
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
SLEIGH: assembly template not following the usual mnemonic + operands
See original GitHub issueHello,
I’m trying to add support for the Qualcomm’s Hexagon V5x architecture to Ghidra.
However, I am facing 1 non-blocking and 1 blocking issue:
- Hexagon is a VLIW architecture. It uses instruction packets that contains up to 4 instructions. This is usually represented in assembly using the prefix
{and the suffix}, like so:
Disassembly of section .text:
main:
0: 80 c1 01 b0 b001c180 { r0=add(r1,#12) }
4: 80 41 01 b0 b0014180 { r0=add(r1,#12)
8: 82 c1 03 b0 b003c182 r2=add(r3,#12) }
c: 80 41 01 b0 b0014180 { r0=add(r1,#12)
10: 82 41 03 b0 b0034182 r2=add(r3,#12)
14: 84 c1 05 b0 b005c184 r4=add(r5,#12) }
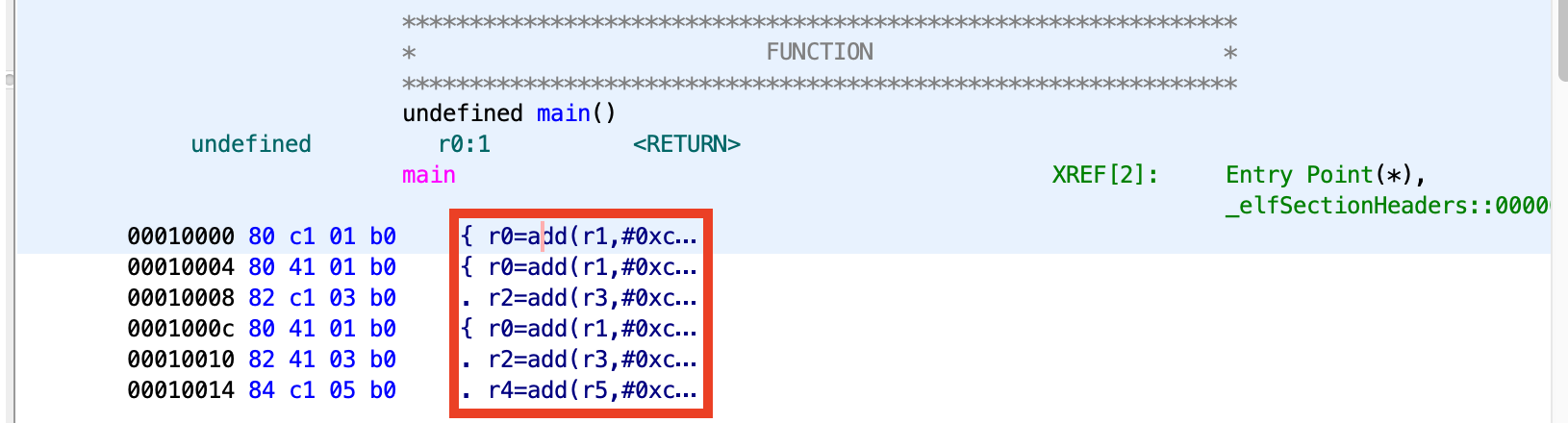
Because Ghidra strips whitespace from the beginning of the display section, I end up with:
00010000 80 c1 01 b0 { r0=add(r1,#0xc) }
00010004 80 41 01 b0 { r0=add(r1,#0xc)
00010008 82 c1 03 b0 r2=add(r3,#0xc) }
0001000c 80 41 01 b0 { r0=add(r1,#0xc)
00010010 82 41 03 b0 r2=add(r3,#0xc)
00010014 84 c1 05 b0 r4=add(r5,#0xc) }
I’ve been using . as a second space character, but while it works it isn’t pretty.
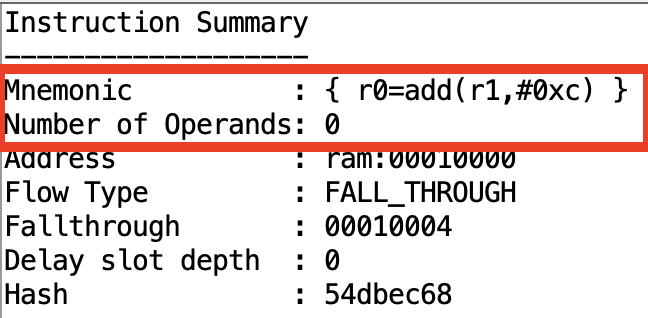
- Because “the first string of characters in the display section […] is treated as the literal mnemonic of the instruction”, I had to prefix the entries of the instruction table with
^. The whole line is now being treated as part of the mnemonic, and the operands are not being recognised.
Is there any solution to these issues? If not, I’m guessing the Sleigh language has to be modified.
