
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Generalizing Fuse MatMul and Add into GEMM pass
See original GitHub issueI recently was looking at a graph at work and saw a lot of MatMul + Add operations. Here’s a sample image of what I’m talking about:
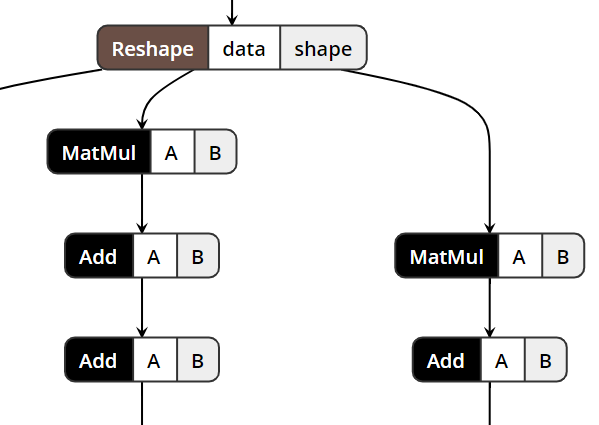
I tried running the new pass @vloncar added but it didn’t work. The shape output of MatMul is float32[32, 100] and the Initializer in Add is float32[100].
Is the pass not applying because of this portion of the code?
if (orig_bias->node()->kind() != kConstant &&
orig_bias->node()->kind() != kParam) {
return false;
}
If so why are we doing this?
Issue Analytics
- State:

- Created 5 years ago
- Comments:8 (8 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Optimizing Matrix Multiplication - CoffeeBeforeArch
GEMM (generalized matrix multiplication) includes the scaling of our A matrix by some constant (alpha), and the addition of the C matrix ...
Read more >cuBLAS - NVIDIA Documentation Center
The cuBLASLt is a lightweight library dedicated to GEneral Matrix-to-matrix Multiply (GEMM) operations with a new flexible API. This library adds ...
Read more >General Matrix Multiply (GeMM) - Spatial
Here we perform matrix multiply on the two tiles by using outer products. The outermost loop here is iterating across the inner, matching...
Read more >Generalized acceleration of matrix multiply accumulate ...
Conventional floating-point units may be designed to implement a fused multiply accumulate (FMA) operation that multiplies two scalar operands and adds the ...
Read more >High-Performance Deep Learning via a Single Building Block
they are hard to maintain and do not generalize. In this work, we introduce the batch-reduce GEMM kernel and show how the most....
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
@houseroad
This is a good segway into having canonicalization in our optimization framework. Before we run any pass we should canonicalize the graph.
I can write a more detailed proposal later, but some basic things to do would be to infer shapes of the model using
shape_inference::InferShapesso we don’t have to rely on the frontend exporters, exporting shape information (most don’t by the way). Some other things that we can do is bubble up cast operators through ShapeTransforms (as defines by OpAnnotationFlag) and that way we could have a more advanced cast fusion optimization (btw which is something I’ll add later).Please note that ONNX optimizer has been moved to another repo https://github.com/onnx/optimizer since ONNX 1.9. If you still have this question, please raise an issue there. Thank you!