
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[MusicBERT]: Could not infer model type from Namespace (eval_genre.py)
See original GitHub issueHello!
I’m trying to run the evaluation script for the genre classification task using the command python -u eval_genre.py checkpoints/checkpoint_last_musicbert_small.pt topmagd_data_bin/x, and I’m getting the error below when running RobertaModel.from_pretrained:
Traceback (most recent call last):
File "eval_genre.py", line 39, in <module>
user_dir='musicbert'
File "/home/aspil/muzic/musicbert/fairseq/fairseq/models/roberta/model.py", line 251, in from_pretrained
**kwargs,
File "/home/aspil/muzic/musicbert/fairseq/fairseq/hub_utils.py", line 75, in from_pretrained
arg_overrides=kwargs,
File "/home/aspil/muzic/musicbert/fairseq/fairseq/checkpoint_utils.py", line 353, in load_model_ensemble_and_task
model = task.build_model(cfg.model)
File "/home/aspil/muzic/musicbert/fairseq/fairseq/tasks/fairseq_task.py", line 567, in build_model
model = models.build_model(args, self)
File "/home/aspil/muzic/musicbert/fairseq/fairseq/models/__init__.py", line 93, in build_model
+ model_type
AssertionError: Could not infer model type from Namespace(_name='roberta_small', activation_dropout=0.0, activation_fn='gelu', adam_betas='(0.9,0.98)', adam_eps=1e-06, all_gather_list_size=16384, arch='roberta_small', attention_dropout=0.1, azureml_logging=False, batch_size=8, batch_size_valid=8, best_checkpoint_metric='loss', bf16=False, bpe='gpt2', broadcast_buffers=False, bucket_cap_mb=25, checkpoint_shard_count=1, checkpoint_suffix='_bar_roberta_small', clip_norm=0.0, cpu=False, criterion='masked_lm', curriculum=0, data='topmagd_data_bin/0/input0', data_buffer_size=10, dataset_impl=None, ddp_backend='c10d', device_id=0, disable_validation=False, distributed_backend='nccl', distributed_init_method=None, distributed_no_spawn=False, distributed_port=-1, distributed_rank=0, distributed_world_size=8, distributed_wrapper='DDP', dropout=0.1, empty_cache_freq=0, encoder_attention_heads=8, encoder_embed_dim=512, encoder_ffn_embed_dim=2048, encoder_layerdrop=0, encoder_layers=4, encoder_layers_to_keep=None, end_learning_rate=0.0, eos=2, fast_stat_sync=False, find_unused_parameters=False, finetune_from_model=None, fix_batches_to_gpus=False, fixed_validation_seed=None, force_anneal=None, fp16=False, fp16_init_scale=128, fp16_no_flatten_grads=False, fp16_scale_tolerance=0.0, fp16_scale_window=None, freq_weighted_replacement=False, gen_subset='test', heartbeat_timeout=-1, keep_best_checkpoints=-1, keep_interval_updates=-1, keep_last_epochs=-1, leave_unmasked_prob=0.1, load_checkpoint_heads=True, load_checkpoint_on_all_dp_ranks=False, localsgd_frequency=3, log_format='simple', log_interval=100, lr=[0.0005], lr_scheduler='polynomial_decay', mask_multiple_length=1, mask_prob=0.15, mask_stdev=0.0, mask_whole_words=False, max_epoch=0, max_positions=8192, max_tokens=None, max_tokens_valid=None, max_update=125000, maximize_best_checkpoint_metric=False, memory_efficient_bf16=False, memory_efficient_fp16=False, min_loss_scale=0.0001, model_parallel_size=1, no_epoch_checkpoints=False, no_last_checkpoints=False, no_progress_bar=False, no_save=False, no_save_optimizer_state=False, no_seed_provided=False, nprocs_per_node=8, num_shards=1, num_workers=1, optimizer='adam', optimizer_overrides='{}', pad=1, patience=-1, pipeline_balance=None, pipeline_checkpoint='never', pipeline_chunks=0, pipeline_decoder_balance=None, pipeline_decoder_devices=None, pipeline_devices=None, pipeline_encoder_balance=None, pipeline_encoder_devices=None, pipeline_model_parallel=False, pooler_activation_fn='tanh', pooler_dropout=0.0, power=1.0, profile=False, quant_noise_pq=0, quant_noise_pq_block_size=8, quant_noise_scalar=0, quantization_config_path=None, random_token_prob=0.1, required_batch_size_multiple=8, required_seq_len_multiple=1, reset_dataloader=False, reset_logging=True, reset_lr_scheduler=False, reset_meters=False, reset_optimizer=False, restore_file='checkpoints/checkpoint_last_bar_roberta_small.pt', sample_break_mode='complete', save_dir='checkpoints', save_interval=1, save_interval_updates=0, scoring='bleu', seed=1, sentence_avg=False, shard_id=0, shorten_data_split_list='', shorten_method='none', skip_invalid_size_inputs_valid_test=False, slowmo_algorithm='LocalSGD', slowmo_momentum=None, spectral_norm_classification_head=False, stop_min_lr=-1.0, stop_time_hours=0, task='masked_lm', tensorboard_logdir=None, threshold_loss_scale=None, tokenizer=None, tokens_per_sample=8192, total_num_update='125000', tpu=False, train_subset='train', unk=3, untie_weights_roberta=False, update_freq=[4], use_bmuf=False, use_old_adam=False, user_dir='musicbert', valid_subset='valid', validate_after_updates=0, validate_interval=1, validate_interval_updates=0, wandb_project=None, warmup_updates=25000, weight_decay=0.01, zero_sharding='none'). Available models: dict_keys(['transformer_lm', 'wav2vec', 'wav2vec2', 'wav2vec_ctc', 'wav2vec_seq2seq']) Requested model type: roberta_small
Environment
- python: Python 3.6.13 :: Anaconda, Inc.
