
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[BUG] "No schema" shown on model version page
See original GitHub issueWillingness to contribute
Yes. I can contribute a fix for this bug independently.
MLflow version
1.27.0
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux version 5.10.104-linuxkit
- Python version: 3.7.13
- yarn version, if running the dev UI:
Describe the problem
When running an experiment and registering a model with a signature, the signature can be seen in the “Artifacts” section on the run page but does not show in the “Schema” section on the model version page.
Run page:
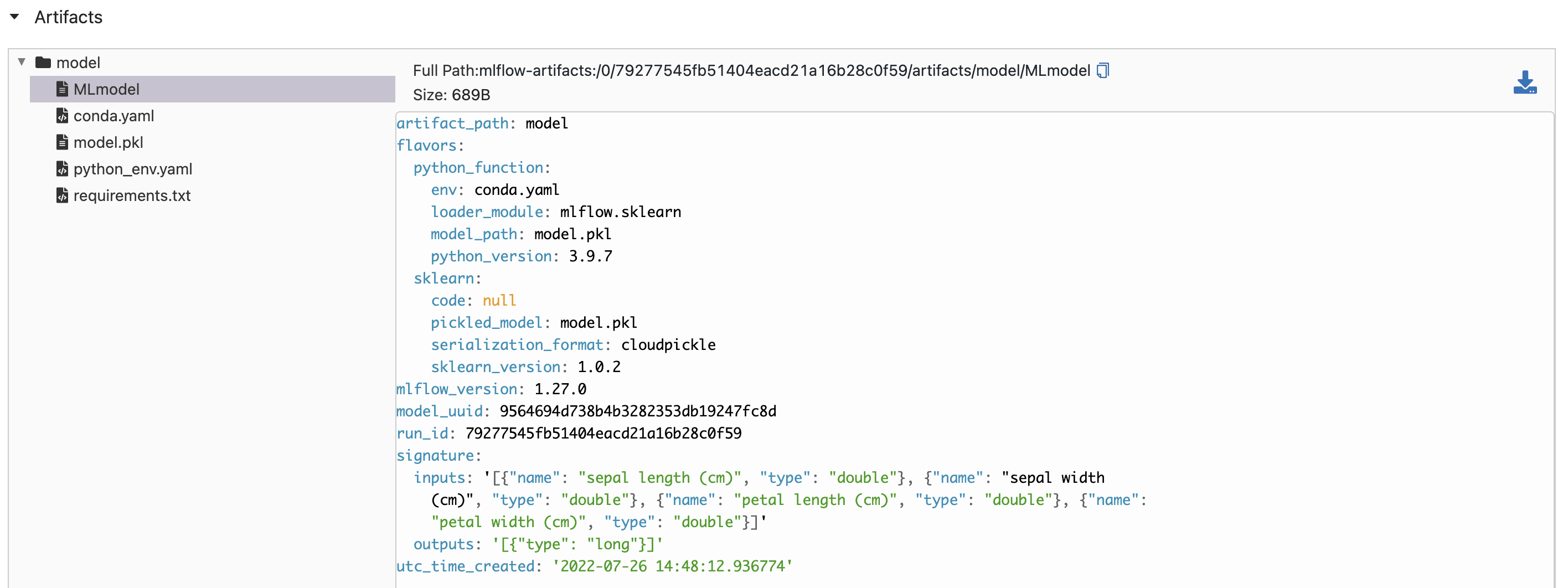
Model version page:

This appears to only be an issue when using the proxied artifact storage set-up described at https://www.mlflow.org/docs/latest/tracking.html#scenario-5-mlflow-tracking-server-enabled-with-proxied-artifact-storage-access.
I was able to fix the issue by modifying the get_model_version_artifact_handler at https://github.com/mlflow/mlflow/blob/master/mlflow/server/handlers.py#L1294 to determine the artifact_path in a similar way to how the get_artifact_handler determines it at https://github.com/mlflow/mlflow/blob/master/mlflow/server/handlers.py#L518
Tracking information
MLflow version: 1.27.0 Tracking URI: http://0.0.0.0 Artifact URI: mlflow-artifacts:/0/0907b0b94e5b4230bde0a177c5a01899/artifacts
mlflow server
--host 0.0.0.0
--port 5000
--serve-artifacts
--artifacts-destination s3://my-bucket
--backend-store-uri postgresql://postgres:postgres@backend-store:5432/mlflow
--gunicorn-opts "--log-level debug"
Code to reproduce issue
Commands to run:
$ docker-compose up --build
$ MLFLOW_TRACKING_URI=http://0.0.0.0 MLFLOW_TRACKING_USERNAME=username MLFLOW_TRACKING_PASSWORD=password python example.py
Files needed:
docker-compose.yml
services:
tracking-server:
build:
context: .
