
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
calculate WER
See original GitHub issueHi,
Thanks for your great repo. I have 2 questions:
1- In the Nemo repo is there any implemented code for calculating the WER (word error rate) for a data set & model’s transcription? (i.e., I mean for example I want to calculate the WER of a trained model on a test set, which I have its ground truth in a text file. So, is there any script in Nemo that I can use it? or I must use other codes such as: jiwer)
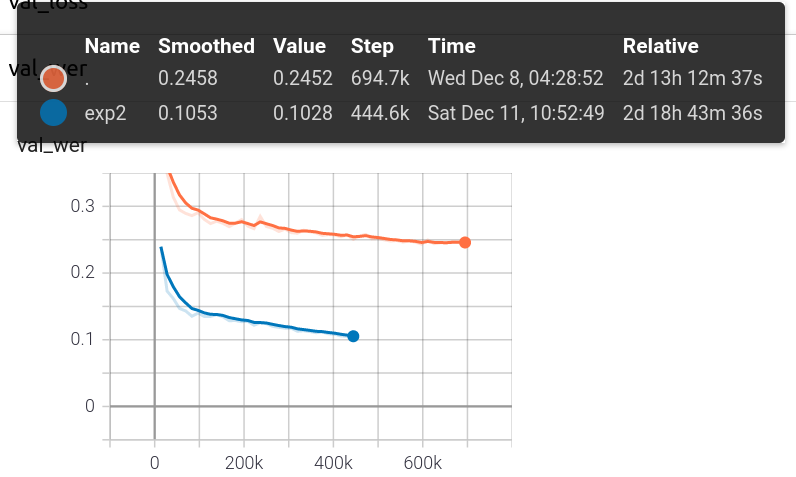
2- In the ASR_CTC_Language_Finetuning tutorial, if one enables use_cer (character error rate) parameter, then the tensor board results will be shown the CER instead of WER? (In other words, I have used the use_cer = True, and for example the tensor board showed me the WER of the trained model on epoch=31 on validation set is ~ 0.1028. Now I want to know that it is really WER or it is CER? and if it is CER, how I can calculate the WER of the model on my validation or test set?)
Best
Issue Analytics
- State:

- Created 2 years ago
- Comments:5
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
For (1), you can use https://github.com/NVIDIA/NeMo/blob/main/examples/asr/transcribe_speech_parallel.py for the time being. We will be refactoring the ASR example scripts in the coming month or two to better support newer model types in a generic way. Or you can use jiwer after computing the transcriptions using the transcribe_speech.py and writing a short script.
For (2), the log name remains the same (*_wer) but in fact it does compute CER and shows the results there. This is obviously confusing, we will improve this to explicitly log CER or WER in the name as well.
If after training, you want to switch batch to wer, you will need to override model._wer.use_cer = False where model is the trained ASR model.
(2) requires config changes + code changes to every single model, which is why it’s a large and breaking change.
We don’t have confidence interval support on our list, not all models can support it and it’s not a frequent use case