
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Bulk Document Indexing
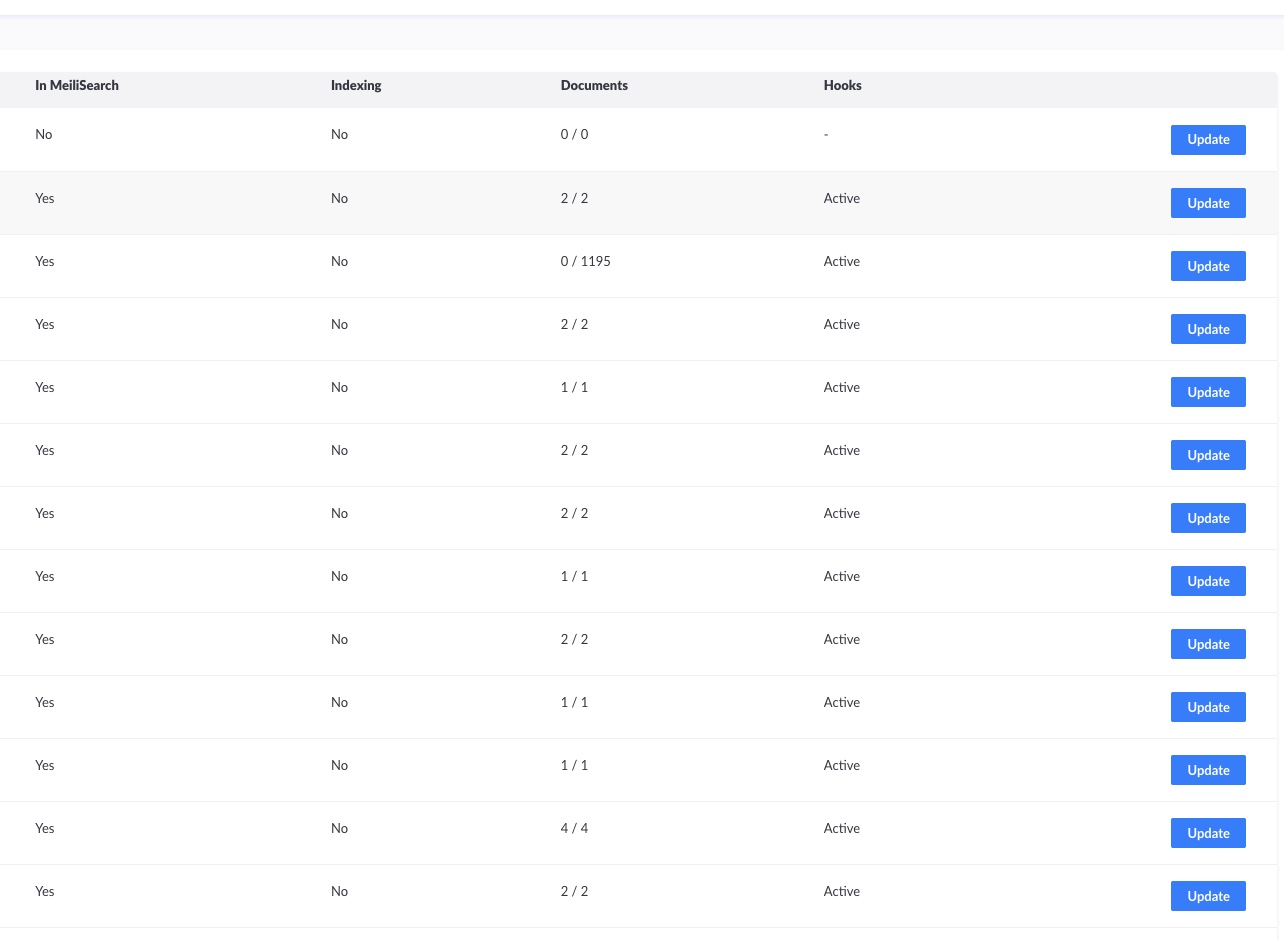
See original GitHub issueDescription Location: admin/plugins/meilisearch As a User, when using the Meilisearch Strapi plugin, and utilizing the Update Button with a 1000+ data-set.
Expected behavior Document count out of total will increment/transfer. Currently sitting at: 0/1195 using the Update Feature.
Current behavior Nothing happens. When manually un-publishing/republishing an item in the collection, the documents will sync via hook.
