
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Testing mIoU on PASCAL-Context got nan.
See original GitHub issueHi,
I use the below data config.
dataset_type = 'PascalContextDataset'
data_root = '/home/ubuntu/dataset/PASCAL_Context/VOCdevkit/VOC2010/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
img_scale = (520, 520)
crop_size = (480, 480)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=img_scale,
img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=True,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=1,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
The testing result is quite strange.
Class IoU Acc
background 93.85 98.49
aeroplane 88.95 91.85
bicycle 63.43 81.58
bird 88.93 92.60
boat 69.97 72.82
bottle 75.46 89.79
bus 84.96 87.64
car 82.18 84.16
cat 86.61 94.48
chair 24.36 30.57
cow 87.53 93.38
table 46.55 50.18
dog 80.99 90.12
horse 82.93 85.69
motorbike 82.89 91.69
person 83.98 91.55
pottedplant 51.72 57.72
sheep 81.93 83.15
sofa 40.73 47.11
train 80.45 81.60
tvmonitor 66.43 72.46
bag nan nan
bed nan nan
bench nan nan
book nan nan
building nan nan
cabinet nan nan
ceiling nan nan
cloth nan nan
computer nan nan
cup nan nan
door nan nan
fence nan nan
floor nan nan
flower nan nan
food nan nan
grass nan nan
ground nan nan
keyboard nan nan
light nan nan
mountain nan nan
mouse nan nan
curtain nan nan
platform nan nan
sign nan nan
plate nan nan
road nan nan
rock nan nan
shelves nan nan
sidewalk nan nan
sky nan nan
snow nan nan
bedclothes nan nan
track nan nan
tree nan nan
truck nan nan
wall nan nan
water nan nan
window nan nan
wood nan nan
Summary:
Scope mIoU mAcc aAcc
global 73.56 79.46 94.18
Could you help me figure it out? Many thanks!
Issue Analytics
- State:

- Created 3 years ago
- Comments:5
 Top Results From Across the Web
Top Results From Across the Web
mmseg.apis — MMSegmentation 0.29.1 documentation
This method tests model with multiple gpus and collects the results under two ... In segmentation map annotation for PascalContext, 0 stands for...
Read more >Supplementary to GroupViT: Semantic Segmentation ...
PASCAL Context dataset annotates not only object classes from PASCAL VOC 2012, e.g. car and dog, ... We find that the mIoU of...
Read more >Deep High-Resolution Representation Learning for ... - arXiv
state-of-the-art results on PASCAL-Context, Cityscapes, and ... gets detection performance improvement and in particular ... SS-NAN [183]. ResNet-101.
Read more >PASCAL Context Dataset - Papers With Code
The PASCAL Context dataset is an extension of the PASCAL VOC 2010 detection challenge, and it contains pixel-wise labels for all training images....
Read more >Deep High-Resolution Representation Learning for Visual ...
state-of-the-art results on PASCAL-Context, Cityscapes, and ... gets detection performance improvement and in particular ... SS-NAN [146]. ResNet-101.
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
I guess you used the wrong parameter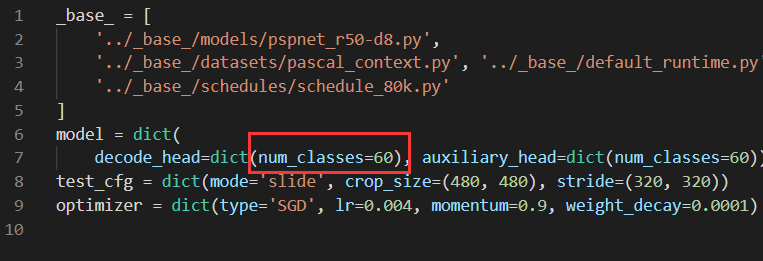
num_classes, please check if your network parameters are correct.hi, @fangruizhu ,I have the same problem, has your problem been solved?