
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
DepthAI and megaAI 'SmartMotion' Feature
See original GitHub issueThe why:
When running DepthAI/megaAI object detection outdoors at distance for fixed installation, we’re seeing person detection only works up to 75 feet or so at most.
The reason for this is we’re simply decimating the high res input image (say 12MP) down to the size of the input of the neural blob. For example in this pedestrian-detection-adas-0002 model (here) the input resolution of the model is 672 x 384 pixels.
So when decimating down, people at greater than 75 feet are even impossible for a human observer to tell it’s a person at this 672 x 384 resolution.
So one solution to this would be to tile the 4056 x 3040 image in rectangles of 672 x 384. So with no overlap, this would be approximately 47 tiles. But to pick up people who say are between tiles, you’d probably need various overlap and scales, etc. So best-case is probably a factor of 100 slow-down doing this approach. Straight-up tiling would be a factor of 47 slow down. So it’s not ideal for keeping reasonable frame rate.
So we brainstormed an idea that would allow still-decent framerate while allowing detecting people (and other objects) at distance, taking advantage of the degrees of freedom afforded by a fixed camera install.
The how:
So one idea that came out of trying to solve this was to combine 3 things:
- Motion estimation. (https://github.com/luxonis/depthai/issues/245)
- Object detection.
- Object tracking.
The proposed flow is to use motion detection to advise what part of the image has new content. If a person is entering the frame, they will cause motion. This takes advantage of the fact that the camera is fixed.
Here is an example of using motion detection on a fixed camera: https://www.pyimagesearch.com/2015/05/25/basic-motion-detection-and-tracking-with-python-and-opencv/
(As usual, thanks PyImageSearch / Adrian!)
Then the regions of motion can be used to advise on how big of an image to decimate into the object detector. Example below:
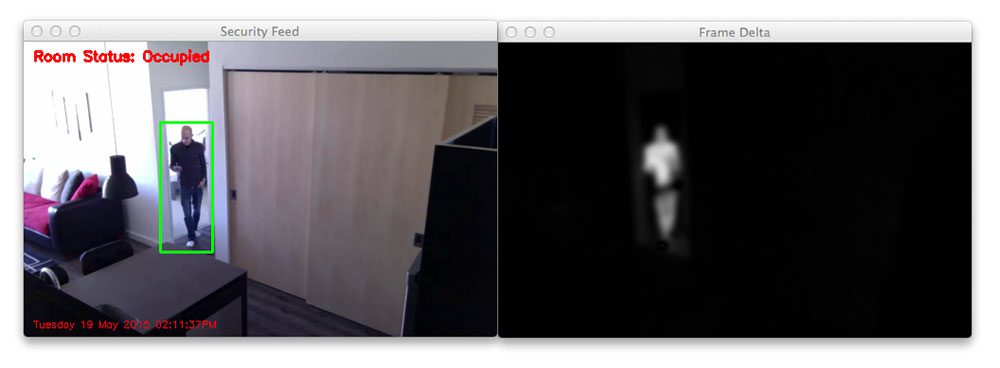 Figure: Credit PyImageSearch
Figure: Credit PyImageSearch
In this case, there’s only motion where that person (Adrian) is.
If that area of motion is smaller than the neural neural blob input resolution (672 x 384 pixels in the example above), then the neural input resolution is used around the centroid of the motion.
If the area of motion is larger than the blob input resolution, then that area (say it’s 1,200 pixels by 600 pixels) is decimated to the input resolution (so 672 x 384 pixels in this example).
So the way this scales is that if there’s close motion - filling the whole image - then the whole image is decimated into the neural blob input resolution.
As the motion gets smaller, a smaller and smaller area of the overall image is decimated into the neural blob, until there’s no decimation at all.
So this works for anything that is moving. But the problem is that once something stops moving (say a person or a car stops for a period), it will fall apart.
This is where object tracking comes in.
Once motion activates the object detector and an object is found, this result is passed to an object tracker. Object trackers can operate on high-resolution images much easier than neural object detectors.
So the object tracker can then track the object on the full-resolution image going forward until the object leaves the field of view, or goes to a sufficiently-low confidence that the tracker drops it (and thus the motion-detection -> object detection -> object tracker flow starts again).
Note: This sort of flow will likely be supported by our pipeline builder v2, which is in-progress.
The what:
Use motion detection to inform the cropped size(s) to pass to an object detector which covers only that cropped area, then feed that result to an object tracker which tracks on full-frame to cover cases where the object stops moving.
Issue Analytics
- State:

- Created 3 years ago
- Comments:7 (1 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Demo of computing difference of 2 consecutive frames with a custom NN model can be found here.
This proposal is an excellent idea, and I would guess it is similar to the way that human vision works. There is a separate system just looking for motion. When something moves, your attention is drawn to focus on that spot, where you then try to recognize a shape within just that specific area, and maybe on a slower timescale. Humans are also good at seeing something new moving in the presence of other, repetitive background motion, so I guess overall “motion” gets divided down and sorted into different bins to compare against past kinds and amounts of motion, but that’s another level of refinement.