Screenshots or Logs
After Manual Publishing:

Environment (please complete the following information):
- OS: OSX
- MeiliSearch version: v0.23.1
- strapi-plugin-meilisearch version: “strapi-plugin-meilisearch”: “^0.3.3”,
- Browser: Chrome etc etc (Brave/Safari)
- Strapi version: 3.6.8
- Flags: --http-payload-size-limit=1048576000
- Resources: 16/32GB of RAM
Other:
- Able to upload the Sample Dataset without issue of Movies. (19k+)
{
"numberOfDocuments": 19546,
"isIndexing": false,
"fieldDistribution": {
"genres": 19456,
"id": 19546,
"overview": 19546,
"poster": 19546,
"release_date": 19546,
"title": 19546
}
}
Area of Interest: strapi-plugin-meilisearch/admin/src/components/Collections.js -> updateCollections.js
// Re-indexes all rows from a given collection to MeilISearch
const updateCollections = async ({ collection }) => {
setCollectionsList(prev =>
prev.map(col => {
if (col.name === collection)
return { ...col, indexed: 'Start update...', _isChecked: true }
return col
})
)
const response = await request(`/${pluginId}/collections/${collection}/`, {
method: 'PUT',
})
if (response.error) {
errorNotifications(response)
} else {
successNotification({ message: `${collection} update started!` })
watchUpdates({ collection }) // start watching
}
setUpdatedCollections(false) // ask for up to date data
}
"databaseSize": 189247488,
"lastUpdate": "2021-11-02T03:44:39.692897Z",
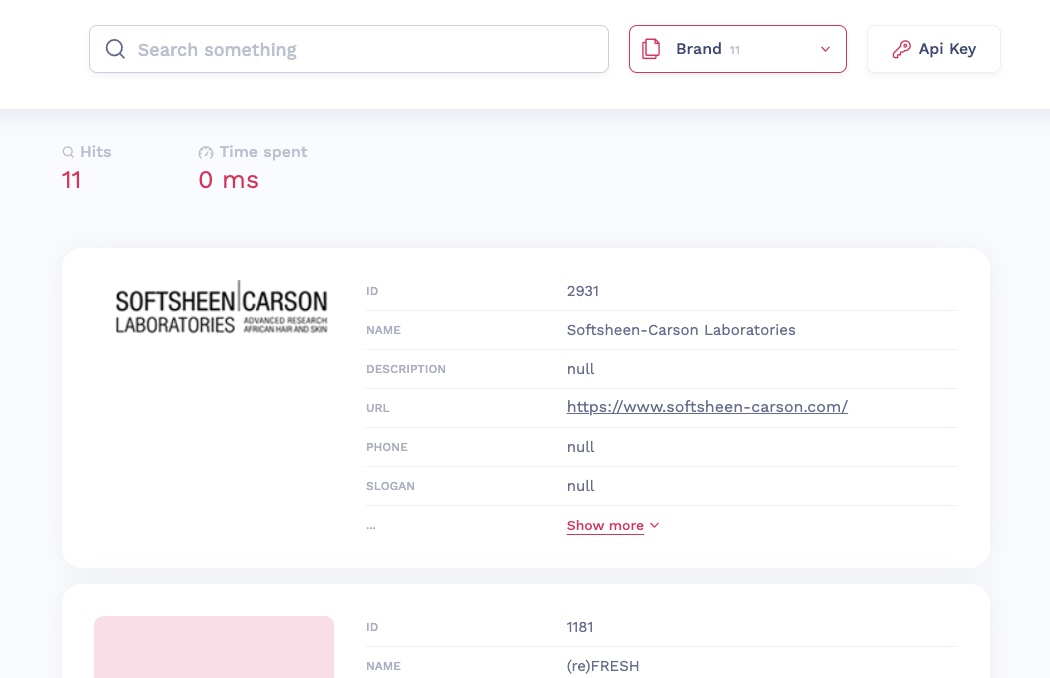
When Manually Un/Re-Publishing - Able to Confirm Data Transfer.
"brand": {
"numberOfDocuments": 11,
"isIndexing": false,
"fieldDistribution": {
"Address": 11,
"PointOfContact": 11,
"Social": 11,
"avatar": 11,
"awards": 11,
"brandProfileMedia": 11,
"description": 11,
"id": 11,
"name": 11,
"phone": 11,
"products": 11,
"salons": 11,
"slogan": 11,
"slug": 11,
"url": 11
}
},
Issue Analytics
- State:

- Created 2 years ago
- Reactions:1
- Comments:5 (4 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Working: next_v0.4.0_release | 9eb186577bfb5afd942bc8eee597e0b286b83edd
However, due to another related issue, the batch needs to be reduced from 1000 -> 500.
SQLITE_ERROR: too many SQL variablesFile:
connectors/meilisearch/index.jsChange:const BATCH_SIZE = 500PR: https://github.com/jbelke/strapi-plugin-meilisearch/commit/56f3b17a1463a6ff307daf0aba337653671e792fThanks @jbelke I’m looking into this 😃