
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[bug] Available IPs on AWS consumed too quickly, limits number of dask-worker nodes that can spin up
See original GitHub issueDescribe the bug
A clear and concise description of what the problem is.
When requesting a large number of dask workers, some fraction of worker pods never spin up. During some reason testing, I requested 250 workers and only got 190 (or so) workers to spin up; 190 (or thereabouts) seems to be the limit of dask workers nodes we can spin up at one time. For the node-group in question, we have set the max number of workers to the default 450 in the qhub-config.yaml.
Checking the status of these nodes on AWS reveals an interesting error message:
runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
How can we help?
Help us help you.
- What are you trying to achieve?
- How can we reproduce the problem?
- What is the expected behaviour?
- And what is currently happening?
- Any error messages?
If helpful, please add any screenshots and relevant links to the description.
Here are a few screenshots of these error messages:

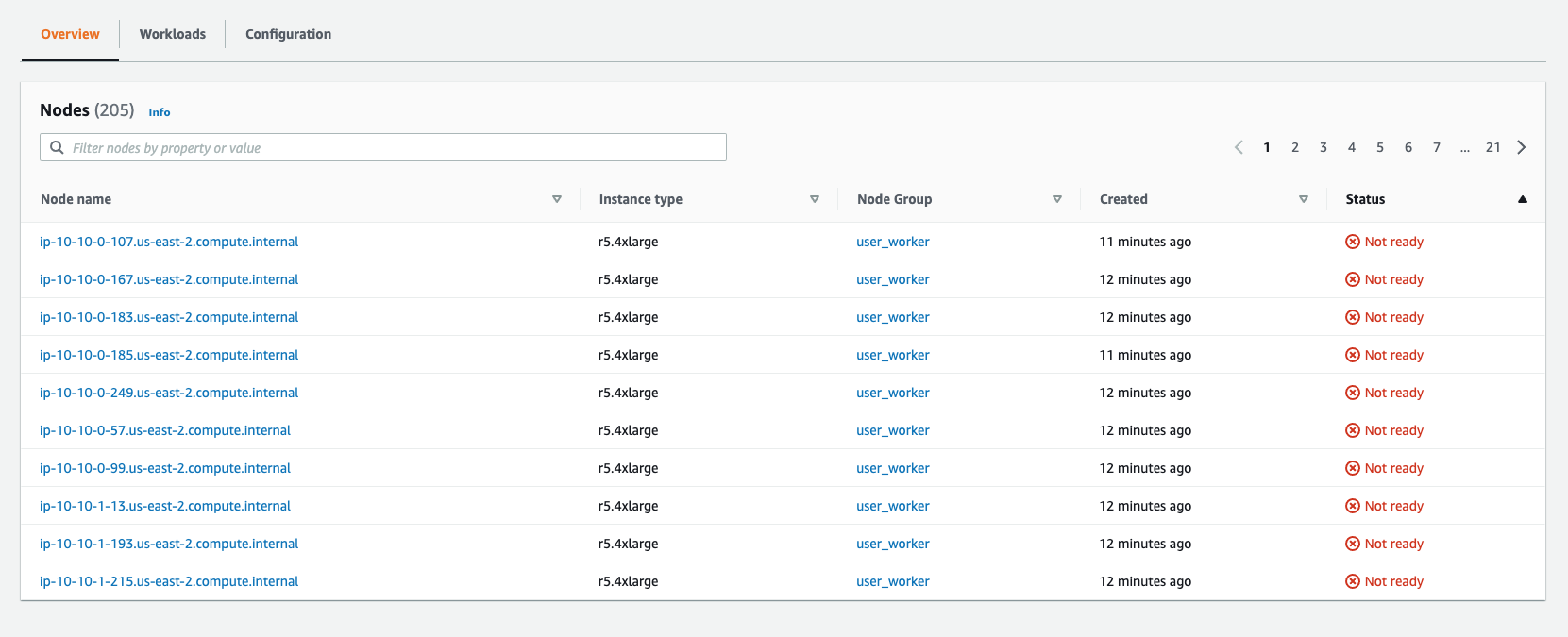
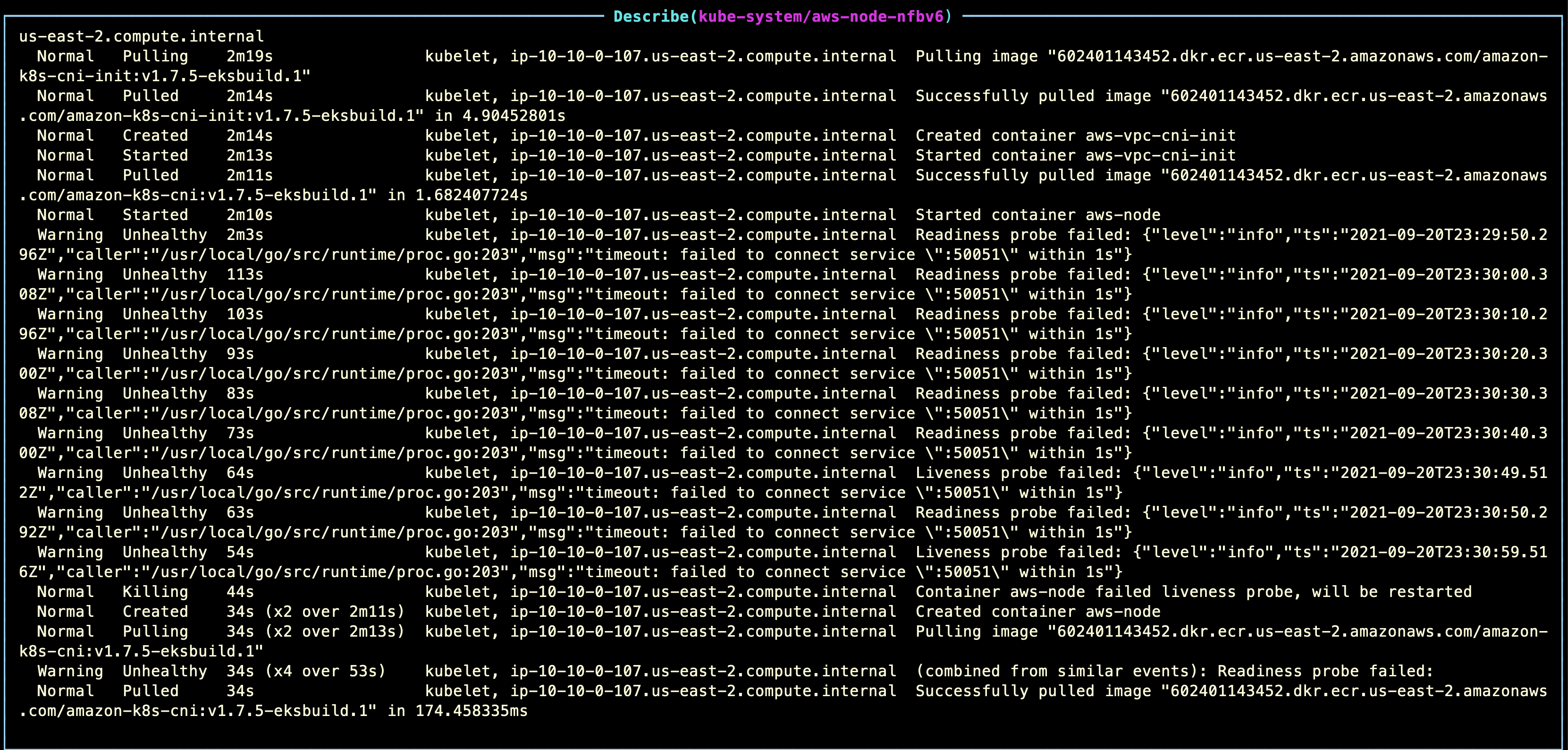
Your environment
Describe the environment in which you are experiencing the bug.
Include your conda version (use
conda --version), k8s and any other relevant details.
qhub - 0.3.12 (installed from commit 0dff706)
k8s - 1.19