dockerfile: Dockerfile
depends_on:
- backend-store
ports:
- "5000:5000"
environment:
MLFLOW_S3_ENDPOINT_URL: http://mlflow-artifacts:9000
AWS_ACCESS_KEY_ID: AKIAIOSFODNN7EXAMPLE
AWS_SECRET_ACCESS_KEY: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
AWS_DEFAULT_REGION: eu-west-2
command: >
mlflow server
--host 0.0.0.0
--port 5000
--serve-artifacts
--artifacts-destination s3://my-bucket
--backend-store-uri postgresql://postgres:postgres@backend-store:5432/mlflow
--gunicorn-opts "--log-level debug"
nginx-proxy:
build:
context: nginx
dockerfile: Dockerfile
depends_on:
- tracking-server
ports:
- "80:80"
backend-store:
image: postgres:12
volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
- postgres_data:/var/lib/postgresql/data/
environment:
POSTGRES_USER: "postgres"
POSTGRES_HOST_AUTH_METHOD: "trust"
mlflow-artifacts:
image: minio/minio:RELEASE.2021-10-08T23-58-24Z.fips
environment:
MINIO_ROOT_USER: AKIAIOSFODNN7EXAMPLE
MINIO_ROOT_PASSWORD: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
MINIO_REGION: eu-west-2
ports:
- "9000:9000"
- "9001:9001"
entrypoint: sh
volumes:
- ".minio:/data"
command: ['-c', 'mkdir -p /data/my-bucket && minio server /data --console-address ":9001"']
volumes:
postgres_data:
minio:
Dockerfile
FROM python:3.7-buster
WORKDIR /app
RUN pip install sklearn mlflow psycopg2 boto3
example.py
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
from mlflow.models.signature import ModelSignature
from mlflow.types.schema import Schema, ColSpec
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
np.random.seed(40)
# Read the wine-quality csv file from the URL
csv_url = (
"http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
)
data = pd.read_csv(csv_url, sep=";")
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
input_schema = Schema([
ColSpec("double", "sepal length (cm)"),
ColSpec("double", "sepal width (cm)"),
ColSpec("double", "petal length (cm)"),
ColSpec("double", "petal width (cm)"),
])
output_schema = Schema([ColSpec("long")])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
mlflow.sklearn.log_model(lr, "model", registered_model_name="ElasticnetWineModel", signature=signature)
init.sql
CREATE DATABASE mlflow;
nginx/Dockerfile
FROM nginx
COPY nginx.conf /etc/nginx/nginx.conf
COPY htpasswd /etc/nginx/conf.d/htpasswd
nginx/htpasswd
username:jRlgfrjACzG6Y
nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
server {
location / {
auth_basic "closed site";
auth_basic_user_file conf.d/htpasswd;
proxy_pass http://tracking-server:5000/;
}
}
}
Other info / logs
No response
What component(s) does this bug affect?
-
area/artifacts: Artifact stores and artifact logging -
area/build: Build and test infrastructure for MLflow -
area/docs: MLflow documentation pages -
area/examples: Example code -
area/model-registry: Model Registry service, APIs, and the fluent client calls for Model Registry -
area/models: MLmodel format, model serialization/deserialization, flavors -
area/pipelines: Pipelines, Pipeline APIs, Pipeline configs, Pipeline Templates -
area/projects: MLproject format, project running backends -
area/scoring: MLflow Model server, model deployment tools, Spark UDFs -
area/server-infra: MLflow Tracking server backend -
area/tracking: Tracking Service, tracking client APIs, autologging
What interface(s) does this bug affect?
-
area/uiux: Front-end, user experience, plotting, JavaScript, JavaScript dev server -
area/docker: Docker use across MLflow’s components, such as MLflow Projects and MLflow Models -
area/sqlalchemy: Use of SQLAlchemy in the Tracking Service or Model Registry -
area/windows: Windows support
What language(s) does this bug affect?
-
language/r: R APIs and clients -
language/java: Java APIs and clients -
language/new: Proposals for new client languages
What integration(s) does this bug affect?
-
integrations/azure: Azure and Azure ML integrations -
integrations/sagemaker: SageMaker integrations -
integrations/databricks: Databricks integrations
Issue Analytics
- State:

- Created a year ago
- Comments:5 (1 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Hi @abbas123456. Great question! I think we can address this by setting the
backend_store_uritof'sqlite:///{os.path.join(tmpdir, "mlruns.db")}'here: https://github.com/mlflow/mlflow/blob/f7b19b8dcacff24ddfa535e7a9808cb51bdf96ea/tests/tracking/test_mlflow_artifacts.py#L52I still have the same problem using MLFlow 1.30.0 and scenario 4.