
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
compute average training speed and time after training from (.log.json) file.
See original GitHub issueThanks for your error report and we appreciate it a lot.
Checklist
- I have searched related issues but cannot get the expected help. yes
- I have read the FAQ documentation but cannot get the expected help. yes
- The bug has not been fixed in the latest version. yes , as far as i know
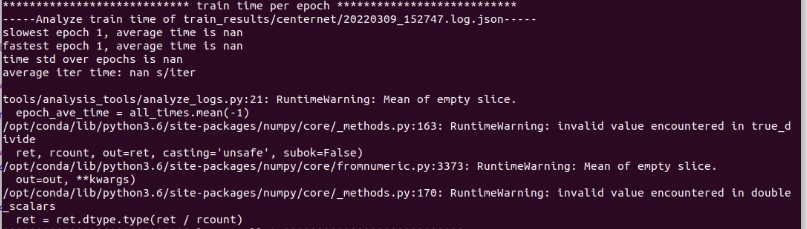
not display correct value for train time ,see bellow image. Describe the bug A clear and concise description of what the bug is.
i am trying to train CenterNet in my own custom dataset ,which has the same format of COCO dataset. i got the results of the training as (.log.json) and got images tested by a desired (epoch.pth) file . but when i try to analysis the training and find the time of training i got a nan value here is the error massage:
Reproduction
- What command or script did you run?
python tools/analysis_tools/analyze_logs.py cal_train_time train_results/centernet/20220309_152747.log.json
- Did you make any modifications on the code or config? Did you understand what you have modified? yes , i made same modification on other models ,for example fasterRCNN , CentriapetalNet , and it works ,and i got the results of training time.
- What dataset did you use? my custom dataset ,with a same format of COCO one.
Environment
- Please run
python mmdet/utils/collect_env.pyto collect necessary environment information and paste it here.
TorchVision: 0.8.0a0 OpenCV: 4.3.0 MMCV: 1.3.8 MMCV Compiler: GCC 7.5 MMCV CUDA Compiler: 11.0 MMDetection: 2.18.1+393c376
- You may add addition that may be helpful for locating the problem, such as
- How you installed PyTorch [e.g., pip, conda, source] it was installed before in the server (GPU) using some docker files.
- Other environment variables that may be related (such as
$PATH,$LD_LIBRARY_PATH,$PYTHONPATH, etc.) i install seaborn using this instructionpip install seabornas the system asked me.
Error traceback If applicable, paste the error trackback here.
tools/analysis_tools/analyze_logs.py:21: RuntimeWarning: Mean of empty slice.
epoch_ave_time = all_times.mean(-1)
/opt/conda/lib/python3.6/site-packages/numpy/core/_methods.py:163: RuntimeWarning: invalid value encountered in true_divide
ret, rcount, out=ret, casting='unsafe', subok=False)
/opt/conda/lib/python3.6/site-packages/numpy/core/fromnumeric.py:3373: RuntimeWarning: Mean of empty slice.
out=out, **kwargs)
/opt/conda/lib/python3.6/site-packages/numpy/core/_methods.py:170: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
A placeholder for trackback.
Bug fix If you have already identified the reason, you can provide the information here. If you are willing to create a PR to fix it, please also leave a comment here and that would be much appreciated!
Issue Analytics
- State:

- Created 2 years ago
- Comments:15
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Yes, I think they are all caused by this reason.
The GPU number is set in the command line. Not displayed in config.