environment
- Kedro version used (
pip show kedroorkedro -V): 0.17.5 - Python version used (
python -V): 3.7 - Operating system and version: Mac
Issue Analytics
- State:

- Created 2 years ago
- Comments:8 (4 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks @lorenabalan. Using a dataset is not the best idea as the parameters have to either be computed from a dataset which is product of a previous node, or using another input. To make it more clear: we need the option to set the parameter “last_date” either automatically from an output dataset (using last data available) or using input from execution (depending on “automatic” parameter). Once the “last_date” is set, we need to calculate “start_date” as 6 months before “last_date” and an additional parameter which is 2 months before “last_date”. At the time, I couldn’t figure out how to do this using datasets so I thought it would be easier to use hooks and parameters. Right now i changed the hooks execution to one node before and everything runs in place.
Thanks for clarifying. For the purpose of this issue, I’m going to close it as not a bug. However feel free to raise the question about your particular use case either in a GitHub discussion or, maybe even better, on our Discord channels, to engage our community, as they might have come across a similar pattern before.