For reference, here is my current code:
define register offset=0x1000 size=4 contextreg;
define context contextreg
phase=(0,0) noflow
slot=(1,2)
next_slot=(3,4)
;
define token instr(32)
iclass=(28,31)
si27_21=(21,27) signed
s5=(16,20)
parse=(14,15)
si13_5=(5,13)
d5=(0,4)
;
attach variables [ s5 d5 ] [
r0 r1 r2 r3 r4 r5 r6 r7
r8 r9 r10 r11 r12 r13 r14 r15
r16 r17 r18 r19 r20 r21 r22 r23
r24 r25 r26 r27 r28 sp fp lr
];
calc_slot: is (parse=0b01 | parse=0b10) [ slot=next_slot; next_slot=next_slot+1; globalset(inst_next,next_slot); ] {}
calc_slot: is (parse=0b00 | parse=0b11) [ slot=next_slot; next_slot=0; globalset(inst_next,next_slot); ] {}
prefix:"{ " is slot=0 {}
prefix:". " is slot!=0 {}
suffix:" }" is next_slot=0 {}
suffix:" ." is next_slot!=0 {}
:^prefix^instruction^suffix is phase=0 & calc_slot & prefix & suffix & instruction [ phase=1; ] {}
with: phase=1 {
#
# Instructions
#
:^d5^"=add("^s5^",#"^s16^")" is d5 & s5 & si27_21 & si13_5 [ s16 = (si27_21 << 8) | si13_5; ] {}
}
Issue Analytics
- State:

- Created 4 years ago
- Comments:10 (2 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Creating a Ghidra processor module in SLEIGH using V8 ...
The display section is a template for how to display the instruction into the Ghidra listing. The bit pattern section is a list...
Read more >Table of Branch Instructions
Mnemonic Operands Description signed or unsigned? Mnemonic Operands Description
b label branch beq s,t,label branch if s...
beqz s,label branch if s==0 bge s,t,label branch...
Read more >Chapter 3 Assembly Language Fundamentals
Know how to formulate assembly language instructions, using valid syntax ... operands usually required comment ... example: count (not followed by colon).
Read more >Branching with extended mnemonic codes - IBM
The assembler translates the extended mnemonic code into the mask value, and then assembles it into the object code of the BC, BCR,...
Read more >Assembly Language Programming The PIC18 Microcontroller ...
The operand (s) follows the instruction mnemonic. ... assigned at link time if not specified in the directive. reset code 0x00 ... Assembly...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
I dug a little bit into Ghidra’s source code and I am now certain that fixing the second issue requires major changes to the current architecture. Let me present my findings if anyone is interested:
.slafile generated by the Sleigh compiler and searched for theaddconstructor. I quickly noticed that thefirstattribute was set to 6:So far, so good.
addSyntax()is called for each of the literals. We could replacefirstwhitespacebyfirstmnemonic/nextmnemonicto store the range containing the mnemonic. This range could be defined as the first sequence of literals matching some kind of regular expression.I looked for functions using the
firstwhitespaceattribute, and found two of them:It is evident that the mnemonic is made of the tokens in the range
[0, firstwhitespace[and the body of the tokens in[firstwhitespace, printpiece.size()[. This is problematic because, in our special assembly, most of the times the mnemonic is not at the beginning of the line.printMnemonic()could easily be modified, and it is only called by the following function:printBody()could be split into two functionsprintBodyStart()andprintBodyEnd(). This function is never called. Looking into it a little more, I discovered another class also namedConstructorthat loads the XML element saved by the previous class.I’m guessing the first class is used during the parsing of the
slaspecfile and writing of theslafile, and that the second class is used to read theslafile and make use of it (parse a binary). In any case, this class also implements similar methods, plus another one:printSeparator()function, I found the same class yet again:getSeparator()function yielded many results:ghidra/program/database/code/InstructionDB.javaghidra/app/util/viewer/field/OperandFieldHelper.javaghidra/app/plugin/core/searchtext/databasesearcher/InstructionMOFS.javaSo now I am left wondering if I should make any modifications at all. I definitively could us some advice from the main developers on wether or not it is a good idea to implement those changes, and if they would be willing to merge these hypothetical changes in the next release. Or to make them themselves.
I took a look at the instruction manual for this processor. The processor is quite a beast, and the format of the instructions are somewhat unique. For inserting spaces into the mnemonic for the instructions for the processor, it would at times be useful to insert spaces. I’m not sure it would be useful to insert them at the beginning of the instruction. In theory they could be protected from stripping with some sort of escape sequence (%20). Although that might complicate code using the mnemonic field. The extending of the field is interesting and I actually like this solution better. The code browser was meant for extending with special fields such as the braces you’ve added. You can configure, and save multiple tool configurations with particular plugins or code browser fields set up to work best for a particular use. You mention that overriding the monic/operand fields affects the data display fields (mnemonic and operand), which is true. Currently the code browser field formats have a single format for instructions and data (code unit). These could potentially be split such that the instructions have their own format and data has another. Having these two split could be a detriment for other processors, but might actually be more useful, as data can display much differently that code, with the operand needing more space such as for strings. I’m not sure the ramifications of making this change. We’d need to look into it more closely as the code browser listing is a complicated set of code.