- fairseq: git+https://github.com/pytorch/fairseq@336942734c85791a90baa373c212d27e7c722662#egg=fairseq
Thanks in advance!
Edit: When running the above command with the base checkpoint, I get the following:
Traceback (most recent call last):
File "eval_genre.py", line 39, in <module>
user_dir='musicbert'
File "/home/aspil/anaconda3/envs/musicbert_01/lib/python3.6/site-packages/fairseq/models/roberta/model.py", line 251, in from_pretrained
**kwargs,
File "/home/aspil/anaconda3/envs/musicbert_01/lib/python3.6/site-packages/fairseq/hub_utils.py", line 75, in from_pretrained
arg_overrides=kwargs,
File "/home/aspil/anaconda3/envs/musicbert_01/lib/python3.6/site-packages/fairseq/checkpoint_utils.py", line 355, in load_model_ensemble_and_task
model.load_state_dict(state["model"], strict=strict, model_cfg=cfg.model)
File "/home/aspil/anaconda3/envs/musicbert_01/lib/python3.6/site-packages/fairseq/models/fairseq_model.py", line 115, in load_state_dict
return super().load_state_dict(new_state_dict, strict)
File "/home/aspil/anaconda3/envs/musicbert_01/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1483, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for RobertaModel:
Unexpected key(s) in state_dict: "encoder.sentence_encoder.downsampling.0.weight", "encoder.sentence_encoder.downsampling.0.bias", "encoder.sentence_encoder.upsampling.0.weight", "encoder.sentence_encoder.upsampling.0.bias".
I don’t know if I messed up something, I’d appreciate any help!
Issue Analytics
- State:

- Created a year ago
- Comments:13
 Top Results From Across the Web
Top Results From Across the Web
load pretrained model error ! · Issue #18 - GitHub
When I load pretrained model "finetune-model.pt" follow your demo: ... AssertionError: Could not infer model type from {'_name': ...
Read more >Data model Type or namespace could not be found
Try selecting the "gedaiappEntities" class that I'm assuming is red in your code since it can't find the reference. Once it's selected, hit...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
With your directions and referring to
musicbert/README.mdI was able to replicate the pretrained model (but along with genre classification head) that can be loaded by fairseqRobertaModel.from_pretrained, it can be seen in the sectionAttempting to create working checkpointin this notebook.Setting
--lr 0lead to passing of the assertions that common parts of architectures have same weight (i.e, MusicBERT with classifer $\cap$ MusicBERT), i.e, no change in model weights from provided pretrained weights inmusicbert/README.md:The rest of the checkpoint values (except
cfgandargs) were copied:The saved checkpoints can be loaded directly now (given fairseq is installed with reference to comment above):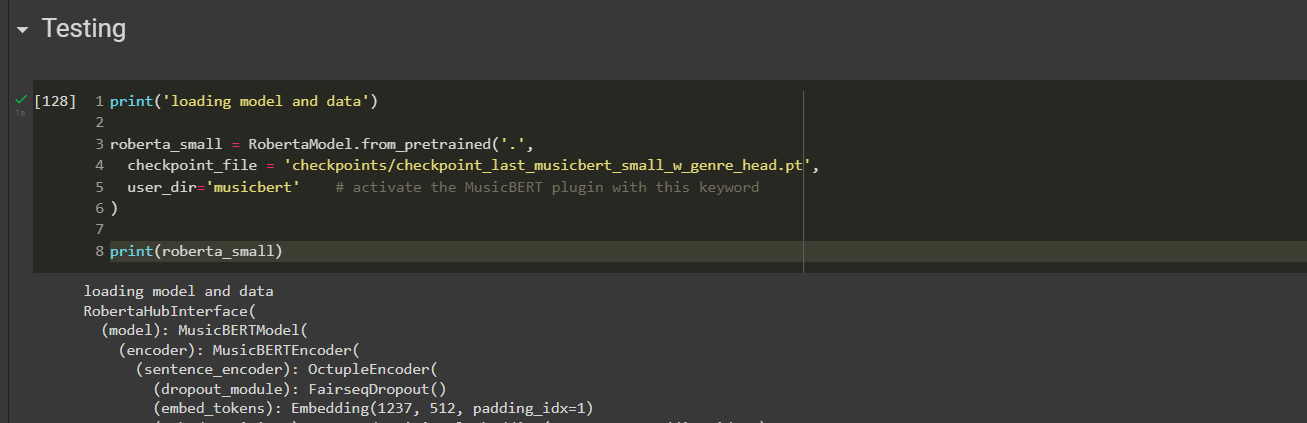

Drive links to saved checkpoints:
gdown --id 1-BW45Vu80GU86ejTT4PFkgjvDhhYWatS) (22.8 mil params)gdown --id 1-6GJyolMS-z-WHdrwzmZGzzeTc01CldF) (103.9 mil params)Update: Checkpoints have been moved:
gdown --id 1XwW3C65VNWckKUcoG23FEm2qCZYZjAOc) (22.8 mil params)gdown --id 1bN1DEFwCz9b3du13Ai9SezujzUlzeRSJ) (103.9 mil params)All command-line tools will work for the MusicBERT model just like the RoBERTa model. (don’t forget the
--user-diroption) You can set the learning rate to zero so the parameters inside the model won’t change.