
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Metrics are logged on each batch, but not on each accum. step
See original GitHub issue🐛 Bug
I’m not sure, that this is a bug, but it’s really unexpected behavior. Metrics are logged on each batch, as we can see here:
In case of using Tensorboard logger we will see the following picture:
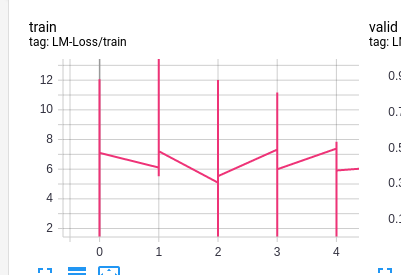
these vertical lines are a sets of points, logged for each individual step. Is there any way to log aggregated metrics for each step (so that only one log point appears for each step) ?
I can set row_log_interval equal to the accumulation steps, and only one logging point will appear, but in this case, I’ll not aggregate the accumulation step metrics, but only take the last one.
Environment
PyTorch version: 1.4.0 OS: Ubuntu 16.04.6 LTS Python version: 3.7
Versions of relevant libraries: [pip] numpy==1.18.1 [pip] pytorch-lightning==0.7.1 [pip] torch==1.4.0 [pip] torchvision==0.5.0
Issue Analytics
- State:

- Created 4 years ago
- Comments:11 (11 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@jeremyjordan Let me first formalize the problem.
Here are
log_metricsmethods for few pytorch-lightning loggers:TensorBoardLogger:NeptuneLogger:NeptuneLogger:MLFlowLogger:CometLogger:As we can see, each logger’s method receives the
stepargument. And it works great, when there isaccumulate_grad_batchesequals 1. But if we setaccumulate_grad_batches, for instance equals 2, then each step will be logged twice. There will be 2 sets of metrics for step 0, 2 sets of metrics for step 1 and so on.It happens, because the train loop calls
log_metricsroutine on each batch: https://github.com/PyTorchLightning/pytorch-lightning/blob/12b39a74b4d5892c03115770b1d0b796ff941b57/pytorch_lightning/trainer/training_loop.py#L445-L449And when we have
accumulate_grad_batches!= 1, batch and step are not the same thing.So, I see here the following solutions:
stepcheck in each logger’slog_metricsmethod. Ifstepis equal to the previous one, don’t log metrics, but instead, aggregate them with the previous ones (sum or weighted sum). It’s a bad solution, because it’ll require a lot of fixing (actually in all existing loggers) and also, it’ll make it oblige future loggers developers to implement such the check and aggregation in their loggers.log_metricsmethod in another place (where the actual optimizer step is performed). Such the refactoring assumes, that all accum. batches metrics will be stored somewhere in the train loop, aggregated and passed to thelog_metricsmethod after optimizer step is performed. It’s slightly better solution, than previous two, but is also assumes a portion of refactoring and structure changes.accumulate_grad_batchestimes for each optimizer step.What do you think? maybe you have another options? Or maybe I’ve totally missed something, and there exists some already implemented trick in the PL, which solves this issue?
yeah we should handle that case better, would you be interested in drafting a PR to address this?