
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[Question] Significant difference in performance between Kornia and Torchvision image augmentations
See original GitHub issueI have trained two models that use the same sequence of image augmentations but in Torchvision and Kornia and I’m observing a significant difference in the performance of these models. I understand that despite fixing random seeds, these augmentations might still be different which might cause some difference in the test accuracies, but on average, I assume that both of these models should end with similar accuracies, especially when these values are averaged over multiple seeds. However, this is not the case.
# PyTorch transformation
train_orig_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
This is the Kornia version of the above PyTorch transformation
class KorniaAugmentationModule(nn.Module):
def __init__(self, batch_size=512):
super().__init__()
# These are standard values for CIFAR10
self.mu = torch.Tensor([0.4914, 0.4822, 0.4465])
self.sigma = torch.Tensor([0.2023, 0.1994, 0.2010])
self.hor_flip_prob = 0.5
self.jit_prob = 0.8
self.gs_prob = 0.2
self.crop = K.RandomResizedCrop(size=(32, 32), same_on_batch=False)
self.hor_flip = K.RandomHorizontalFlip(p=self.hor_flip_prob, same_on_batch=False)
self.jit = K.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1, p=self.jit_prob, same_on_batch=False)
self.rand_grayscale = K.RandomGrayscale(p=self.gs_prob, same_on_batch=False)
self.normalize = K.Normalize(self.mu, self.sigma)
# Note that I should only normalize in test mode; no other type of augmentation should be performed
def forward(self, x, params=None, mode='train'):
B = x.shape[0]
if mode == 'train':
x = self.crop(x, params['crop_params'])
x = self.hor_flip(x, params['hor_flip_params'])
x[params['jit_batch_probs']] = self.jit(x[params['jit_batch_probs']], params['jit_params'])
x = self.rand_grayscale(x, params['grayscale_params'])
x = self.normalize(x)
return x
Rest of the code for training and testing these models is shared.
These are the training loss and testing accuracy curves for kornia (orange) and torchvision (green)
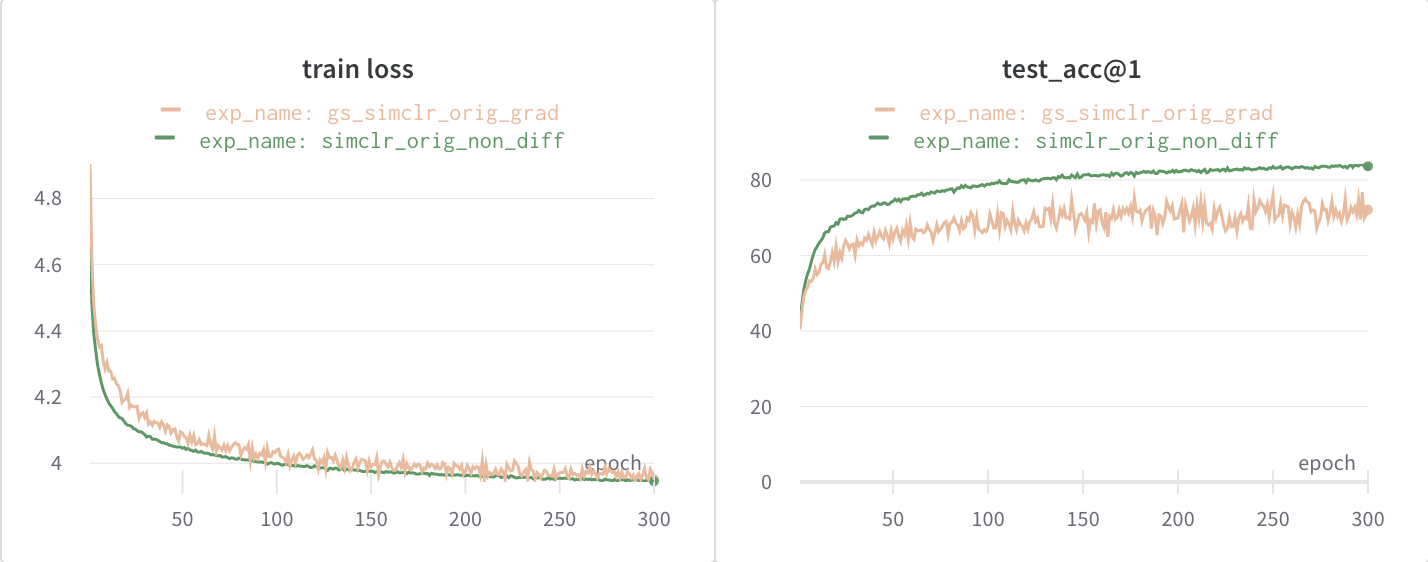
The difference in test accuracies between the two models is nearly ~11% which is very significant.
I have posted this question on PyTorch discussion forum as well. Could you please give pointers on why this behavior is being observed, is this expected and if not, what could be ways to debug this?
Issue Analytics
- State:

- Created 3 years ago
- Reactions:3
- Comments:21 (10 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Another difference between Kornia and Torchvision that can be source of error is how to use gaussian blur.
In Kornia
sigmais a tuple used deterministically to provide standard deviation for x and y axis:In torchvision
sigmacan be either a float used for both axes or a tuple used to uniformly sample a sigma used for both axes:To have similar behavior with torchvision, one can create a
RandomGaussianBlur2das follows:However, this solution does not produce randomness for sigma on the instance-level. To have randomness on instances it would require sampling a sigma tensor for each instance to transform, creating filters accordingly to sigma, reshaping the input and stacking the filters to apply grouped convolution. Then, reshaping back the output of convolution to match the input shape.
Both libraries work accordingly to their documentation, so it is not a bug however it might be an issue for some users if you overlook documentation (as I did) as both APIs use the same argument name
sigmabut for different purposes.I checked the code in https://github.com/rdevon/kornia/commit/09d95360837e557a5d83f3bd891f0271d546ee62 and I think the easiest approach is to add a flag (OPENCV/PIL) to those 2 funcionalities. By default set OPENCV and then we do not need to change anything else. What do you think @edgarriba @shijianjian @gmberton ?
we are talking about 10 lines of code… shouldn’t be a drama.