
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
unique() needlessly slow
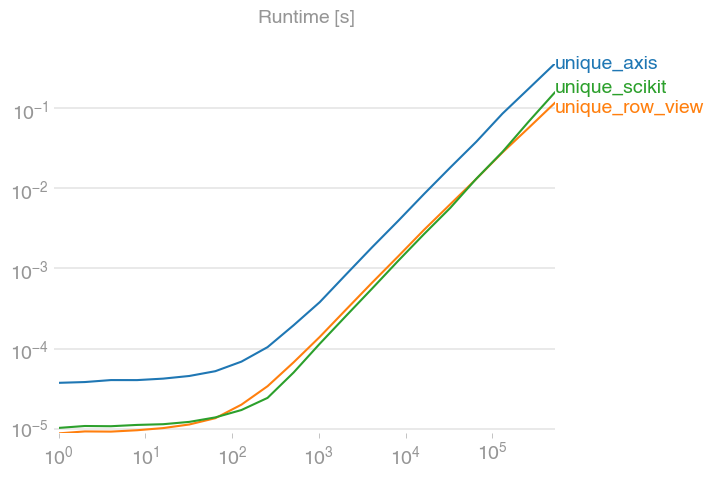
See original GitHub issuenp.unique has the axis option that allows, for example, to call unique on the rows of a matrix. I noticed however that it’s quite slow. Creating a view of the data and calling unique on the view is faster by a factor of 3.
MVCE:
import numpy
import perfplot
def unique_axis(data):
return numpy.unique(data, axis=0)
def unique_row_view(data):
b = numpy.ascontiguousarray(data).view(
numpy.dtype((numpy.void, data.dtype.itemsize * data.shape[1]))
)
u = numpy.unique(b).view(data.dtype).reshape(-1, data.shape[1])
return u
def unique_scikit(ar):
if ar.ndim != 2:
raise ValueError("unique_rows() only makes sense for 2D arrays, "
"got %dd" % ar.ndim)
# the view in the next line only works if the array is C-contiguous
ar = numpy.ascontiguousarray(ar)
# np.unique() finds identical items in a raveled array. To make it
# see each row as a single item, we create a view of each row as a
# byte string of length itemsize times number of columns in `ar`
ar_row_view = ar.view('|S%d' % (ar.itemsize * ar.shape[1]))
_, unique_row_indices = numpy.unique(ar_row_view, return_index=True)
ar_out = ar[unique_row_indices]
return ar_out
perfplot.save(
"unique.png",
setup=lambda n: numpy.random.randint(0, 100, (n, 2)),
kernels=[unique_axis, unique_row_view, unique_scikit],
n_range=[2 ** k for k in range(20)],
)
Issue Analytics
- State:

- Created 5 years ago
- Reactions:2
- Comments:6 (4 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Filtering block plugins by context is slow [#2994550] | Drupal.org
Filtering block plugins by context is slow ... \Context\EntityContextDefinition::getSampleValues() needlessly generates full sample entities ...
Read more >Excel Extract a Unique List - My Online Training Hub
Array formulas can slow workbooks down, especially if the range being referenced is large, or there are lots of these formulas. Remove Duplicate ......
Read more >Numpy Unique slow on a large array... is there any way to ...
I am using the following code to load a numpy array, find unique dates in the first column, and then extract a slice...
Read more >Slow Google Sheets? Here are 27 Ideas to Try Today
How can you speed up a slow Google Sheet? ... I then deleted 99,999 of these formulas and just left TODAY() in cell...
Read more >Redfish requests for dbus-sensors data are needlessly slow
requestRoutesSensor() is called to process the GET request. For further processing a D-Bus call is made. For experimenting on a running ...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
Note that your approach also only works for types where equality ⇔ binary equality, which is not true for floating point numbers.
Here are three more ways:
unique_rowscreates a 1D view (likeunique_row_view), then usespd.uniqueon it.unique_via_pd_drop_duplicatessimply usespd.drop_duplicates.unique_rows_via_pd_internalsuses some internals ofpd.drop_duplicates, in order to avoid creating a DataFrame and other unnecessary operations.Interestingly, compared to
unique_row_view, these methods are only faster for large arrays. In the case ofunique_rows, the relative speedup vanishes when the result is large, i.e. there are not many duplicates).Case 1: Lots of duplicates
BTW, I didn’t know about
perfplot. It is awesome!Case 2: No duplicates
Implementation