Issue Analytics
- State:

- Created 2 years ago
- Comments:12 (12 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@iameskild lets make these vpcs as large as we can then. I see for aws the vpc is “10.10.0.0/16” and thus
2^16 = 65536ips and we reserve the first4bits for the subnets -> thus2^12 = 4096. Instead lets use the entire ip10.0.0.0/8and use4bits for the subnet.The possible solution outlined below is likely overly complicated but I haven’t been able to find a simpler means of updating the
WARM_IP_TARGETenvironment variable found in theaws-nodedaemonset.I believe we are currently using the default
amazon-vpc-cni-k8splugin wherein theWARM_IP_TARGETis not set and the daemonset relies onWARM_ENI_TARGET=1; as mentioned above, this reserves a large pool of IP addresses for each node which is the root of the problem.One possible solution might involve using this Terraform
kubectl provideralong with a “custom” kubernetes manifest/YAML for the daemonset in question. This will give us the option to make any necessary changes to the default AWS CNI settings including updatingWARM_IP_TARGET.This solution assumes that AWS EKS clusters use the
amazon-vpc-cni-k8splugin by default (something the AWS docs seems to suggest) and that we are comfortable using a third-party Terraform provider -kubectl provider. I also must admit that my Terraform knowledge is a bit rudimentary so if this is all non-sense, forgive me haha