
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Wrong steps per epoch while DDP training
See original GitHub issue🐛 Bug
I’m using DPP to train a encoder model with 5 GPU nodes, batch_size is 400 pre node, model will gather all embeddings from 5 nodes to create a 2000*2000 matrix, then compute loss with this matrix.
Each node keeps 2623678 train samples and 491939 val samples, so the steps per epoch shoud be 2623678//400+491939//400 is 7788, BUT, the preocess bar show the steps per epoch is 1556, seems come from 2623678//2000+491939//2000
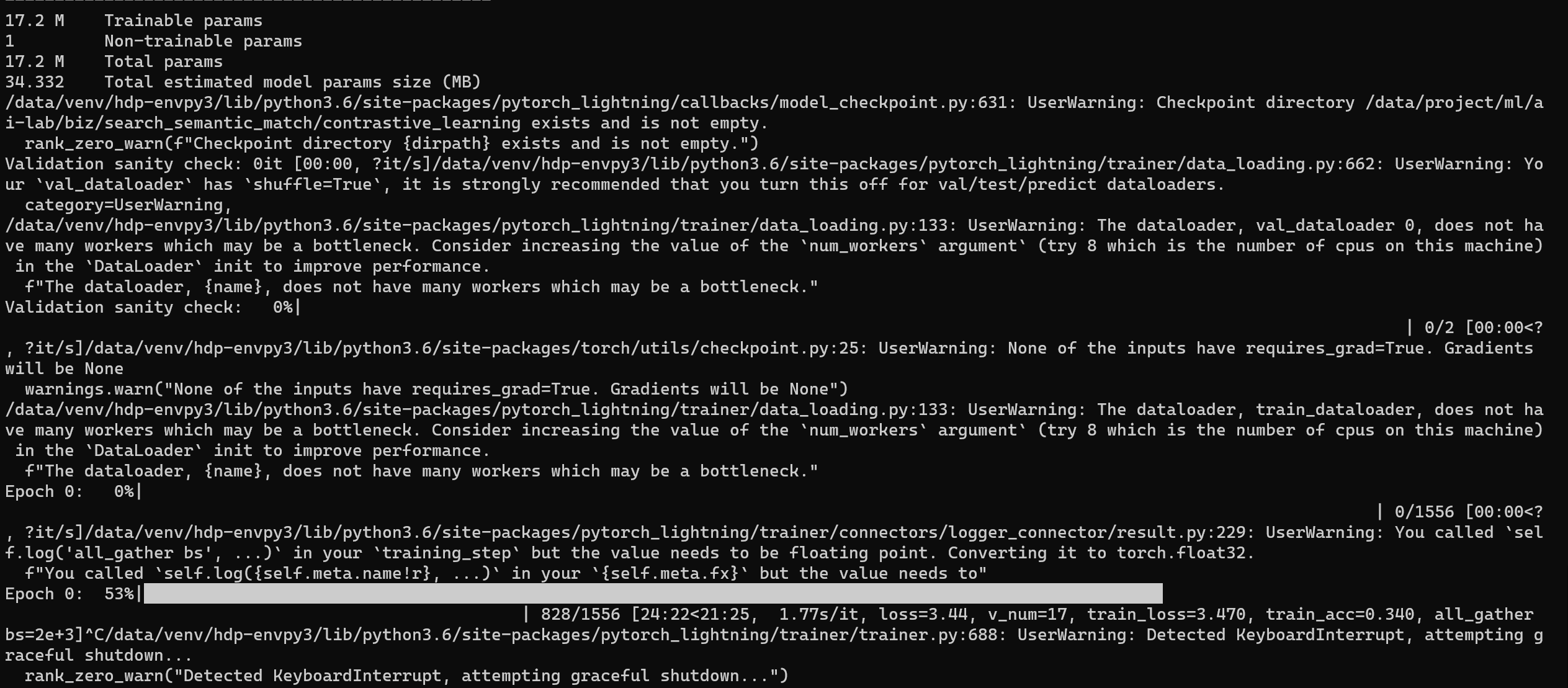
trainer config:
trainer = pl.Trainer(accelerator='gpu', devices=1, auto_select_gpus=True, max_epochs=100,
callbacks=callbacks, precision=16,
log_every_n_steps=20, strategy="ddp_sharded", num_nodes=5)
trainer.fit(model=self.pl_model, datamodule=self.data_module)
The train dataloader and val dataloader created with batch size 400:

To Reproduce
Expected behavior
Environment
- PyTorch Lightning Version : 1.5.10
- PyTorch Version : 1.9.0+cu102
- Python version : 3.6.8
- OS : Linux
- CUDA/cuDNN version: 11.0
- How you installed PyTorch (
conda,pip, source): pip
Additional context
cc @justusschock @kaushikb11 @awaelchli @akihironitta @rohitgr7
Issue Analytics
- State:

- Created a year ago
- Comments:8 (4 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Oh this is a very important detail!!! In this case, make sure to tell Lightning not to add a distributed sampler, as explained by @rohitgr7. You can set
Trainer(replace_sampler_ddp=False).Because of the distributed sampler in PyTorch, you wouldn’t need to split the dataset manually normally, as this would normally be done online through sampling.
Awesome! Glad this was a relatively easy fix 😃 Let us know if there are further questions.